Open source state-of-the-art Chinese word segmentation toolkit

Project description
Pywordseg
基於 BiLSTM 及 ELMo 的 State-of-the-art 開源中文斷詞系統。
An open source state-of-the-art Chinese word segmentation system with BiLSTM and ELMo.
- arXiv paper link: https://arxiv.org/abs/1901.05816
- PyPI page: https://pypi.org/project/pywordseg/
Performance
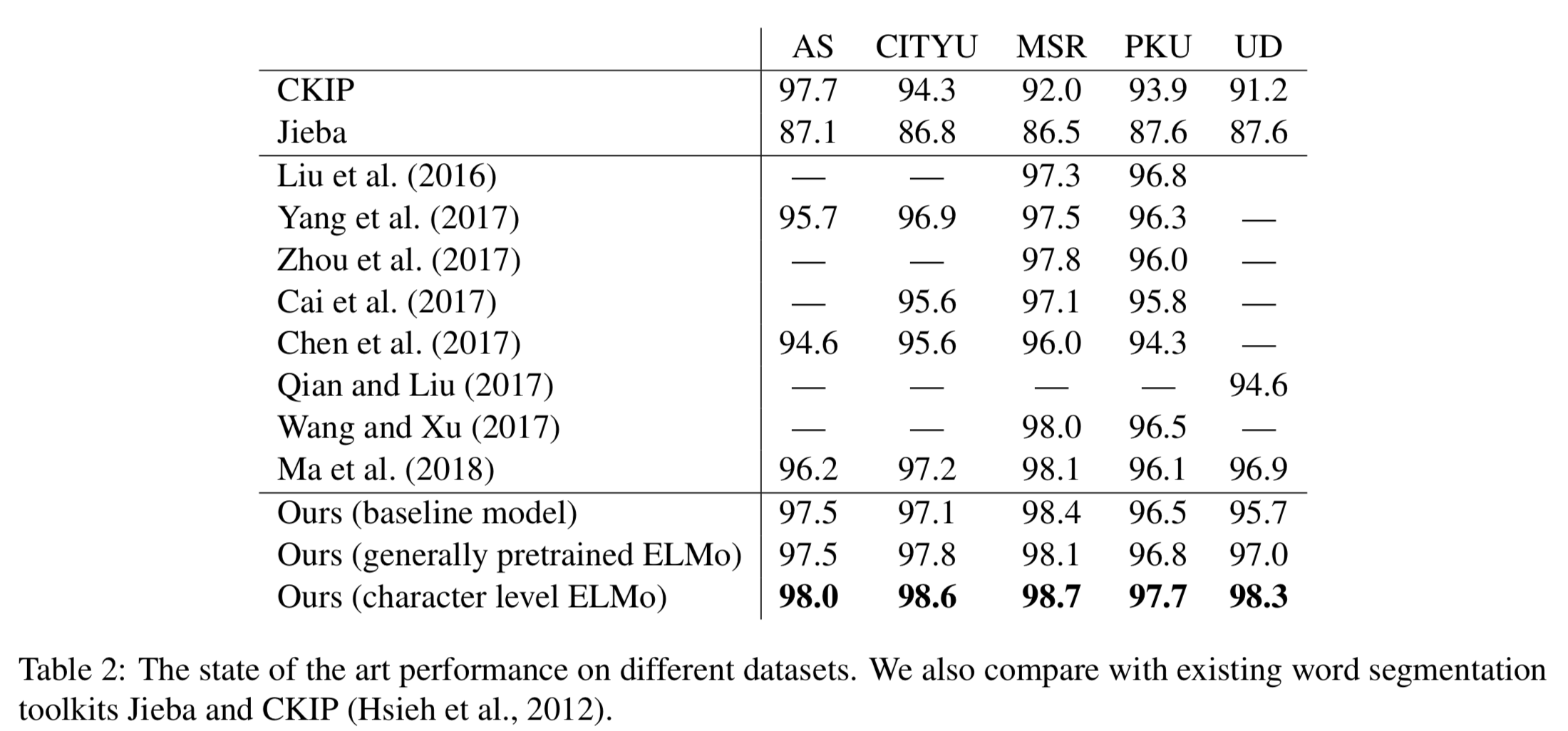
- 此專案提供圖中的 "character level ELMo" model 以及 "baseline" model,其中 "character level ELMo" model 是當前準確率最高。這兩個 model 都贏過目前常用的斷詞系統 Jieba (HMM-based) 及 CKIP (rule-based) 許多。
- This repo provides the "character level ELMo" model and "baseline" model in the figure. Our "character level ELMo" model outperforms the previous state-of-the-art Chinese word segmentation (Ma et al. 2018), and also largely outerform "Jieba" and "CKIP", which are most popular toolkits in processing simplified/traditional Chinese text.
