PyDGC: A Deep Graph Clustering Benchmark

Project description

PyDGC
PyDGC, a flexible and extensible Python library for deep graph clustering (DGC), is compatible with frameworks such as PyG and OGB. It supports the easy integration of new models and datasets, facilitating the rapid development, reproduction, and fair comparison of DGC methods.
News
- 2025.05: Release source code of PyDGC.
What is DGC?
Deep graph clustering, which aims to reveal the underlying graph structure and divide the nodes into different groups, has attracted intensive attention in recent years.
More details can be found in the survey paper. Please click here to view the comprehensive archive of papers.
Timeline of representative models.
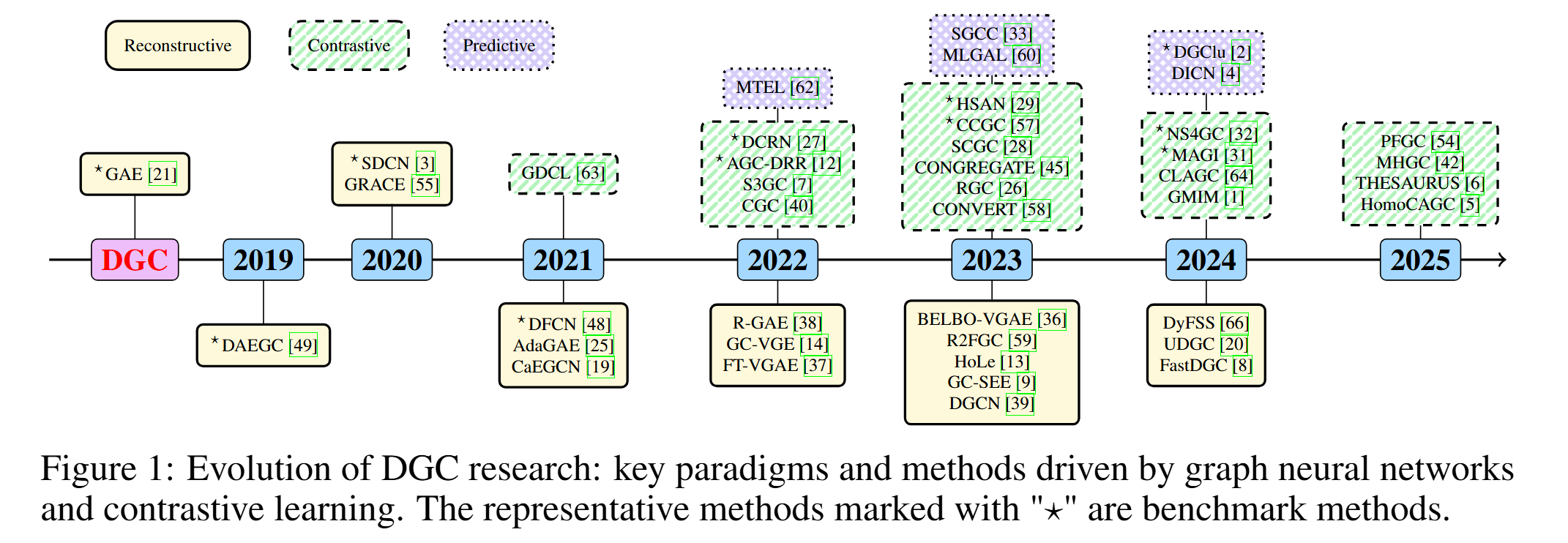
