Python Implementation of Java TreeMap/TreeSet

Project description
pytreemap 




Python implementation of the Java TreeMap/Tree.
Installation
Install with pip:
pip install pytreemap
Documentation
Click here to access the documentation
Basic Usage
This demo aims to show you the basic operations available in this package. Consult the documentation for more details.
Import and instantiate
>>> from pytreemap import TreeMap
>>> tm = TreeMap()
Insert key-value mappings
>>> tm[5] = 'Python is great!'
>>> print(tm)
{5=Python is great!}
>>> tm[10] = 'Java is also nice!'
>>> print(tm)
{5=Python is great!, 10=Java is also nice!}
>>> tm.put(-1, 'We love them both!')
>>> print(tm)
{-1=We love them both!, 5=Python is great!, 10=Java is also nice!}
Search for keys
>>> tm[5]
'Python is great!'
>>> tm[2]
KeyError: 'key not found'
>>> tm.get(2) # No error is raised
Delete key-value mappings
>>> del tm[10]
>>> print(tm)
{-1=We love them both!, 5=Python is great!}
>>> del tm[2]
KeyError: 'key not found'
>>> tm.remove(2) # No error is raised
Check whether some keys exist
>>> 2 in tm
False
>>> -1 in tm
True
>>> tm.contains_key(-1)
True
