Optimized Python IPC: Uses shared memory to bypass multiprocessing queue I/O bottlenecks, ideal for large data (1MB+) in scientific computing, RL, etc. Reduces system load and improves latency consistency

Project description
py-sharedmemory: High-Performance Multiprocessing Queue Alternative for Large Data

Install using:
pip install py-sharedmemory
Python's standard multiprocessing.Queue pickles data for inter-process communication. This often creates performance bottlenecks in demanding applications like Deep Reinforcement Learning (DeepRL) training, scientific computing, or distributed systems that handle large data objects (e.g., NumPy arrays, tensors >1MB) or involve high I/O volumes between many processes (like actors, replay buffers, and trainers).
py-sharedmemory offers a high-performance replacement. It bypasses pickling by converting data into bytes and moving them into shared memory. Only minimal metadata is sent via the standard queue mechanism. This significantly reduces serialization overhead and inter-process I/O, drastically improving data transfer throughput for data-intensive Python multiprocessing tasks. If your application struggles with slow multiprocessing.Queue performance due to large object transfers, py-sharedmemory provides a faster alternative.
Usage example
import multiprocessing as mp
from memory import create_shared_memory_pair, SharedMemorySender, SharedMemoryReceiver
def producer_sm(sender:SharedMemorySender):
your_data = "your data"
sender.put(your_data) # blocks until there is space
# ...
# or
if sender.has_space():
sender.put(your_data)
# ...
sender.wait_for_all_ack() # wait for all data to be received before closing the sender
# ...
def consumer_sm(receiver:SharedMemoryReceiver, loops, size):
data = receiver.get() # blocks
# ...
# or
data = receiver.get(timeout=3) # raises queue.Empty exception after 3s
# ...
# or
data = receiver.get_nowait()
if data is None:
# handle empty case
# ...
if __name__ == '__main__':
sender, receiver = create_shared_memory_pair(capacity=5)
mp.Process(target=producer_sm, args=(sender,)).start()
mp.Process(target=consumer_sm, args=(receiver,)).start()
Supported Types
The following data types are currently supported:
- bytes
- int
- float
- bool
- str
- np.ndarray
- np.dtype
As well as any nested structures of the following types:
- tuple/NamedTuple
- list
- dict
- set
Explanation
Let's assume I have the following data:
my_data = {
"idx": 12345,
"source": "actor_3",
"data_batch": np.zeros((64, 80, 4, 84, 84, 3), dtype=np.float32)
}
This object uses about ~1.7GB of RAM. Considering a bigger application with multiple processes generating, storing, providing and processing data, the total amount of inter-process I/O is quickly in the hundreds of GB/s. This is demanding on the system.
Using py-sharedmemory the data is instead moved into the system shared memory, which is accessible from other processes using a key. The information transferred via standard multiprocessing queues is reduced to this meta-data used for accessing and reconstructing the object:
(
'wnsm_1adcf1aa', # shared memory key
'd', 1734082569, # total byte size
<class 'dict'>, [ # data structure information
('i', 2, False),
('s', 7),
('n', 1734082560, dtype('float32'), (64, 80, 4, 84, 84, 3))
], ['idx', 'source', 'data_batch']
)
Large example
Assuming this is your data object:
from typing import NamedTuple
class TestNamedTuple(NamedTuple):
name: str
value: int
extensive_test_data = {
"test_id": 98765,
"description": "This is a comprehensive test data object.",
"is_active": True,
"parameters": {
"learning_rate": 0.001,
"batch_size": 128,
"optimizer": "adam",
"epsilon": 1e-8,
"byte_config": b'\x01\x02\x03\x04'
},
"data_samples": [
{
"sample_idx": 0,
"image_data": np.random.rand(32, 32, 3).astype(np.float32),
"label": 10,
"confidence": 0.95,
"flags": [True, False, True],
"metadata": ("image", "png", 32, 32)
},
{
"sample_idx": 1,
"image_data": np.zeros((16, 16, 1), dtype=np.uint8),
"label": 5,
"confidence": 0.88,
"flags": [False, False, True],
"metadata": ("image", "jpeg", 16, 16)
}
],
"settings_list": [
100,
"high",
False,
0.5,
b'setting_bytes',
(1, 'a', True),