DGCBench
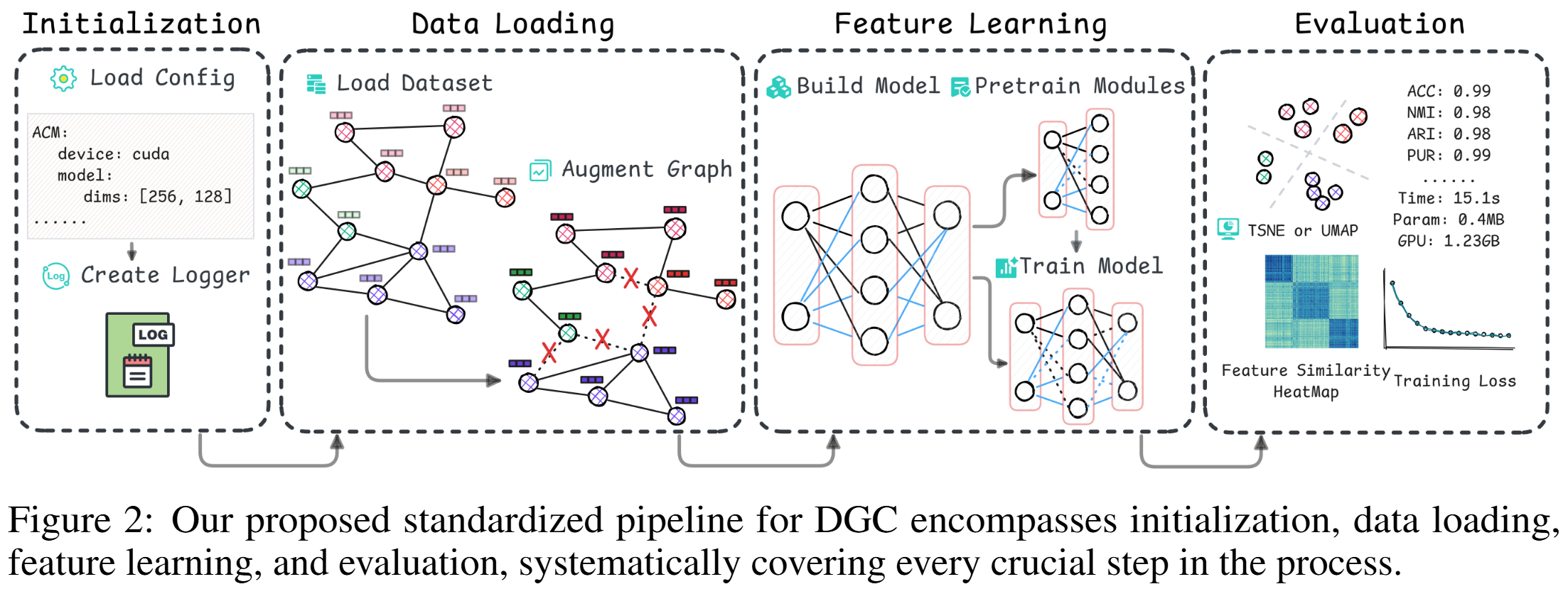
DGCBench encompasses 12 diverse datasets with different characteristics and 12 state-of-the-art methods from all major paradigms. By integrating them into a standardized pipeline, we ensure fair, reproducible, and comprehensive evaluations across multiple dimensions.
Features
- Integration of multiple deep graph clustering models. Supported Models
- Support for various graph datasets from PyG and OGB. Supported Datasets
- Model evaluation and visualization capabilities.
- Standardized Pipeline.
Overview of Pipeline
Installation
-
Install with Pip
coming soon...
-
Installation for local development
git clone https://github.com/Marigoldwu/PyDGC.git cd PyDGC pip install -e .
