Statistical reporting and table preparation framework for Python — the missing reporting layer.

Project description






PySofra turns datasets, fitted models, and summary statistics into publication-ready tables — across HTML · Markdown · LaTeX · DOCX · PPTX · XLSX · PNG — from a single immutable
SofraTableobject. It brings the practical workflows of R'stableone,gtsummary, andflextableinto a single coherent Pythonic API.
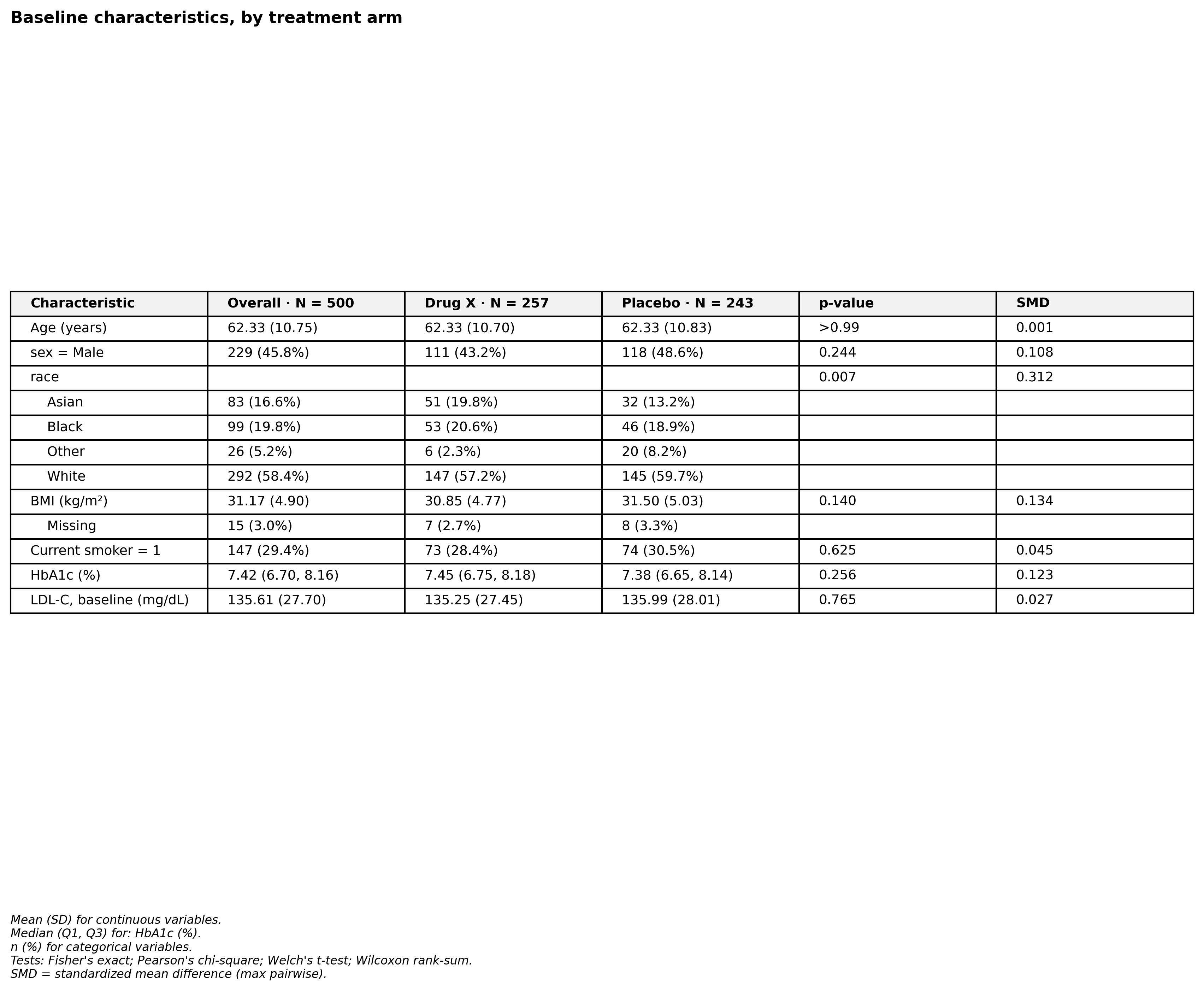
Baseline characteristics, by treatment arm. One line of code.
