Python Package for Cross Validation

Project description

pycv: Python Cross Validation Library
The Python Cross Validation Library (pycv) assembles a set of cross validation methods to mitigate dataset shift.
Dataset shift corresponds to a scenario where the training and test sets have different distributions and encompass several representations (i.e., covariate shift, prior probability shift, concept shift, internal covariate shift). An example of dataset shift (namely covariate shift) is depicted in Figure 1, where one class concentrates low feature values in training and high feature values in testing.
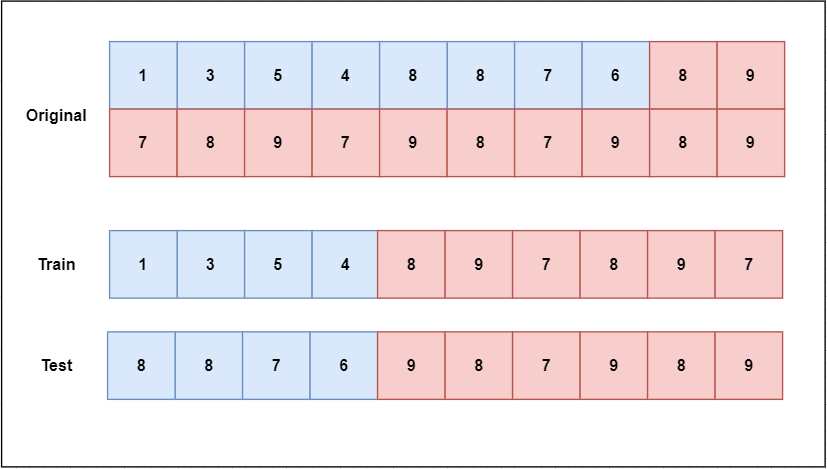
Cross validation (CV) is a common method to split a dataset into different training and testing partitions. Nonetheless, the standard CV can induce dataset shift in this division. Other CV variants try to overcome this by splitting the data more carefully. Despite this, to our knowledge, there is no package that implements these methods in a ready-to-use fashion. As a result, many works use the most basic type of CV, which can induce a shift in the data and lead to unreliable results.
To mitigate this gap, the (pycv) library currently includes 4 Cross Validation Algorithms aimed at mitigating dataset shift: SCV, DBSCV, DOBSCV and MSSCV
SCV
SCV is an improvement over the basic CV which guarantees that the training and testing sets have the same percentages of samples per class as in the original dataset so that the prior probability shift is avoided, however this algorithm does not actively mitigate covariate shift.
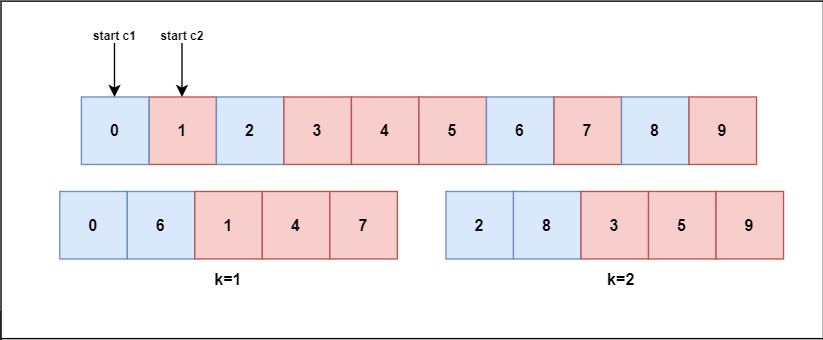
DBSCV
Introduced in [1], DBSCV is a CV variant for addressing covariate shift. This method attempts to separate the data into folds by attributing to each fold a similar observation to the one attributed to a previous fold (Figure 2). In such a way, the distribution of each fold will be more similar when compared to SCV.
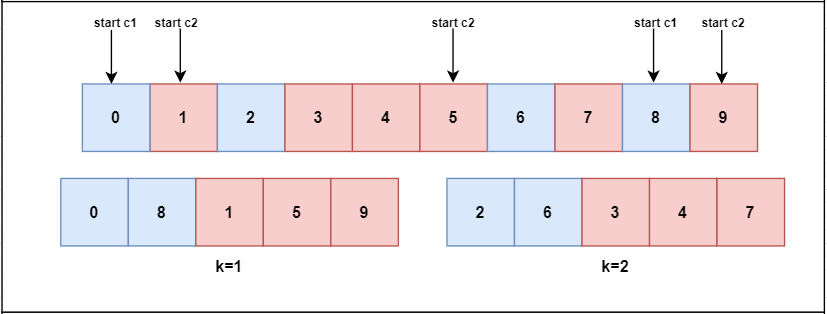
DOBSCV
DOBSCV is an optimized version of DBSCV proposed in [2]. While both algorithms are similar in their goal to reduce covariate shift by distributing samples of the same class as evenly as possible between folds, DOBSCV is less sensitive to random choices since, after assigning a sample to each of the $k$ folds, it picks a new random sample to restart the process (Figure 3).