Examples
Reproduce built-in models
Take GAE as an example:
cd PyDGC/example/pipelines/gae
python run.py
You can also specify arguments in the command line:
python run.py --dataset_name CORA -eval_each
Other optional arguments:
--cfg_file_path YourPath # path of corresponding configurations file
--flag FlagContent # Descriptions
--drop_edge float # probability of dropping edges
--drop_feature float # probability of dropping features
--add_edge float # probability of adding edges
--add_noise float # standard deviation of Gaussian Noise
-pretrain # only run the pretraining stage in the model
Develop your own DGC model
from pydgc.models import DGCModel
class MyModel(DGCModel):
def __init__(self, logger, cfg):
super(MyModel).__init__(logger, cfg)
your_model = ... # Your model
self.loss_curve = []
self.nmi_curve = []
self.best_embedding = None
self.best_predicted_labels = None
self.best_results = {'ACC': -1}
def forward(self, data):
... # forward process
return something
# If needed
def loss(self, *args, **kwargs):
# If needed
def pretrain(self, data, cfg, flag):
def train_model(self, data, cfg, flag):
def get_embedding(self, data):
def clustering(self, data):
embedding = self.get_embedding(data)
# clustering
return embedding, labels_, clustering_centers
def evaluate(self, data):
embedding, predicted_labels, clustering_centers = self.clustering(data)
ground_truth = data.y.numpy()
metric = DGCMetric(ground_truth, predicted_labels.numpy(), embedding, data.edge_index)
results = metric.evaluate_one_epoch(self.logger, self.cfg.evaluate)
return embedding, predicted_labels, results
Develop your own DGC pipeline
from pydgc.pipelines import BasePipeline
from pydgc.utils import perturb_data
import MyModel # import your own model
class MyPipeline(BasePipeline):
def __init__(self, args):
super(MyPipeline).__init__(args)
def augmentation(self):
self.data = perturb_data(self.data, self.cfg.dataset.augmentation)
# other augmentations if needed
def build_model(self):
model = MyModel(self.logger, self.cfg)
self.logger.model_info(model)
return model
Supported Models
Supported Datasets
| No. | Dataset | #Samples | #Features | #Edges | #Classes | Homo. Ratio |
|---|---|---|---|---|---|---|
| 1 | Wiki | 2,405 | 4,973 | 17,981 | 17 | 0.71 |
| 2 | Cora | 2,708 | 1,433 | 5,429 | 7 | 0.81 |
| 3 | ACM | 3,025 | 1,870 | 13,128 | 3 | 0.82 |
| 4 | Citeseer | 3,327 | 3,703 | 9,104 | 6 | 0.74 |
| 5 | DBLP | 4,057 | 334 | 3,528 | 4 | 0.80 |
| 6 | PubMed | 19,717 | 500 | 88,648 | 3 | 0.80 |
| 7 | Ogbn-arXiv | 169,343 | 128 | 2,315,598 | 40 | 0.65 |
| 8 | USPS(3NN) | 9,298 | 256 | 27,894 | 10 | 0.98 |
| 9 | HHAR(3NN) | 10,299 | 561 | 30,897 | 6 | 0.95 |
| 10 | BlogCatalog | 5,196 | 8,189 | 343,486 | 6 | 0.40 |
| 11 | Flickr | 7,575 | 12,047 | 479,476 | 9 | 0.24 |
| 12 | Roman-empire | 22,662 | 300 | 65,854 | 18 | 0.05 |
More Datasets will be introduced.
Citation
Related Repositories
ADGC: Awesome-Deep-Graph-Clustering
Older version of this repository: A-Unified-Framework-for-Attribute-Graph-Clustering


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pydgc-1.0.1.tar.gz.
File metadata
- Download URL: pydgc-1.0.1.tar.gz
- Upload date:
- Size: 64.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.8.20
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
946b841010a436c807bf09e9391f646f27b0aa54fd7b120072fc5b21bb8f6cb1
|
|
| MD5 |
a154c826d4cb1c19c4719d5b6cffff5f
|
|
| BLAKE2b-256 |
7a6f2c021a6d56e563e1eb1229070f5b276cce8249a3a31ce2bf47d4490d6f67
|
File details
Details for the file pydgc-1.0.1-py3-none-any.whl.
File metadata
- Download URL: pydgc-1.0.1-py3-none-any.whl
- Upload date:
- Size: 93.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.8.20
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
808245f5c0c7f4215fda0a291d8e6e258b10681093b3d63fe78320f843b8c865
|
|
| MD5 |
9b102091f25fa3b99e151c8d0fb99187
|
|
| BLAKE2b-256 |
ff9acd03d01ae1e0b44bba240b2bcdb0994cd3107d37da2ef7413e69b6b59672
|