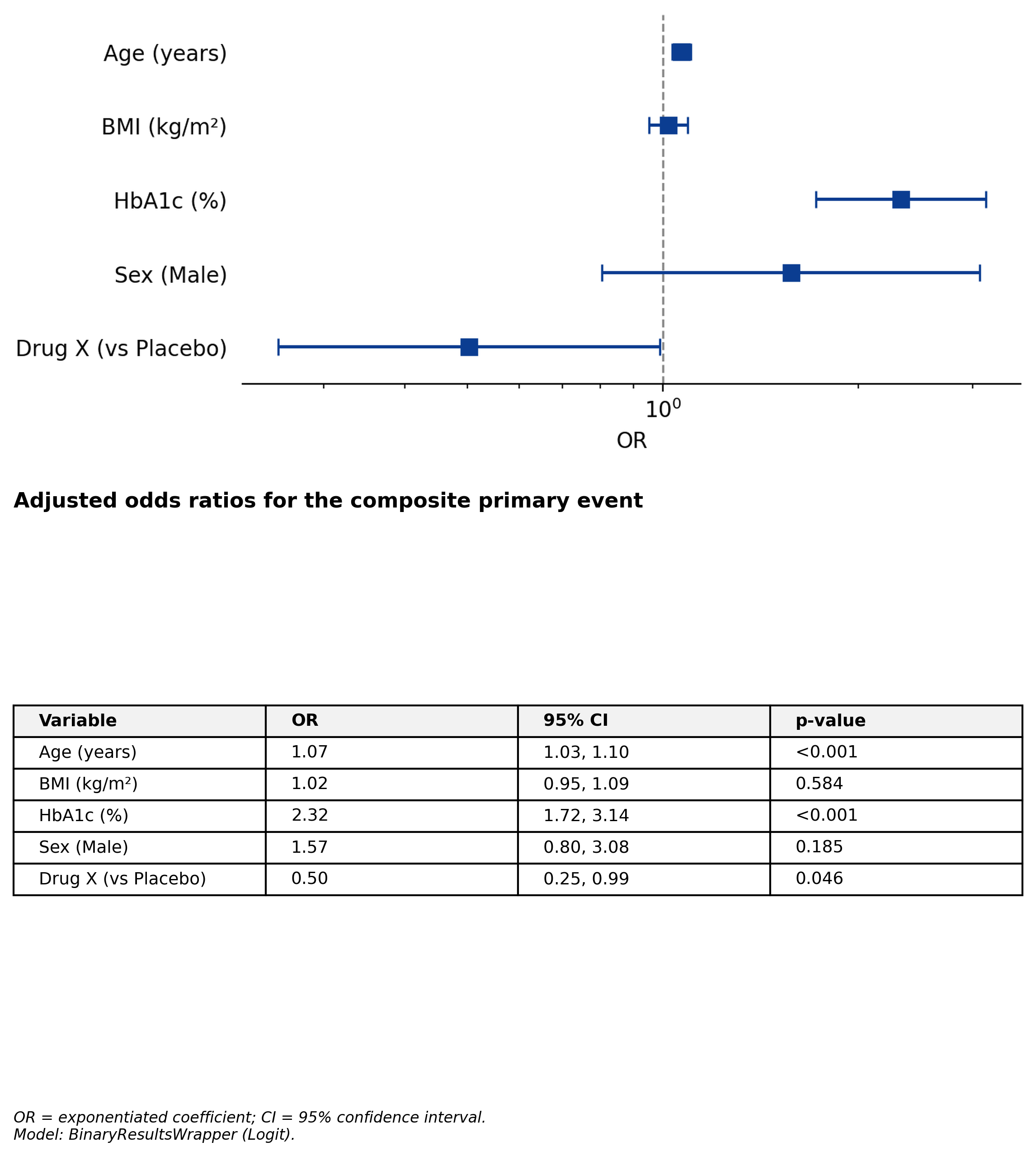
Adjusted ORs + inline forest plot tbl_regression(fit).with_forest_plot()
|
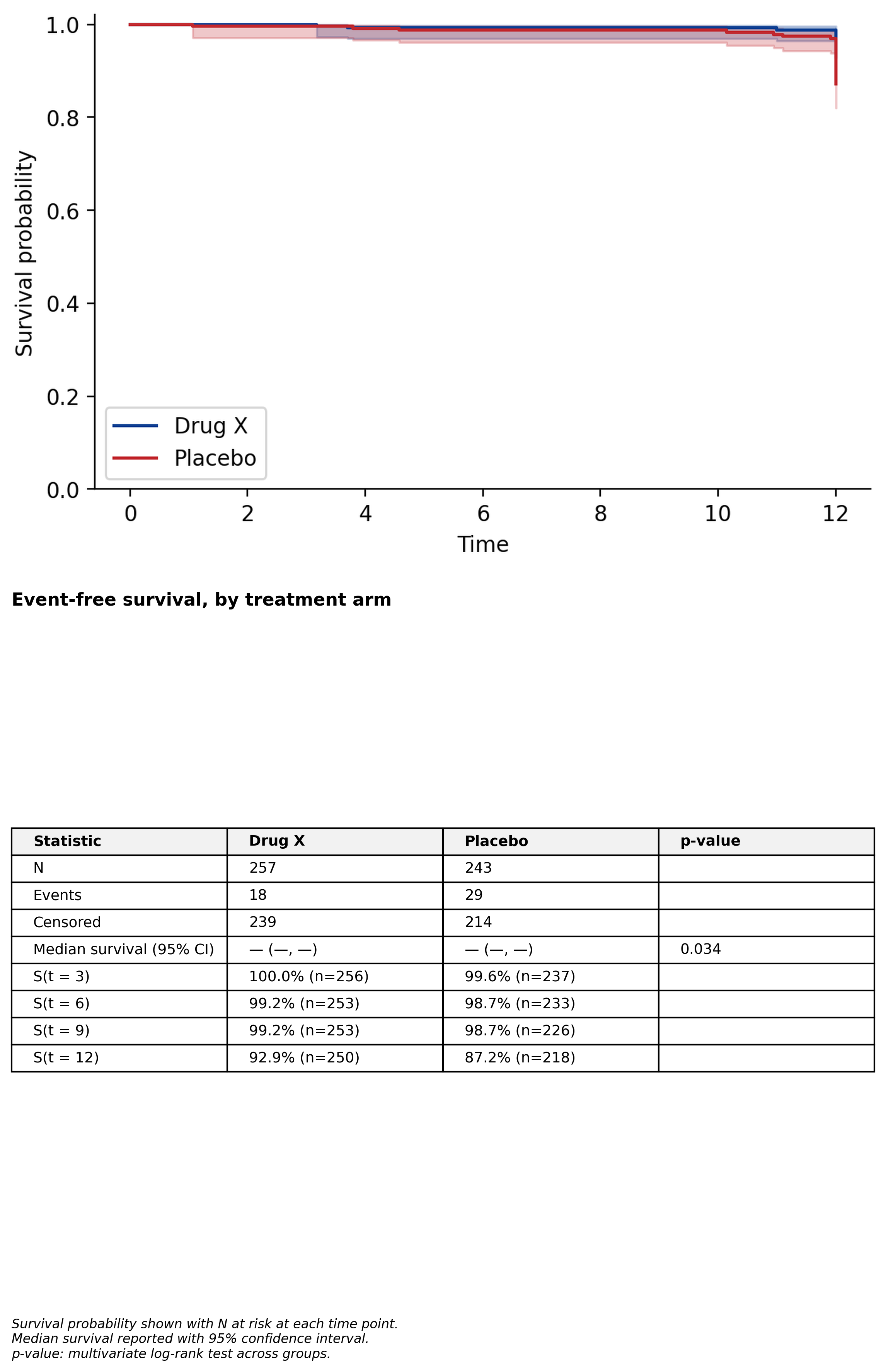
KM table + inline survival curve tbl_survival(...).with_km_plot()
|
Why PySofra
- One immutable object, seven output formats — build a
SofraTableonce, render to HTML / Markdown / LaTeX / DOCX / PPTX / XLSX / PNG, all byte-deterministic across processes - Auto-dispatched statistical tests — Welch, Wilcoxon, ANOVA, Kruskal–Wallis, Fisher, χ², Rao–Scott, design-adjusted t — picked by variable kind, overridable per-row
- Inline forest plots and KM curves — embed matplotlib figures directly into the table; the same
SofraTablerenders them across every backend - Statistically correct — every numeric output validated against
scipy/statsmodels/lifelinesreference implementations at machine precision - Method-chainable and immutable — every modifier returns a new table; no in-place mutation, no global state, fully reproducible
Showcase notebook — 47 cells, every section a side-by-side numeric proof. Start here if you have 60 seconds.
End-to-end tutorial — 126 cells walking every public feature on a synthetic two-arm trial.
Quick start
import numpy as np
import pandas as pd
import pysofra as ps
# Toy two-arm trial; replace with your own DataFrame in real use.
rng = np.random.default_rng(0)
df = pd.DataFrame({
"arm": rng.choice(["Placebo", "Treatment"], 200),
"age": rng.normal(60, 10, 200).round(),
"bmi": rng.normal(28, 5, 200).round(1),
"event": rng.binomial(1, 0.3, 200),
})
# Table 1 — baseline characteristics by treatment arm
tbl = (
ps.tbl_one(df, by="arm")
.add_p()
.add_smd()
.add_overall()
.theme("clinical")
)
tbl # renders in Jupyter / Colab / VS Code
tbl.to_docx("table1.docx") # publication-quality Word
tbl.to_html() # standalone HTML fragment
tbl.to_markdown() # GitHub-flavored Markdown
The same workflow handles regression tables:
import statsmodels.api as sm
X = sm.add_constant(df[["age", "bmi"]])
fit = sm.Logit(df["event"], X).fit(disp=False)
(
ps.tbl_regression(fit, exponentiate=True)
.bold_p()
.theme("jama")
.to_docx("table2.docx")
)
The end-to-end worked example — baseline table by treatment arm, regression table with forest plot, and Kaplan-Meier survival summary — is in the showcase notebook.
What's in the box
| Feature | Function / object | Status |
|---|---|---|
| Baseline Table 1 | ps.tbl_one |
MVP |
| Descriptive summary | ps.tbl_summary |
MVP |
| Regression results | ps.tbl_regression |
MVP |
| Side-by-side merge | ps.tbl_merge |
MVP |
| Vertical stack | ps.tbl_stack |
MVP |
| HTML / Markdown | .to_html / .to_markdown |
MVP |
| DOCX export | .to_docx |
MVP |
| LaTeX export | .to_latex |
MVP |
| PPTX export | .to_pptx |
MVP (extras) |
| Excel export | .to_xlsx |
MVP |
| Inline forest plots | tbl_regression(...).with_forest_plot() |
MVP |
| Inline KM curves | tbl_survival(...).with_km_plot() |
MVP |
| Cross-backend plot embedding | DOCX/PPTX/LaTeX include the plot too | MVP |
| Rao–Scott chi-square | weighted Table 1 auto-route | MVP |
SurveyDesign (strata + cluster + FPC) |
Taylor-linearised variance | MVP |
| Themes | clinical, jama, nejm, compact, minimal |
MVP |
| Auto test selection | t-test / ANOVA / Wilcoxon / Kruskal / χ² / Fisher | MVP |
| Per-variable test overrides | tests={'age': 'wilcoxon', ...} |
MVP |
| Multiplicity adjustment | .add_q() — BH, BY, Bonferroni, Holm, Hommel, Šidák |
MVP |
| Multi-model regression | tbl_regression([m1, m2], model_labels=[...]) |
MVP |
| lifelines (Cox / AFT) | tbl_regression(cph) |
MVP |
| sklearn (linear models) | tbl_regression(clf) — point estimates only |
MVP |
| Kaplan–Meier summary | tbl_survival(df, time=, event=, by=, times=[...]) |
MVP |
| Survey-weighted Table 1 | tbl_one(..., weights='w') |
MVP |
| polars input | tbl_one(pl.DataFrame(...)) |
MVP |
| Conditional formatting | .bold_if, .highlight_if, .style_if |
MVP |
| Sticky-header notebook tables | .to_html(sticky_header=True) |
MVP |
| Standardised mean differences | continuous + categorical (Yang–Dalton) | MVP |
| Notebook rendering | _repr_html_ / _repr_markdown_ / _repr_latex_ |
MVP |
Design principles
- Backend-agnostic tables. A
SofraTableis the single source of truth; every renderer (HTML, Markdown, DOCX, …) reads the same object. - Immutable method chaining. Every modifier returns a new
SofraTable. No surprises, no global state. - Strong defaults, explicit overrides. Sensible journal-style output out of the box; per-variable type, label, and test overrides when you need them.
- Deterministic. The same input always produces the same output — critical for reproducible research.
- No magic. No nonstandard evaluation, no metaprogramming, no network calls, no telemetry.
Installation
pip install pysofra
PySofra requires Python ≥ 3.11. The core install only pulls numpy,
pandas, scipy, statsmodels, and python-docx. Domain extras unlock
the features that depend on heavier optional libraries:
pip install "pysofra[survival]" # tbl_survival + KM curves (lifelines, matplotlib)
pip install "pysofra[plot]" # forest plots, table-as-image (matplotlib)
pip install "pysofra[pptx]" # PowerPoint export (python-pptx)
pip install "pysofra[xlsx]" # Excel export (xlsxwriter)
pip install "pysofra[polars]" # accept polars DataFrames as input
pip install "pysofra[sklearn]" # tbl_regression on scikit-learn models
pip install "pysofra[all]" # everything above
pip install "pysofra[dev]" # testing + linting (pytest, ruff, mypy, hypothesis)
Status
PySofra is in alpha (0.1.0a17). The public API surface is pinned
by an explicit
API-stability test
so that any unintended rename, removal, or signature change surfaces as
a failed test. The contract covers the top-level name set, every
builder signature, the full SofraTable method and attribute surface,
and four behavioural guarantees: builders return SofraTable,
modifiers are copy-on-write, every public symbol carries a docstring,
and a representative build emits no pysofra-originated
DeprecationWarning. The full policy — including the post-1.0
soft-deprecation → hard-deprecation → removal ladder — is documented
under
Concepts → API stability & deprecation policy.
Quality bar at this release:
- 1030+ tests passing, near-100% line coverage, mypy strict, ruff clean.
- Every numeric output is validated against
scipy,lifelines,statsmodels, or a hand-computed textbook formula (test_statistical_correctness.py). - Universal invariants enforced via Hypothesis on 720 randomized examples per CI run (test_property_invariants.py).
- Renderer output is byte-deterministic — identical input always produces identical HTML/Markdown/LaTeX, required for reproducible publication artifacts (test_renderer_consistency.py).
Bug reports and use-case feedback are very welcome.
Independently verifying PySofra (external auditors)
If you are a reviewer, sceptic, or downstream user who wants to
independently verify PySofra's claims end-to-end, the recipe is
documented in
AUDITOR.md.
The repository ships a 53-step
case-study notebook
that downloads NHANES 2017-2018 directly from the CDC, fits real
models, and cross-checks every numerical claim against R survey,
lifelines, scipy, statsmodels, and Newcombe-textbook references.
The notebook hard-asserts pysofra.__version__ == "0.1.0a17" against
the release you installed from PyPI (so PyPI ↔ GitHub drift is
caught immediately), and terminates with a single canonical line:
AUDIT COMPLETE — 51/51 contracts passed | pysofra 0.1.0a17 | <UTC>
A pre-executed HTML rendering is also checked in for read-only review:
jss_case_study.html.
The pinned environment is captured in
requirements-audit.txt
so an external reviewer reproduces the exact CI environment.
Contributing
Bug reports, feature requests, and pull requests are all very welcome.
Please read
CONTRIBUTING.md
for the workflow, the quality gates, and the
Code of Conduct.
License
GPL-3.0-or-later. See
LICENSE.
Citation
If you use PySofra in academic work, please cite the project — see
CITATION.cff.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pysofra-0.1.0a17.tar.gz.
File metadata
- Download URL: pysofra-0.1.0a17.tar.gz
- Upload date:
- Size: 299.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6c3942fb0e62e2a5e45795bb0f355edc23b57ba9e851c9ab7cdfb4ad6ddc947c
|
|
| MD5 |
d6119b0f63ca021560d32b468d582bdf
|
|
| BLAKE2b-256 |
34bf5296d5a9ea62a6d7a52fcda4aa72bb3b0a0ddea940e60d54082dbbbd1e96
|
File details
Details for the file pysofra-0.1.0a17-py3-none-any.whl.
File metadata
- Download URL: pysofra-0.1.0a17-py3-none-any.whl
- Upload date:
- Size: 185.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
feea5d83ee1a3fe9d6c08978a4a6f1bfacc7acf41c27b0c3bf980f42af0da6fb
|
|
| MD5 |
a0fcf976168d21ef9d6491e224d5a1e4
|
|
| BLAKE2b-256 |
39dd68d9ff50d1255db673590f18f4f6c39dc599a03c44430d3c8bf11573a3e0
|







