A genome visualization python package for comparative genomics

Project description
pyGenomeViz






Table of contents
Overview
pyGenomeViz is a genome visualization python package for comparative genomics implemented based on matplotlib. This package is developed for the purpose of easily and beautifully plotting genomic features and sequence similarity comparison links between multiple genomes. It supports genome visualization of Genbank format file from both API & CLI, and can be saved figure in various formats (JPG/PNG/SVG/PDF). User can use pyGenomeViz for interactive genome visualization figure plotting on jupyter notebook, or automatic genome visualization figure plotting in genome analysis scripts/pipelines.
For more information, please see full documentation here.
Fig.1 Four Erwinia phage genome comparison result
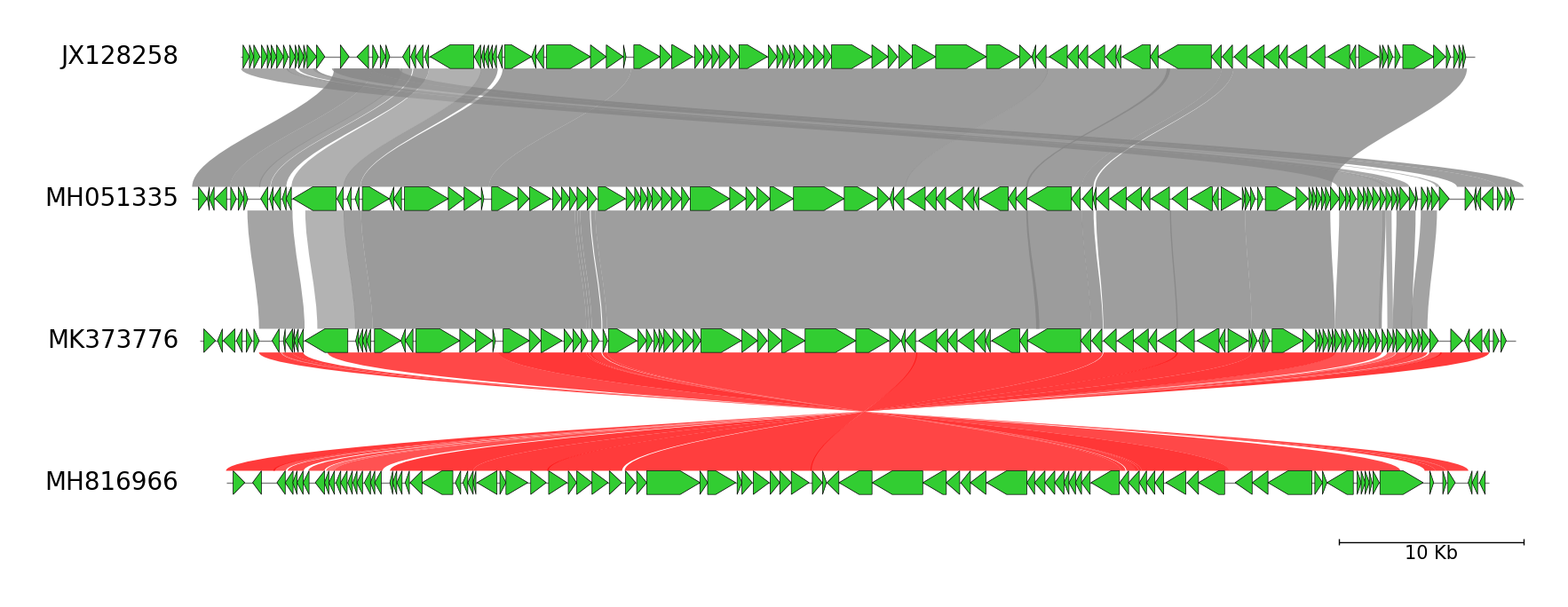
Fig.2 Six Enterobacteria phage genome comparison
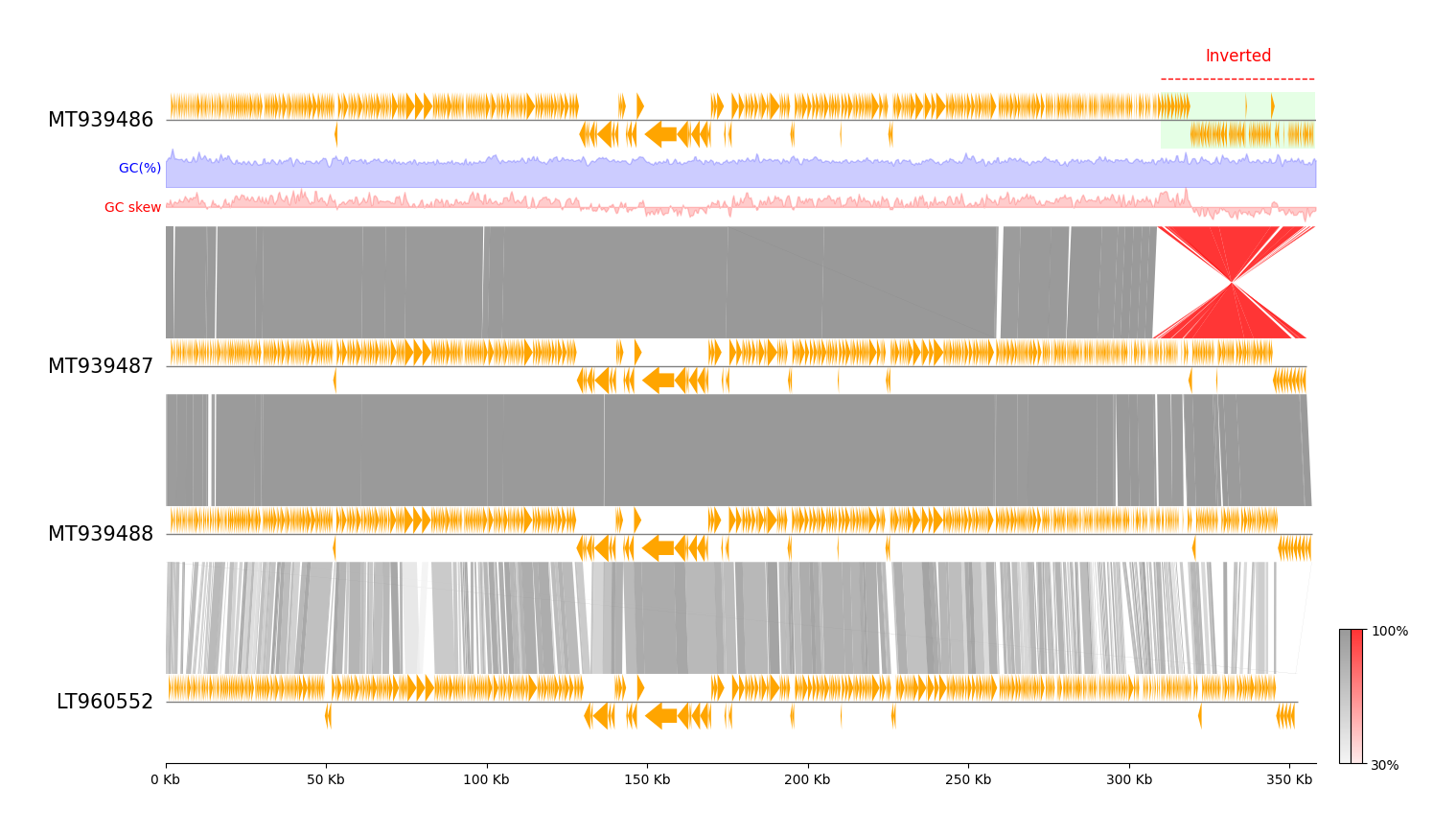
Fig.3 Four E.coli genome comparison result

Installation
Python 3.7 or later is required for installation.
Install PyPI package:
pip install pygenomeviz
Install bioconda package:
conda install -c conda-forge -c bioconda pygenomeviz
API Examples
Jupyter notebooks containing code examples below is available here.