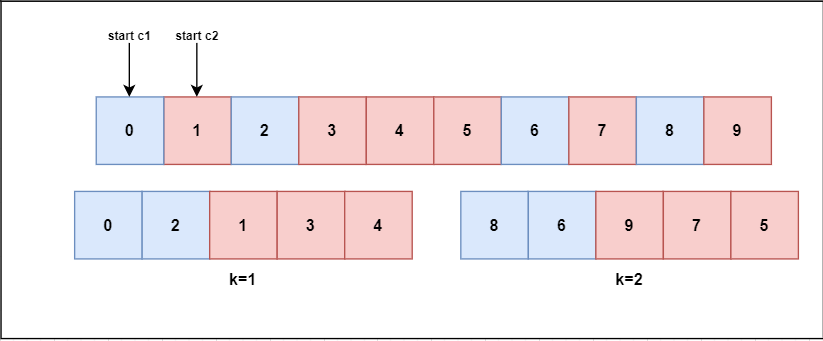
MSSCV
MSSCV can be considered a baseline [2], corresponding to the opposite version of DBSCV. Instead of assigning the closest sample to the next fold, it assigns the most distant (Figure 4). Each fold will be as different as possible, which may cause an increase in covariate shift but also provide more variability of samples.
Usage Example:
The originalDatasets folder contains some datasets with binary problems. The CrossValidation.py module implements the CrossValidation algorithms.
To run the cross validation algorithms, the CrossValidation class is instantiated and the results may be obtained as follows:
from pycv_crossvalidation import CrossValidation
CV = CrossValidation.CrossValidation("originalDatasets/61_iris.arff",distance_func="default",file_type="arff")
#Partition the dataset using SCV
SCV_folds,SCV_folds_y,SCV_folds_inx=CV.SCV(foldNum=5)
#Partition the dataset using DBSCV
DBSCV_folds,DBSCV_folds_y,DBSCV_folds_inx=CV.DBSCV(foldNum=5)
#Partition the dataset using MSSCV
MSSCV_folds,MSSCV_folds_y,MSSCV_folds_inx=CV.MSSCV(foldNum=5)
#Partition the dataset using DOBSCV
DOBSCV_folds,DOBSCV_folds_y,DOBSCV_folds_inx=CV.DOBSCV(foldNum=5)
#Write the partitions into arff files
CV.write_folds(SCV_folds,SCV_folds_y,"abalone_3_vs_11-SCV","test_CV/")
CV.write_folds(DBSCV_folds,DBSCV_folds_y,"abalone_3_vs_11-DBSCV","test_CV/")
CV.write_folds(MSSCV_folds,MSSCV_folds_y,"abalone_3_vs_11-MSSCV","test_CV/")
CV.write_folds(DOBSCV_folds,DOBSCV_folds_y,"abalone_3_vs_11-DOBSCV","test_CV/")
Developer notes:
To submit bugs and feature requests, report at project issues.
Licence:
The project is licensed under the MIT License - see the License file for details.
References:
[1] Xinchuan Zeng and Tony R. Martinez. Distribution-balanced stratified cross-validation for accuracy estimation. Journal of Experimental & Theoretical Artificial Intelligence, 12(1):1–12, 2000. doi: 10.1080/095281300146272. URL https://doi.org/10.1080/095281300146272.
[2] Jose Garc ́ıa Moreno-Torres, Jos ́e A. Saez, and Francisco Herrera. Study on the impact of partition-induced dataset shift on k-fold cross-validation. IEEE Transactions on Neural Networks and Learning Systems, 23(8):1304–1312, 2012b. doi: 10.1109/TNNLS.2012.2199516.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pycv_crossvalidation-0.0.3.tar.gz.
File metadata
- Download URL: pycv_crossvalidation-0.0.3.tar.gz
- Upload date:
- Size: 11.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.10.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f60b7ea4d0906406f41b32d97549475b152f72c4e170f9546febe401fafa2b89
|
|
| MD5 |
fbf4ec33c0e036775550bdc72601d05c
|
|
| BLAKE2b-256 |
16936a038a0618659cf64bd1e36ec59eaecc0cef4bc10093b68ca455c0ef6ca1
|
File details
Details for the file pycv_crossvalidation-0.0.3-py3-none-any.whl.
File metadata
- Download URL: pycv_crossvalidation-0.0.3-py3-none-any.whl
- Upload date:
- Size: 10.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.10.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4a56c70a02997e0d9e6a5d01e5e3e8d7a09042424d404285d3e94a6ae1bfca3d
|
|
| MD5 |
5aee4b3c3fbdfc03331c9d5d320fcd73
|
|
| BLAKE2b-256 |
bbdee70cff9275f21ba132b4575d275bb5b9c758d4243e9e084926069d858a40
|







