Make your PyTorch faster

Project description
Variational Dropout Sparsifies NN (Pytorch)


Make your neural network 300 times faster!
Pytorch implementation of Variational Dropout Sparsifies Deep Neural Networks (arxiv:1701.05369).
Description
The discovered approach helps to train both convolutional and dense deep sparsified models without significant loss of quality. Additive Noise Reparameterization
and the Local Reparameterization Trick discovered in the paper helps to eliminate weights prior's restrictions (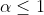
Usage
import torch_ard as nn_ard
from torch import nn
import torch.nn.functional as F
input_size, hidden_size, output_size = 60, 150, 1
model = nn.Sequential(
nn_ard.LinearARD(input_size, hidden_size),
nn.ReLU(),
nn_ard.LinearARD(hidden_size, output_size)
)
criterion = nn_ard.ELBOLoss(model, F.cross_entropy)
print('Sparsification ratio: %.3f%%' % (100.*nn_ard.get_dropped_params_ratio(model)))
# test stage
model.eval() # Needed for speed-up
model(input)
Installation
pip install git+https://github.com/HolyBayes/pytorch_ard
Experiments
All experiments are placed at examples folder and contains baseline and implemented models comparison.
Boston dataset
Two scripts were used in the experiment: boston_baseline.py and boston_ard.py. Training procedure for each experiment was 100000 epoches, Adam(lr=1e-3). Baseline model was dense neural network with single hidden layer with hidden size 150.
| Baseline (nn.Linear) | LinearARD, no reg | LinearARD, reg=0.0001 | LinearARD, reg=0.001 | LinearARD, reg=0.1 | LinearARD, reg=1 | |
|---|---|---|---|---|---|---|
| MSE (train) | 1.751 | 1.626 | 1.587 | 1.962 | 17.167 | 33.682 |
| MSE (test) | 22.580 | 16.229 | 15.957 | 8.416 | 25.695 | 30.231 |
| Compression, % | 0 | 0.38 | 52.95 | 64.19 | 97.29 | 99.29 |
You can see on the table above that variating regularization factor any degree of compression can be achieved (for example, ~99.29% of connections can be dropped if reg_factor=1 will be used). Moreover, you can see that training with LinearARD layers with some regularization parameters (like reg=0.001 in the table above) not only significantly reduces number of model parameters (>64% of parameters can be dropped after training), but also significantly increases quality on test, reducing overfitting.
Tips
- Despite the high performance of implemented layers in "end-to-end" mode, authors recommends to use in fine-tuning pretrained models without ARD prior. In this case the best performance could be achieved. Moreover, it will be faster - despite of comparable convergence speed of this layers optimization, each training epoch takes more time (approx. twice longer - ~2 times more parameters in *ARD implementations). This fact well describable - using ARD prior in earlier stages can drop useful connections with unobvious dependencies.
- Model's sparsification takes almost no any speed-up effects until You convert it to the sparse one! (TODO)
Requirements
- PyTorch >= 0.4.0
- SkLearn >= 0.19.1
- Pandas >= 0.23.3
- Numpy >= 1.14.5
Authors
@article{molchanov2017variational,
title={Variational Dropout Sparsifies Deep Neural Networks},
author={Molchanov, Dmitry and Ashukha, Arsenii and Vetrov, Dmitry},
journal={arXiv preprint arXiv:1701.05369},
year={2017}
}
Original implementation (Theano/Lasagne)
Citation
@misc{pytorch_ard,
author = {Artem Ryzhikov},
title = {HolyBayes/pytorch_ard},
url = {https://github.com/HolyBayes/pytorch_ard},
year = {2018}
}
Contacts
Artem Ryzhikov, LAMBDA laboratory, Higher School of Economics, Yandex School of Data Analysis
E-mail: artemryzhikoff@yandex.ru
Linkedin: https://www.linkedin.com/in/artem-ryzhikov-2b6308103/


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pytorch_ard-0.2.4.tar.gz.
File metadata
- Download URL: pytorch_ard-0.2.4.tar.gz
- Upload date:
- Size: 6.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.6.1 requests/2.24.0 setuptools/51.0.0 requests-toolbelt/0.9.1 tqdm/4.49.0 CPython/3.8.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7e755d1320f4b7b14464a3d2b6e20915ab866830cf3f16ddb1ab4ddbc3f0bb38
|
|
| MD5 |
f9edbab19575ae675d397208c51b889c
|
|
| BLAKE2b-256 |
e03fd20ea6311d41a36877ef8e089c6d237a9d190167982419bdbe6686743239
|
File details
Details for the file pytorch_ard-0.2.4-py3-none-any.whl.
File metadata
- Download URL: pytorch_ard-0.2.4-py3-none-any.whl
- Upload date:
- Size: 6.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.6.1 requests/2.24.0 setuptools/51.0.0 requests-toolbelt/0.9.1 tqdm/4.49.0 CPython/3.8.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0c7c13dc52eff1bf8d35c0075dbbbf6c47aa1f5bd0865550fd1d186d26284e18
|
|
| MD5 |
8e5d9b795684496078face5b3355feaf
|
|
| BLAKE2b-256 |
238ab9a8ae46b47b08a6f7bb6f23dff9a695915e78f9d8e38b5b3a68fd388d27
|