Basic Example
Single Track
from pygenomeviz import GenomeViz
name, genome_size = "Tutorial 01", 5000
cds_list = ((100, 900, -1), (1100, 1300, 1), (1350, 1500, 1), (1520, 1700, 1), (1900, 2200, -1), (2500, 2700, 1), (2700, 2800, -1), (2850, 3000, -1), (3100, 3500, 1), (3600, 3800, -1), (3900, 4200, -1), (4300, 4700, -1), (4800, 4850, 1))
gv = GenomeViz()
track = gv.add_feature_track(name, genome_size)
for idx, cds in enumerate(cds_list, 1):
start, end, strand = cds
track.add_feature(start, end, strand, label=f"CDS{idx:02d}")
gv.savefig("example01.png")

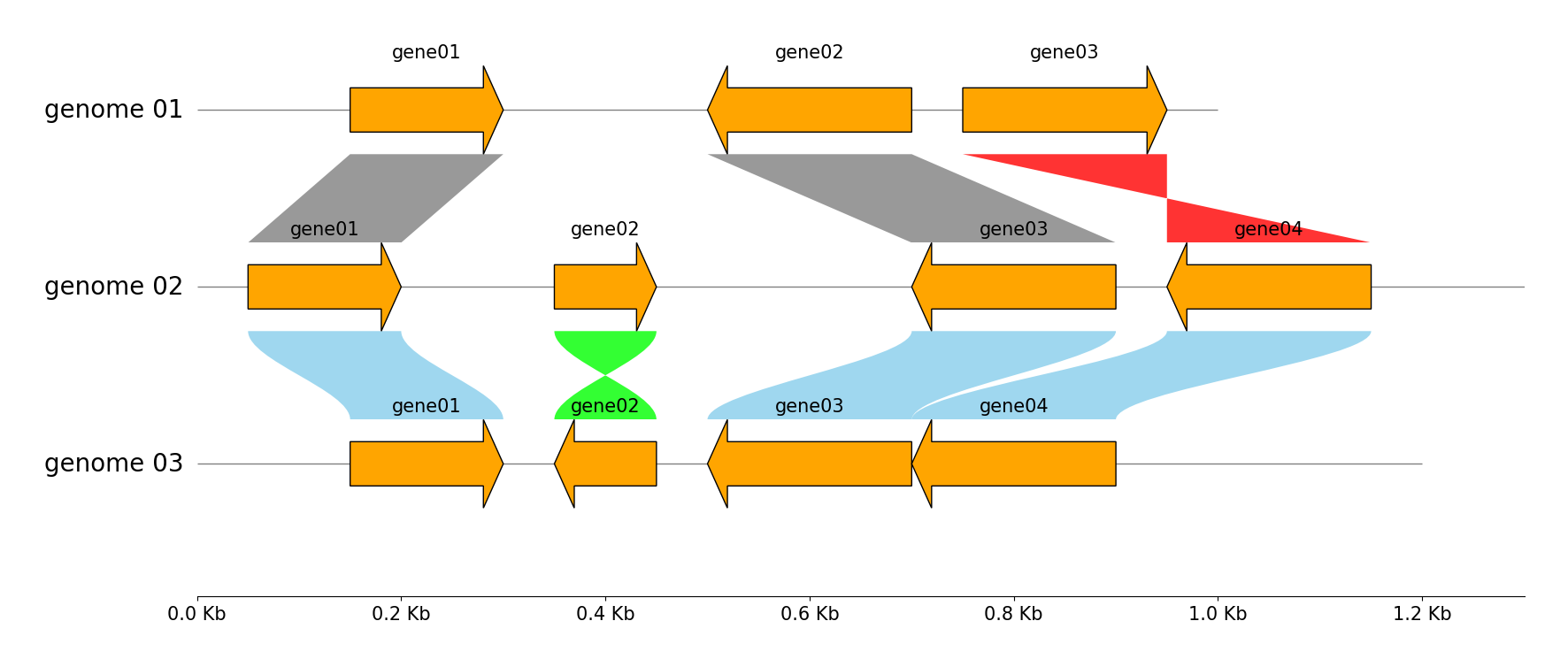
Multiple Tracks & Links
from pygenomeviz import GenomeViz
genome_list = (
{"name": "genome 01", "size": 1000, "cds_list": ((150, 300, 1), (500, 700, -1), (750, 950, 1))},
{"name": "genome 02", "size": 1300, "cds_list": ((50, 200, 1), (350, 450, 1), (700, 900, -1), (950, 1150, -1))},
{"name": "genome 03", "size": 1200, "cds_list": ((150, 300, 1), (350, 450, -1), (500, 700, -1), (700, 900, -1))},
)
gv = GenomeViz(tick_style="axis")
for genome in genome_list:
name, size, cds_list = genome["name"], genome["size"], genome["cds_list"]
track = gv.add_feature_track(name, size)
for idx, cds in enumerate(cds_list, 1):
start, end, strand = cds
track.add_feature(start, end, strand, label=f"gene{idx:02d}", linewidth=1, labelrotation=0, labelvpos="top", labelhpos="center", labelha="center")
# Add links between "genome 01" and "genome 02"
gv.add_link(("genome 01", 150, 300), ("genome 02", 50, 200))
gv.add_link(("genome 01", 700, 500), ("genome 02", 900, 700))
gv.add_link(("genome 01", 750, 950), ("genome 02", 1150, 950))
# Add links between "genome 02" and "genome 03"
gv.add_link(("genome 02", 50, 200), ("genome 03", 150, 300), normal_color="skyblue", inverted_color="lime", curve=True)
gv.add_link(("genome 02", 350, 450), ("genome 03", 450, 350), normal_color="skyblue", inverted_color="lime", curve=True)
gv.add_link(("genome 02", 900, 700), ("genome 03", 700, 500), normal_color="skyblue", inverted_color="lime", curve=True)
gv.add_link(("genome 03", 900, 700), ("genome 02", 1150, 950), normal_color="skyblue", inverted_color="lime", curve=True)
gv.savefig("example02.png")