{'nested_list_dict': [1, 2, {'deep_key': 'deep_value'}]},
np.array([1.1, 2.2, 3.3])
],
"unique_identifiers": {101, 202, 303, 101},
"status_codes": set([b'success', b'pending', b'failed']),
"data_types_used": [
np.dtype('float32'),
np.dtype('int64'),
np.dtype('uint8'),
np.dtype('bool_')
],
"complex_nested_structure": {
"level1_dict": {
"level2_list": [
"string_in_list",
12345,
True,
(10, 20, 30),
{"level3_dict": {"array_in_dict": np.arange(5)}},
TestNamedTuple(name='example', value=99)
],
"level2_set": {9, 8, 7, "set_string"},
"level2_tuple": (
"tuple_item_1",
56.78,
b'tuple_bytes',
[1, 2, 3],
{"nested_in_tuple": "hello"}
)
}
},
"empty_structures": {
"empty_list": [],
"empty_dict": {},
"empty_set": set(),
"empty_tuple": ()
},
"large_array_example": np.random.rand(64, 80, 4, 84, 84, 3).astype(np.float32)
}
Then the meta-data produced for this object is this:
('wnsm_eb8850c8', 'd', 1734095454, <class 'dict'>, [('i', 3, False), ('s', 41), ('b', 1), ('d', 26, <class 'dict'>, [('f', 8), ('i', 2, False), ('s', 4), ('f', 8), ('r', 4)], ['learning_rate', 'batch_size', 'optimizer', 'epsilon', 'byte_config']), ('l', 12591, <class 'list'>, [('d', 12311, <class 'dict'>, [('i', 1, False), ('n', 12288, dtype('float32'), (32, 32, 3)), ('i', 1, False), ('f', 8), ('l', 3, <class 'list'>, [('b', 1), ('b', 1), ('b', 1)]), ('p', 10, <class 'tuple'>, [('s', 5), ('s', 3), ('i', 1, False), ('i', 1, False)])], ['sample_idx', 'image_data', 'label', 'confidence', 'flags', 'metadata']), ('d', 280, <class 'dict'>, [('i', 1, False), ('n', 256, dtype('uint8'), (16, 16, 1)), ('i', 1, False), ('f', 8), ('l', 3, <class 'list'>, [('b', 1), ('b', 1), ('b', 1)]), ('p', 11, <class 'tuple'>, [('s', 5), ('s', 4), ('i', 1, False), ('i', 1, False)])], ['sample_idx', 'image_data', 'label', 'confidence', 'flags', 'metadata'])]), ('l', 66, <class 'list'>, [('i', 1, False), ('s', 4), ('b', 1), ('f', 8), ('r', 13), ('p', 3, <class 'tuple'>, [('i', 1, False), ('s', 1), ('b', 1)]), ('d', 12, <class 'dict'>, [('l', 12, <class 'list'>, [('i', 1, False), ('i', 1, False), ('d', 10, <class 'dict'>, [('s', 10)], ['deep_key'])])], ['nested_list_dict']), ('n', 24, dtype('float64'), (3,))]), ('u', 5, <class 'set'>, [('i', 2, False), ('i', 1, False), ('i', 2, False)]), ('u', 20, <class 'set'>, [('r', 6), ('r', 7), ('r', 7)]), ('l', 21, <class 'list'>, [('t', 7), ('t', 5), ('t', 5), ('t', 4)]), ('d', 120, <class 'dict'>, [('d', 120, <class 'dict'>, [('l', 68, <class 'list'>, [('s', 14), ('i', 2, False), ('b', 1), ('p', 3, <class 'tuple'>, [('i', 1, False), ('i', 1, False), ('i', 1, False)]), ('d', 40, <class 'dict'>, [('d', 40, <class 'dict'>, [('n', 40, dtype('int64'), (5,))], ['array_in_dict'])], ['level3_dict']), ('p', 8, <class '__main__.TestNamedTuple'>, [('s', 7), ('i', 1, False)])]), ('u', 13, <class 'set'>, [('i', 1, False), ('s', 10), ('i', 1, False), ('i', 1, False)]), ('p', 39, <class 'tuple'>, [('s', 12), ('f', 8), ('r', 11), ('l', 3, <class 'list'>, [('i', 1, False), ('i', 1, False), ('i', 1, False)]), ('d', 5, <class 'dict'>, [('s', 5)], ['nested_in_tuple'])])], ['level2_list', 'level2_set', 'level2_tuple'])], ['level1_dict']), ('d', 0, <class 'dict'>, [('l', 0, <class 'list'>, []), ('d', 0, <class 'dict'>, [], []), ('u', 0, <class 'set'>, []), ('p', 0, <class 'tuple'>, [])], ['empty_list', 'empty_dict', 'empty_set', 'empty_tuple']), ('n', 1734082560, dtype('float32'), (64, 80, 4, 84, 84, 3))], ['test_id', 'description', 'is_active', 'parameters', 'data_samples', 'settings_list', 'unique_identifiers', 'status_codes', 'data_types_used', 'complex_nested_structure', 'empty_structures', 'large_array_example'])
Considerations
There is a certain overhead to the conversion process which is especially noticable for smaller objects and more complex data structures. Use the following heuristic depending on the size of the data you are handling:
| 10B | 100B | 1KB | 10KB | 100KB | 1MB | 10MB | 100MB | 1GB | 10GB | |
|---|---|---|---|---|---|---|---|---|---|---|
mp.Queue() |
✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
py-sharedmemory |
❌ | ❌ | ❌ | ❌ | ❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Actual performance heavily relies on your memory speed.