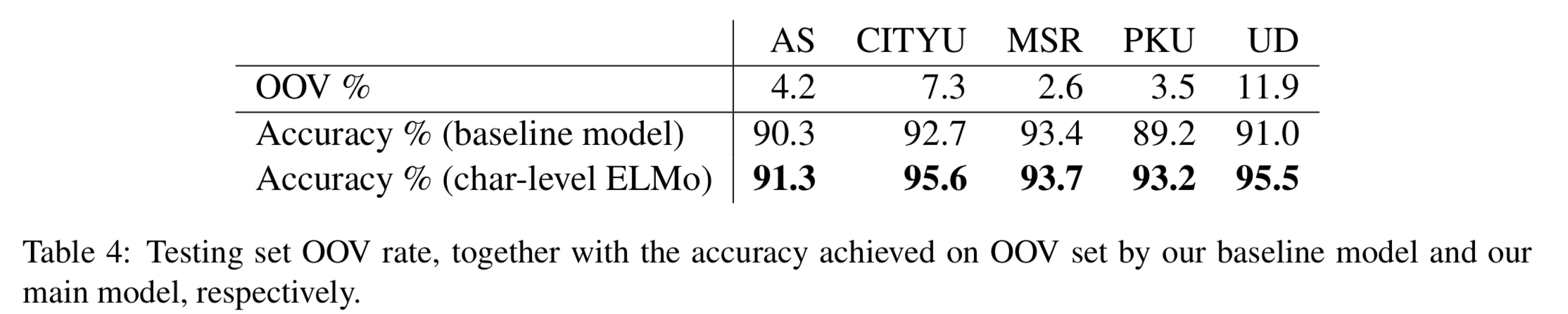
- 當處理訓練時未見過的詞時,"character level ELMo" model 仍然保有不錯的正確率,相較於"baseline" model。
- When considering OOV accuracy, our "character level ELMo" model outperforms our "baseline" model about 5%.
Usage
Requirements
- python >= 3.6 (do not use 3.5)
- pytorch 0.4
- overrides
Install with Pip
$ pip install pywordseg- the module will automatically download the models while your first import within 1 minute.
- if you use MacOS and encounter the urllib.error.URLError problem when downloading your models,
try$ sudo /Applications/Python\ 3.6/Install\ Certificates.commandto bypass the certificate issue.
Install manually
$ git clone https://github.com/voidism/pywordseg- download ELMoForManyLangs.zip and unzip it to the
pywordseg/pywordseg(the code of the ELMo model is from HIT-SCIR, training by myself in character-level) $ pip install .under the main directory
Segment!
# import the module
from pywordseg import *
# declare the segmentor.
seg = Wordseg(batch_size=64, device="cuda:0", embedding='elmo', elmo_use_cuda=True, mode="TW")
# input is a list of raw sentences.
seg.cut(["今天天氣真好啊!", "潮水退了就知道,誰沒穿褲子。"])
# will return a list of lists of the segmented sentences.
# [['今天', '天氣', '真', '好', '啊', '!'], ['潮水', '退', '了', '就', '知道', ',', '誰', '沒', '穿', '褲子', '。']]
Parameters:
- batch_size: batch size for the word segmentation model, default:
64. - device: the CPU/GPU device to run you model, default:
'cpu'. - embedding: (default:
'w2v')'elmo': the loaded model will be the "character level ELMo" model above, which runs slow.'w2v': the loaded model will be the "baseline model" above, which runs faster than'elmo'.
- elmo_use_cuda: if you want your ELMo model be accelerated on GPU, use
True, otherwise the ELMo model will be run on CPU. This param is no use whenembedding='w2v'. default:True. - mode:
WordSegwill load different model according to the mode as listed below: (default:TW)TW: trained on AS corpus, from CKIP, Academia Sinica, Taiwan.HK: trained on CityU corpus, from City University of Hong Kong, Hong Kong SAR.CN_MSR: trained on MSR corpus, from Microsoft Research, China.CN_PKUorCN: trained on PKU corpus, from Peking University, China.
TODO
- 目前只支援繁體中文(即使選擇CN mode,文字也要轉換成繁體才能運作,目前訓練資料都是經過 OpenCC 轉換的),日後會加入簡體中文。
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
pywordseg-0.1.1.tar.gz
(6.9 kB
view details)
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pywordseg-0.1.1.tar.gz.
File metadata
- Download URL: pywordseg-0.1.1.tar.gz
- Upload date:
- Size: 6.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.12.1 pkginfo/1.5.0.1 requests/2.20.1 setuptools/39.0.1 requests-toolbelt/0.8.0 tqdm/4.28.1 CPython/3.6.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6174f5ef53659fb47d3838c3b65bb3263c6a84b0791c96907339279e5d22967b
|
|
| MD5 |
3d8149cf06ae274b23ccd864c601752f
|
|
| BLAKE2b-256 |
a7a53dc4253a25535086182b86fab5cce70d583c882d930de061d880fc5156ea
|
File details
Details for the file pywordseg-0.1.1-py3-none-any.whl.
File metadata
- Download URL: pywordseg-0.1.1-py3-none-any.whl
- Upload date:
- Size: 8.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.12.1 pkginfo/1.5.0.1 requests/2.20.1 setuptools/39.0.1 requests-toolbelt/0.8.0 tqdm/4.28.1 CPython/3.6.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5f514e7c27473410681c0479bcb70b148e5b05f07d1b8e0ede3ac4b26393ad51
|
|
| MD5 |
ab164bf29dc4800375add56b18996291
|
|
| BLAKE2b-256 |
1e1570fb05edefee2bad4607f086c601c1eda8e2d7657e8f6503266c92bf44d0
|