Exon Features
from pygenomeviz import GenomeViz
exon_regions1 = [(0, 210), (300, 480), (590, 800), (850, 1000), (1030, 1300)]
exon_regions2 = [(1500, 1710), (2000, 2480), (2590, 2800)]
exon_regions3 = [(3000, 3300), (3400, 3690), (3800, 4100), (4200, 4620)]
gv = GenomeViz()
track = gv.add_feature_track(name=f"Exon Features", size=5000)
track.add_exon_feature(exon_regions1, strand=1, plotstyle="box", label="box", labelrotation=0, labelha="center")
track.add_exon_feature(exon_regions2, strand=-1, plotstyle="arrow", label="arrow", labelrotation=0, labelha="center", facecolor="darkgrey", intron_patch_kws={"ec": "red"})
exon_labels = [f"exon{i+1}" for i in range(len(exon_regions3))]
track.add_exon_feature(exon_regions3, strand=1, plotstyle="bigarrow", label="bigarrow", facecolor="lime", linewidth=1, exon_labels=exon_labels, labelrotation=0, labelha="center", exon_label_kws={"y": 0, "va": "center", "color": "blue"})
gv.savefig("example03.png")

Practical Example
Single Track from Genbank file
from pygenomeviz import Genbank, GenomeViz, load_dataset
gbk_files, _ = load_dataset("enterobacteria_phage")
gbk = Genbank(gbk_files[0])
gv = GenomeViz()
track = gv.add_feature_track(gbk.name, gbk.genome_length)
track.add_genbank_features(gbk)
gv.savefig("example04.png")

Multiple Tracks & Links from Genbank files
from pygenomeviz import Genbank, GenomeViz, load_dataset
gv = GenomeViz(
fig_track_height=0.7,
feature_track_ratio=0.2,
tick_track_ratio=0.4,
tick_style="bar",
align_type="center",
)
gbk_files, links = load_dataset("escherichia_phage")
for gbk_file in gbk_files:
gbk = Genbank(gbk_file)
track = gv.add_feature_track(gbk.name, gbk.genome_length)
track.add_genbank_features(gbk, facecolor="limegreen", linewidth=0.5, arrow_shaft_ratio=1.0)
for link in links:
link_data1 = (link.ref_name, link.ref_start, link.ref_end)
link_data2 = (link.query_name, link.query_start, link.query_end)
gv.add_link(link_data1, link_data2, v=link.identity, curve=True)
gv.savefig("example05.png")

Customization Tips
Since pyGenomeViz is implemented based on matplotlib, users can easily customize the figure in the manner of matplotlib. Here are some tips for figure customization.
Customization Tips 01
- Add
GC Content&GC skewsubtrack - Add annotation label & fillbox
- Add colorbar for links identity
Code
from pygenomeviz import Genbank, GenomeViz, load_dataset
gv = GenomeViz(
fig_width=12,
fig_track_height=0.7,
feature_track_ratio=0.5,
tick_track_ratio=0.3,
tick_style="axis",
tick_labelsize=10,
)
gbk_files, links = load_dataset("erwinia_phage")
gbk_list = [Genbank(gbk_file) for gbk_file in gbk_files]
for gbk in gbk_list:
track = gv.add_feature_track(gbk.name, gbk.genome_length, labelsize=15)
track.add_genbank_features(gbk, plotstyle="arrow")
min_identity = int(min(link.identity for link in links))
for link in links:
link_data1 = (link.ref_name, link.ref_start, link.ref_end)
link_data2 = (link.query_name, link.query_start, link.query_end)
gv.add_link(link_data1, link_data2, v=link.identity, vmin=min_identity)
# Add subtracks to top track for plotting 'GC content' & 'GC skew'
gv.top_track.add_subtrack(ratio=0.7)
gv.top_track.add_subtrack(ratio=0.7)
fig = gv.plotfig()
# Add label annotation to top track
top_track = gv.top_track # or, gv.get_track("MT939486") or gv.get_tracks()[0]
label, start, end = "Inverted", 310000 + top_track.offset, 358000 + top_track.offset
center = int((start + end) / 2)
top_track.ax.hlines(1.5, start, end, colors="red", linewidth=1, linestyles="dashed", clip_on=False)
top_track.ax.text(center, 2.0, label, fontsize=12, color="red", ha="center", va="bottom")
# Add fillbox to top track
x, y = (start, start, end, end), (1, -1, -1, 1)
top_track.ax.fill(x, y, fc="lime", linewidth=0, alpha=0.1, zorder=-10)
# Plot GC content for top track
gc_content_ax = gv.top_track.subtracks[0].ax
pos_list, gc_content_list = gbk_list[0].calc_gc_content()
gc_content_ax.set_ylim(bottom=0, top=max(gc_content_list))
pos_list += gv.top_track.offset # Offset is required if align_type is not 'left'
gc_content_ax.fill_between(pos_list, gc_content_list, alpha=0.2, color="blue")
gc_content_ax.text(gv.top_track.offset, max(gc_content_list) / 2, "GC(%) ", ha="right", va="center", color="blue")
# Plot GC skew for top track
gc_skew_ax = gv.top_track.subtracks[1].ax
pos_list, gc_skew_list = gbk_list[0].calc_gc_skew()
gc_skew_abs_max = max(abs(gc_skew_list))
gc_skew_ax.set_ylim(bottom=-gc_skew_abs_max, top=gc_skew_abs_max)
pos_list += gv.top_track.offset # Offset is required if align_type is not 'left'
gc_skew_ax.fill_between(pos_list, gc_skew_list, alpha=0.2, color="red")
gc_skew_ax.text(gv.top_track.offset, 0, "GC skew ", ha="right", va="center", color="red")
# Set coloarbar for link
gv.set_colorbar(fig, vmin=min_identity)
fig.savefig("example06.png", bbox_inches="tight")
Customization Tips 02
- Add legends
- Add colorbar for links identity
Code
from matplotlib.lines import Line2D
from matplotlib.patches import Patch
from pygenomeviz import Genbank, GenomeViz, load_dataset
gv = GenomeViz(
fig_width=10,
fig_track_height=0.7,
feature_track_ratio=0.5,
tick_track_ratio=0.5,
align_type="center",
tick_style="bar",
tick_labelsize=10,
)
gbk_files, links = load_dataset("enterobacteria_phage")
for idx, gbk_file in enumerate(gbk_files):
gbk = Genbank(gbk_file)
track = gv.add_feature_track(gbk.name, gbk.genome_length, labelsize=10)
track.add_genbank_features(
gbk,
label_type="product" if idx == 0 else None, # Labeling only top track
label_handle_func=lambda s: "" if s.startswith("hypothetical") else s, # Ignore 'hypothetical ~~~' label
labelsize=8,
labelvpos="top",
facecolor="skyblue",
linewidth=0.5,
)
normal_color, inverted_color, alpha = "chocolate", "limegreen", 0.5
min_identity = int(min(link.identity for link in links))
for link in links:
link_data1 = (link.ref_name, link.ref_start, link.ref_end)
link_data2 = (link.query_name, link.query_start, link.query_end)
gv.add_link(link_data1, link_data2, normal_color, inverted_color, alpha, v=link.identity, vmin=min_identity, curve=True)
fig = gv.plotfig()
# Add Legends (Maybe there is a better way)
handles = [
Line2D([], [], marker=">", color="skyblue", label="CDS", ms=10, ls="none"),
Patch(color=normal_color, label="Normal Link"),
Patch(color=inverted_color, label="Inverted Link"),
]
fig.legend(handles=handles, frameon=True, bbox_to_anchor=(1, 0.8), loc="upper left", ncol=1, handlelength=1, handleheight=1)
# Set colorbar for link
gv.set_colorbar(fig, bar_colors=[normal_color, inverted_color], alpha=alpha, vmin=min_identity, bar_height=0.15, bar_label="Identity", bar_labelsize=10)
fig.savefig("example07.png", bbox_inches="tight")
CLI Examples
pyGenomeViz provides CLI workflow for visualization of genome alignment or
homologous CDS search results with MUMmer or MMseqs or progressiveMauve.
Each CLI workflow requires the installation of additional dependent tools to execute.
See CLI document for details.
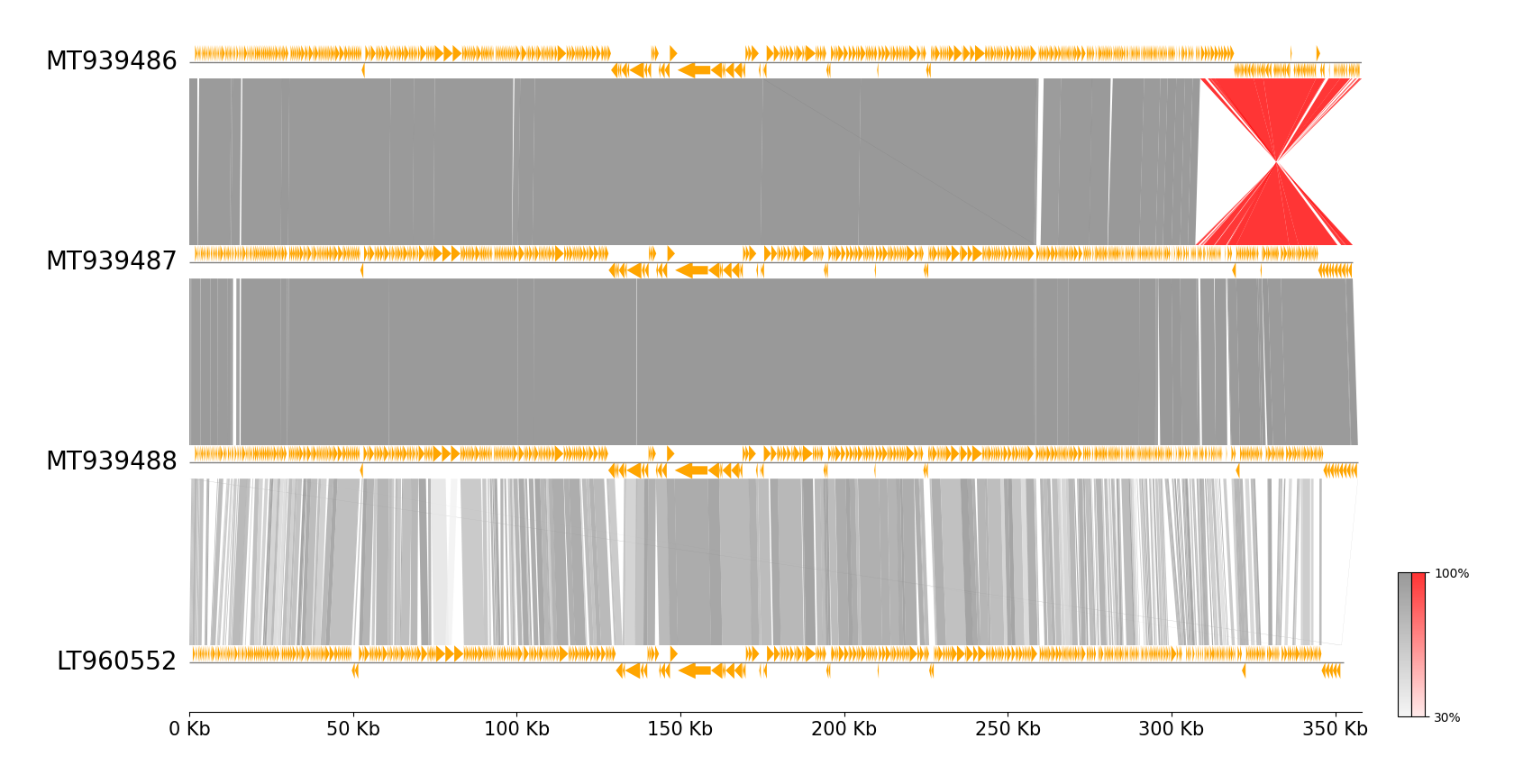
MUMmer CLI Workflow Example
See pgv-mummer document for details.
Download example dataset: pgv-download-dataset -n escherichia_phage
pgv-mummer --gbk_resources MT939486.gbk MT939487.gbk MT939488.gbk LT960552.gbk \
-o mummer_example --tick_style axis --align_type left --feature_plotstyle arrow
MMseqs CLI Workflow Example
See pgv-mmseqs document for details.
Downalod example dataset: pgv-download-dataset -n enterobacteria_phage
pgv-mmseqs --gbk_resources NC_019724.gbk NC_024783.gbk NC_016566.gbk NC_013600.gbk NC_031081.gbk NC_028901.gbk \
-o mmseqs_example --fig_track_height 0.7 --feature_linewidth 0.3 --tick_style bar --curve \
--normal_link_color chocolate --inverted_link_color limegreen --feature_color skyblue

progressiveMauve CLI Workflow Example
See pgv-pmauve document for details.
Download example dataset: pgv-download-dataset -n escherichia_coli
pgv-pmauve --seq_files NC_000913.gbk NC_002695.gbk NC_011751.gbk NC_011750.gbk \
-o pmauve_example --tick_style bar
Inspiration
pyGenomeViz was inspired by
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pygenomeviz-0.2.0.tar.gz.
File metadata
- Download URL: pygenomeviz-0.2.0.tar.gz
- Upload date:
- Size: 176.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.1.14 CPython/3.9.13 Linux/5.15.0-1014-azure
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3860128d494c397b20565b1b3594dcd481413f386743e6aac18787ecc5c79738
|
|
| MD5 |
e9197398aaa107997a6954f96e0cce55
|
|
| BLAKE2b-256 |
679a959c12a4b2f3bdb7760159ce02448ae24d196634f553a265889a91157674
|
File details
Details for the file pygenomeviz-0.2.0-py3-none-any.whl.
File metadata
- Download URL: pygenomeviz-0.2.0-py3-none-any.whl
- Upload date:
- Size: 45.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.1.14 CPython/3.9.13 Linux/5.15.0-1014-azure
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8984d60dbe48b907b2d9f6b80eee1ffabbab5b43163543b12ccdc04e6e05c9af
|
|
| MD5 |
115761ae1b239bd081b049876a031e6f
|
|
| BLAKE2b-256 |
97a7172033268a1850f64260fdcef4c34e68d095bc8eef3911857086a5b45074
|