Performance Testing
I measured the time it takes to send/receive data comparing the standard queue and this shared memory implementation:
Note: The standard queue implementation uses a sender thread, that is why the dark blue bar for 'standard send' apparently has more throughput, since it took less time for each cycle, but the actual time until the data is transfered is longer behind the scenes, making this comparison only somewhat useful.
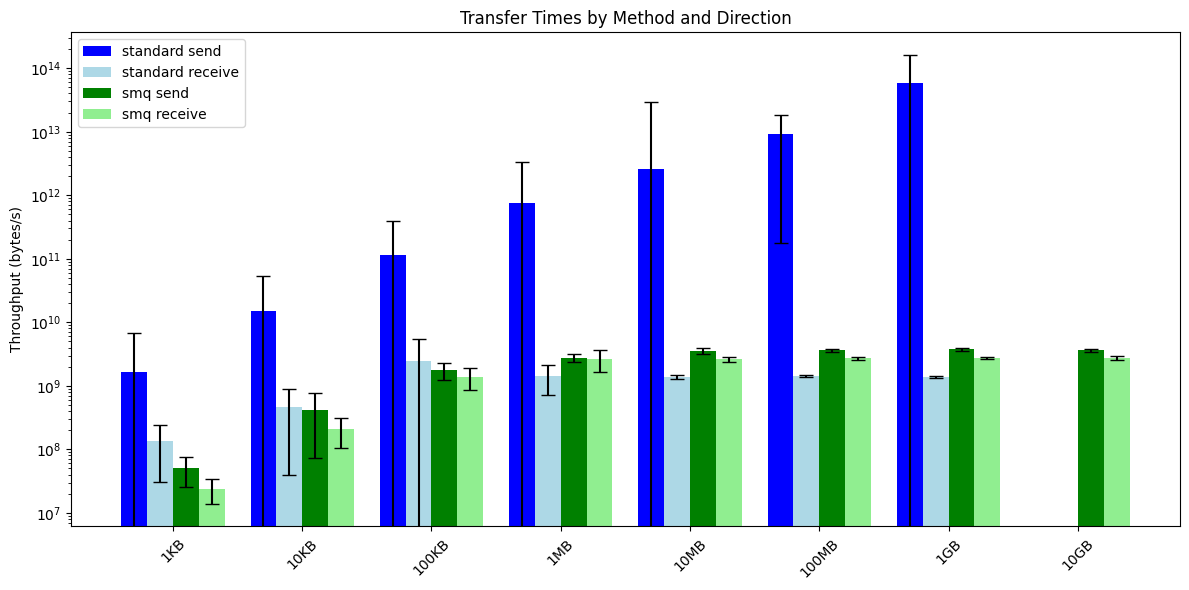
What we can see here is that starting at around 1MB sized packages, my py-sharedmemory implementation starts to outperform the standard implementation.
Furthermore, and this is most importantly, no I/O is produced. Also, the standard implementation crashes for 10GB packages.
Generally I noticed that my system runs much more smoothly and stable when using py-sharedmemory with consistent put/get durations and no application slowdowns, when comparing to the standard implementation.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters







