Transform casual text into a leetspeak and word camouflage version.

Project description
Pyleetspeak :one::three::three::seven::robot:
Currently in developing process. Stay tuned for new releases related to new word camouflaging methods and NER data generation.
Overview
Word camouflage is currently used to evade content moderation in Social Media. Therefore, this tool aims to counter new misinformation that emerges in social media platforms by providing a mechanism for simulating and generating leetspeak/word camouflaging data.
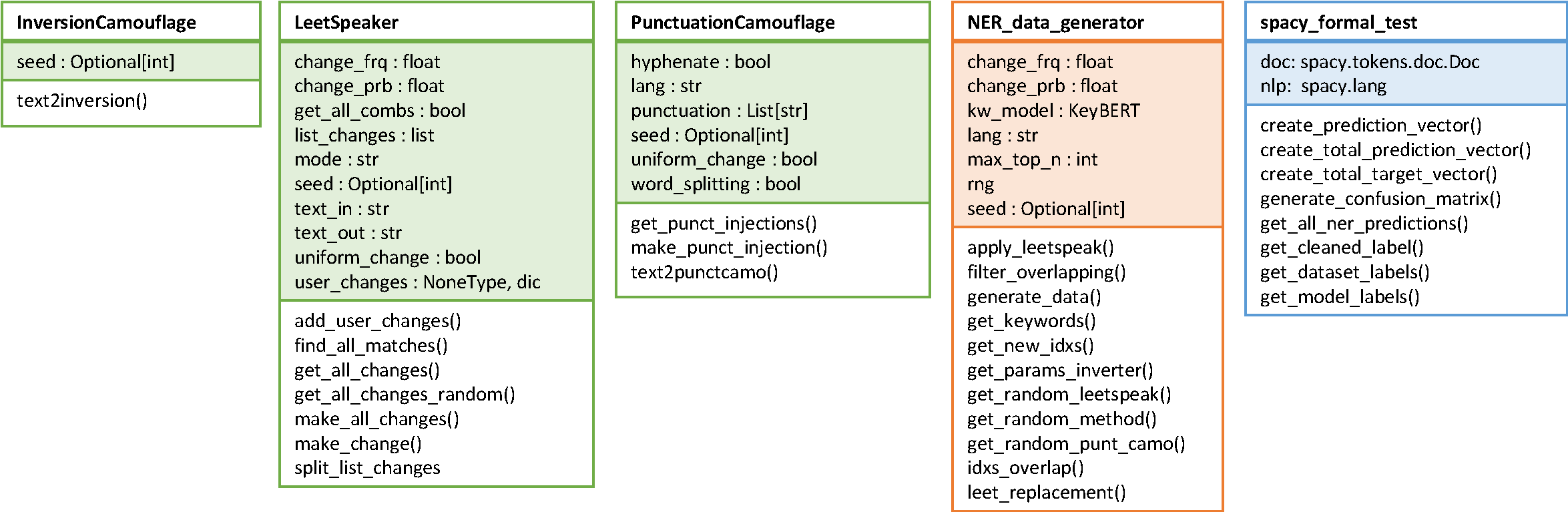
pyleetspeak includes three different, but compatible, text modifications word camouflaging methods: LeetSpeaker, PuntctuationCamouflage and InversionCamouflage.
LeetSpeaker: This module apply the canonical 'leetspeak' method of producing visually similar character strings by replacing alphabet characters with special symbols or numbers. There's many different ways you can use leet speak. Ranging from basic vowel substitutions to really advanced combinations of various punctuation marks and glyphs. Different leetspeak levels are included.PuntctuationCamouflage: This module apply punctuation symbol injections in the text. It is another version of producing visually similar character strings. The location of the punctuation injections and the symbols used can be selected by the user.InversionCamouflage: This module create new camouflaged version of words by inverting the order of the syllables. It works by separating a input text in syllabels, select two syllabels and invert them.
These modules can be combined into a string to generate a leetspeak version of an input text. Precisely, this can be achieved by using the Leet_NER_generator method that selects the most semantically relevant words from an input text, applies word camouflage and creates compatible annotations for NER detection.
UML diagrams
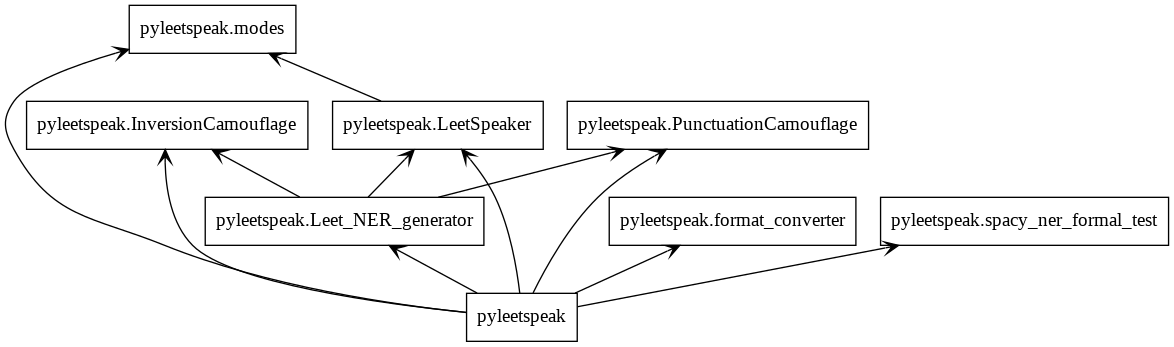
Installation
pip install pyleetspeak
Word camouflaging
LeetSpeaker
Canonical leetspeak in which standard letters are often replaced by numerals or special characters that resemble the letters in appearance
Parameters
You can see an example of use in a Heroku App:
The only required argument that the user has to provide is the text_in argument which represent the casual text to transform to leetspeak. Nonetheless, there are other optional arguments that control the behaviour of the transformation:`
change_prbdetermines the probability of a transformation to take place (i.e, if it is equal 1 all the possible transformation will be applied).change_frqis affects how frequently a transformation will occur (i.e, if it is equal 1 all the letters of this transformation type will be changed).modecontrols the level of leetspeak transformation. Currently onlybasicmode is available. We are working on more modes. Stay tuned.seedcontrols the reproducibility of the results. By default no seed is applied.verbosecontrols the verbosity of the proccess.get_all_combsto obtain all the possible leetspeak versions of a casual textuniform_changedetermines if the same substitution character should be used in all the positions where the casual text will be modified.
Minor concerns about the package behaviour: accents are deleted using Unidecode. This is important for languages like Spanish, where the word "melocotón" is preprocessed as "melocoton" and finally transformed to leetspeak.
Modes
There are several modes available:
basicintermediateadvancedcovid_basiccovid_intermediate
Basic Use
Let's see a simple working example:
from pyleetspeak import LeetSpeaker
text_in = "I speak leetspeak"
leeter = LeetSpeaker(
change_prb=0.8, change_frq=0.6, mode="basic", seed=None, verbose=False
)
leet_result = leeter.text2leet(text_in)
print(leet_result)
For the sake of reproducibility you can set a random seed:
from pyleetspeak import LeetSpeaker
leeter = LeetSpeaker(
change_prb=0.8,
change_frq=0.5,
mode="basic",
seed=42, # for reproducibility purposes
verbose=False,
)
leet_result = leeter.text2leet(text_in)
print(leet_result)
# "1 sp34k leetsp3ak"
Define your own changes
pyleetspeak is prepared to apply substitutions defined by the user. It is essential to highlight that these new user-defined changes have to follow two possible formats, dictionary or List of tuples. Here we show a toy example to add two new target characters from the original text to be replaced by two and one different characters, respectively:
-
Dictionary type:
{"target_chr_1": ["sub_chr_1", "sub_chr_1"], "target_chr_2": ["sub_chr_1"]}
-
List[Tuple] type:
[("target_chr_1", ["sub_chr_1", "sub_chr_1"]), (("target_chr_2", ["sub_chr_1"])]
You can add new user-defined substitutions:
from pyleetspeak import LeetSpeaker
text_in = "New changes Leetspeak"
letter = LeetSpeaker(
change_prb=1,
change_frq=0.8,
mode="basic",
seed=21,
verbose=False,
get_all_combs=False,
user_changes=[("a", "#"), ("s", "$")], # user-defined changes
)
print(letter.text2leet(text_in))
# N3w ch@ng3$ L33t$pe4k
Moreover, you can use only the user-defined substitutions:
from pyleetspeak import LeetSpeaker
text_in = "Only user changes: Leetspeak"
letter = LeetSpeaker(
change_prb=1,
change_frq=0.8,
mode=None, # None pre-defined changes will be applied
seed=21,
verbose=False,
get_all_combs=False,
user_changes = [("a", "#"), ("s", "$")], # user-defined changes
)
print(letter.text2leet(text_in))
# Only u$er ch#nge$: Leet$pe#k
Uniform substitutions
Usually, the same substitution character is used in all the matches for a specific substitution type. In other words, the same target character is usually replaced by the same substitution character. In order to reproduce this situation, pyleetspeak includes the uniform_change parameter that determines if all the matches of a target character are jointly or independently substituted. In the following example notice how the target character "e" is always replaced by "€" when uniform_changes is se to True.
from pyleetspeak import LeetSpeaker
text_in = "Leetspeak"
leeter = LeetSpeaker(
change_prb=1, # All subs type will occur
change_frq=1, # All matches of target chr will be changed
mode="basic",
seed=41,
user_changes=[
("e", ["3", "%", "€", "£"])
], # Add diferent subs characters for target chr "e"
uniform_change=True, # Use the same substitution chr for each target chr
)
print(leeter.text2leet(text_in))
# L€€tsp€4k
Get all changes
You can also obtain all the possible versions of a leetspeak text using the get_all_combs parameter like this:
from pyleetspeak import LeetSpeaker
text_in = "leetspeak"
leeter = LeetSpeaker(
mode="basic",
get_all_combs=True,
user_changes = [("e", "€"), ("s", "$")], # user-defined changes
)
leet_result = leeter.text2leet(text_in)
print(len(leet_result))
assert len(leet_result) == 162 # all possible combinations
leet_result[20]
# 162
# 'le3t$p34k'
If you are only interested in the combinations that apply the same substitution character for each target target, you can also set uniform_change to True.
from pyleetspeak import LeetSpeaker
text_in = "leetspeak"
leeter = LeetSpeaker(
mode="basic",
get_all_combs=True,
user_changes = [("e", "€"), ("s", "$")], # user-defined changes
uniform_change = True
)
leet_result = leeter.text2leet(text_in)
print(len(leet_result))
assert len(leet_result) == 90 # all possible combinations
leet_result[60]
# 90
# 'le3t$peak'
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pyleetspeak-0.1.9.tar.gz.
File metadata
- Download URL: pyleetspeak-0.1.9.tar.gz
- Upload date:
- Size: 24.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.7.1 importlib_metadata/4.10.0 pkginfo/1.8.2 requests/2.26.0 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.9.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
78de56458b7e35c7a3749eaf0bb9e09e5a09f541b1f79e7f6c2ea976f73e240a
|
|
| MD5 |
2a1b8a7e08426b1043dd4d968ab3db02
|
|
| BLAKE2b-256 |
a71f650ed11d074a3ede8e82ee5b3fcff5145e254fff4b7ec3c6843902ab7427
|
File details
Details for the file pyleetspeak-0.1.9-py3-none-any.whl.
File metadata
- Download URL: pyleetspeak-0.1.9-py3-none-any.whl
- Upload date:
- Size: 26.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.7.1 importlib_metadata/4.10.0 pkginfo/1.8.2 requests/2.26.0 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.9.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8234a9f2e3519f7969fc50ea45a947394f973bd4849d8d9f7fca43bf8e8b073d
|
|
| MD5 |
41adbb936541da20f9a5c2a03ab1278d
|
|
| BLAKE2b-256 |
99a5ff7cf3adb61c65505411cf8c069a2c4b9d9460c26a10f07b16d35af8b8da
|