Iterate over keys/values/entries
>>> [key for key in tm]
[-1, 5]
>>> [key for key in tm.key_set()]
[-1, 5]
>>> [value for value in tm.values()]
['We love them both!', 'Python is great!']
>>> [entry for entry in tm.entry_set()]
[-1=We love them both!, 5=Python is great!]
Testing
Most of the tests from Java that concerned TreeMap are passed. Check out the tests/ directory for more details.
Benchmarks
All benchmarks are done on a laptop with Intel Core i7-7700HQ CPU and 16GB of RAM.
Since this package is an implementation of the Java TreeMap, the benchmarks are focused on comparing the performance between this package and Java’s TreeMap.
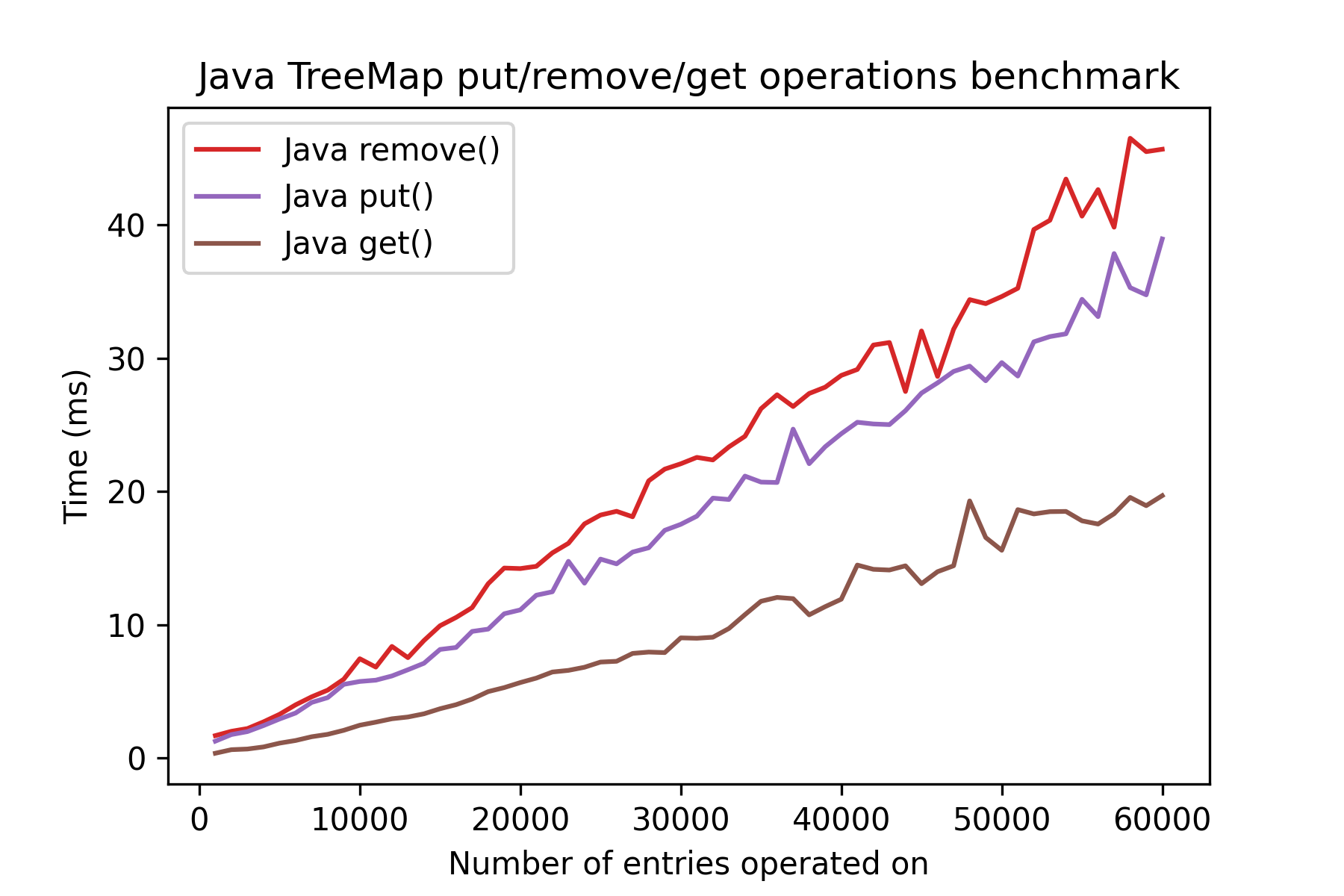
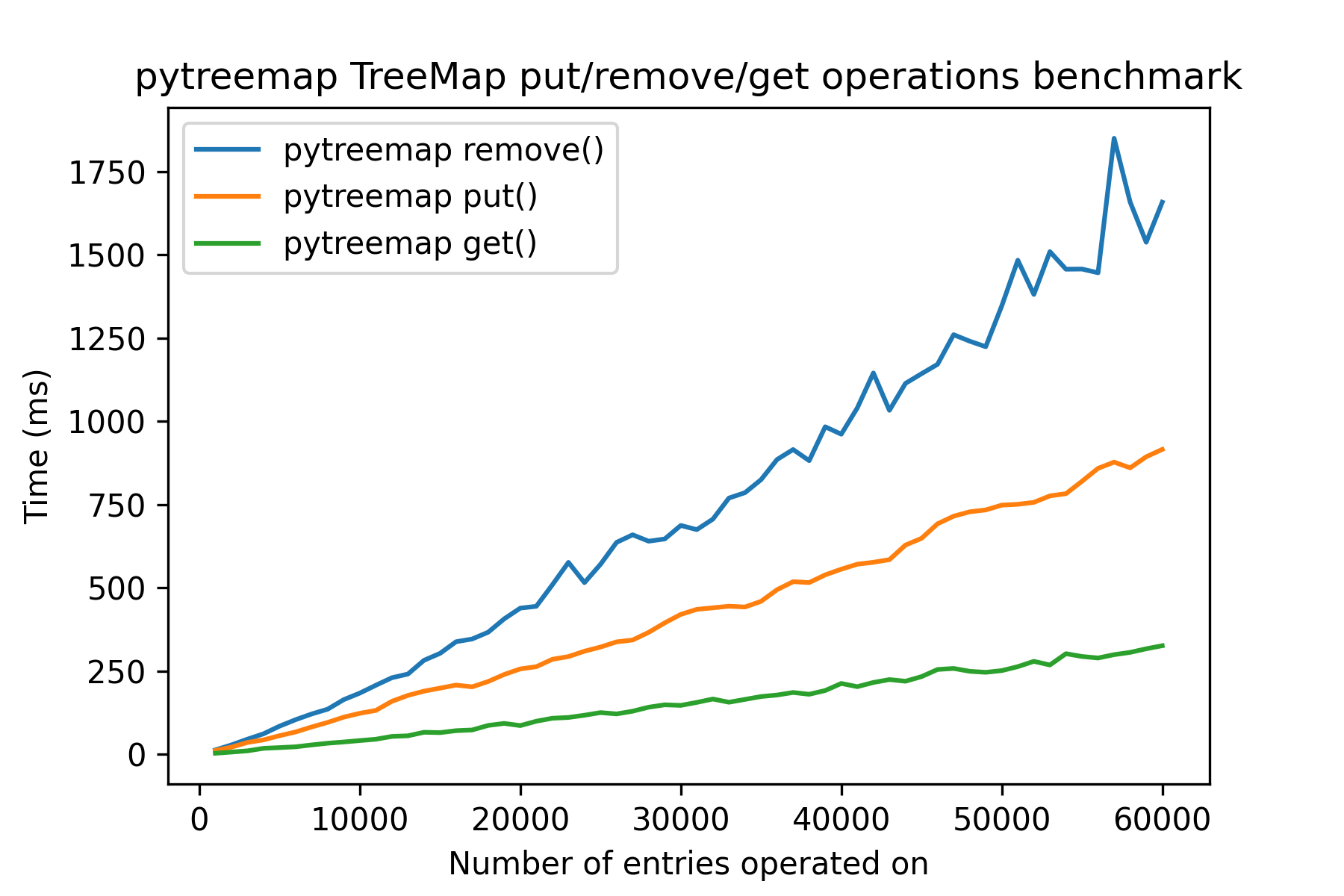
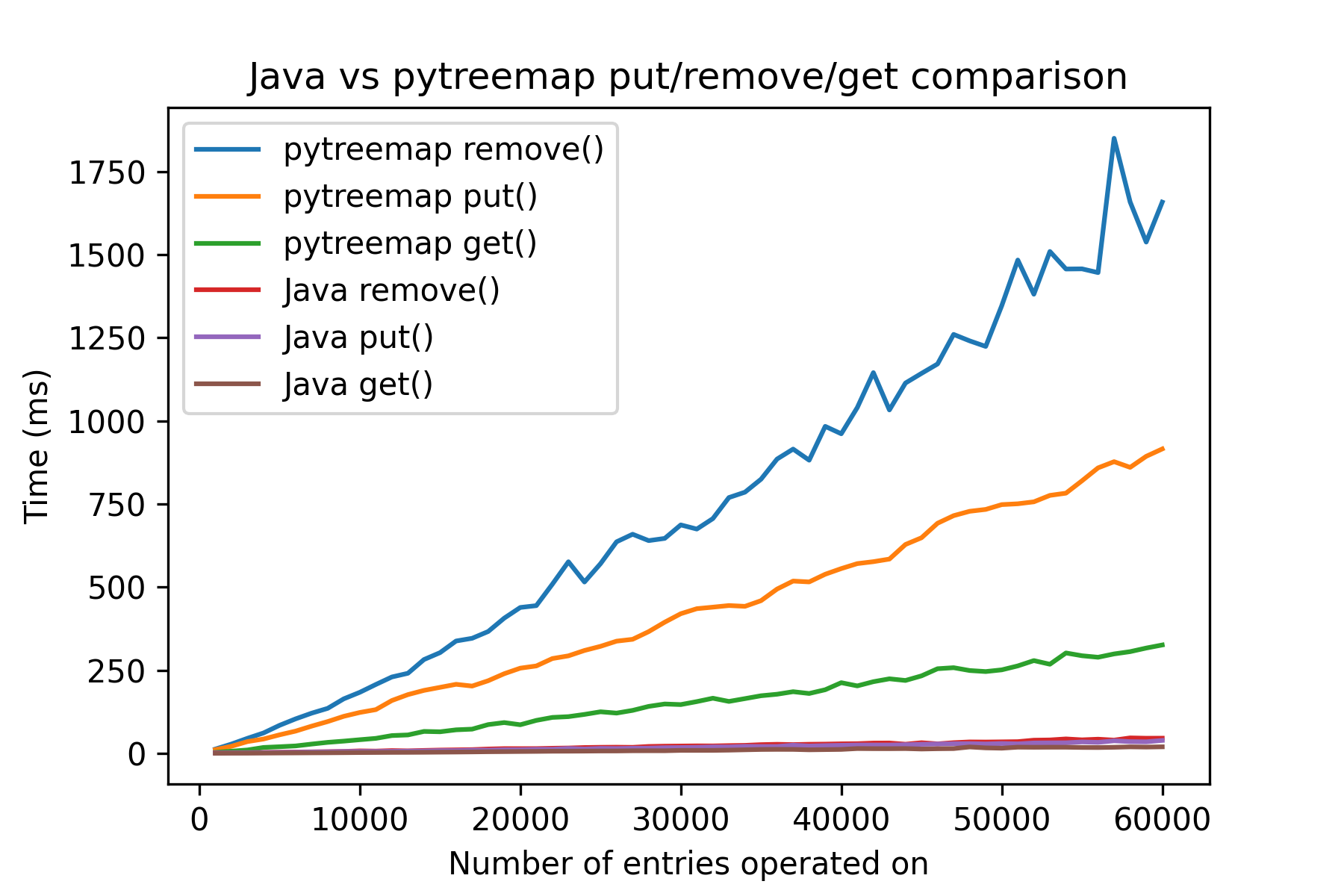
This package is currently written in pure Python and it should come at no surprise that it is much slower than Java, especially when the size of the tree is large.
A Cython version is in the works.
Benchmark procedure:
-
Prepare n entries with distinct keys. (n ranges from 1000 to 60000 with 1000 interval.)
-
Insert/Remove/Search them into the map in random order and record the completion time.
-
Repeat step 1-2 two more times and average the result.
Here is result using Java TreeMap:
And here is the result using pytreemap:
Overlay the plots together, we can see that pytreemap is ~30x slower:


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pytreemap-0.6.tar.gz.
File metadata
- Download URL: pytreemap-0.6.tar.gz
- Upload date:
- Size: 22.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.12.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
978af6c477a319bace967a4f8f0739ee22da9d8889ba3b8a94923c0aeb5ee900
|
|
| MD5 |
0336abfbe1392cfc66488f1c760824f1
|
|
| BLAKE2b-256 |
aae93721fab3eac7641fa204e68ba2f43aa70e5c915042713421b142c1bd8e49
|
File details
Details for the file pytreemap-0.6-py3-none-any.whl.
File metadata
- Download URL: pytreemap-0.6-py3-none-any.whl
- Upload date:
- Size: 32.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.12.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9824d7406ba6158ee9877bf8d7651504565beff5a9ccca1a77d9eed41874faba
|
|
| MD5 |
454d7cbe18e4fbe14eb1ddba8b368eaf
|
|
| BLAKE2b-256 |
fee57b129586595894a6118dd0014d674561fc932394dd532881ad0ab19a15b5
|







