Quasi-Quantum Annealing (QQA): a general-purpose GPU solver for combinatorial and spin-glass optimization, with PI-GNN/CPRA and a parallel SA baseline.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
Parallel Quasi-Quantum Annealer (PQQA)
A research-grade PyTorch toolkit for continuous-relaxation combinatorial optimisation. PQQA unifies the recent line of work that lifts a discrete CO problem into a continuous space and then solves it with gradient descent — PQQA (ICLR 2025), the CRA-PI-GNN baseline (NeurIPS 2024) and the CPRA diverse-solution framework (TMLR 2025) — behind a single, GPU-friendly API. One installation gives you the PQQA solver, an optional GNN backend that plugs in CRA-PI-GNN-style methods, GPU-parallel SA and Population Annealing baselines for honest comparisons, a 20+ class problem catalogue, a Streamlit dashboard and a CLI.
The package is published on PyPI as qqa for backwards compatibility
with earlier QQA4CO releases (import qqa).









Benchmark data ·
huggingface.co/datasets/Yuma-Ichikawa/qqa4co-bench
DISCS (NeurIPS 2023) + MaxCut G-set (Helmberg & Rendl 2000) + Graph Coloring (COLOR) + MIS on d-regular random graphs (PQQA §5.1) + 3D Edwards-Anderson spin glass + Balanced k-way partition — one HF dataset, make bench-all-setup pulls everything.
🌐 Try the Web dashboard — zero install, runs in your browser
→ parallelquasiquantum4co.streamlit.app · hosted on Streamlit Community Cloud · CPU back-end · light / dark mode
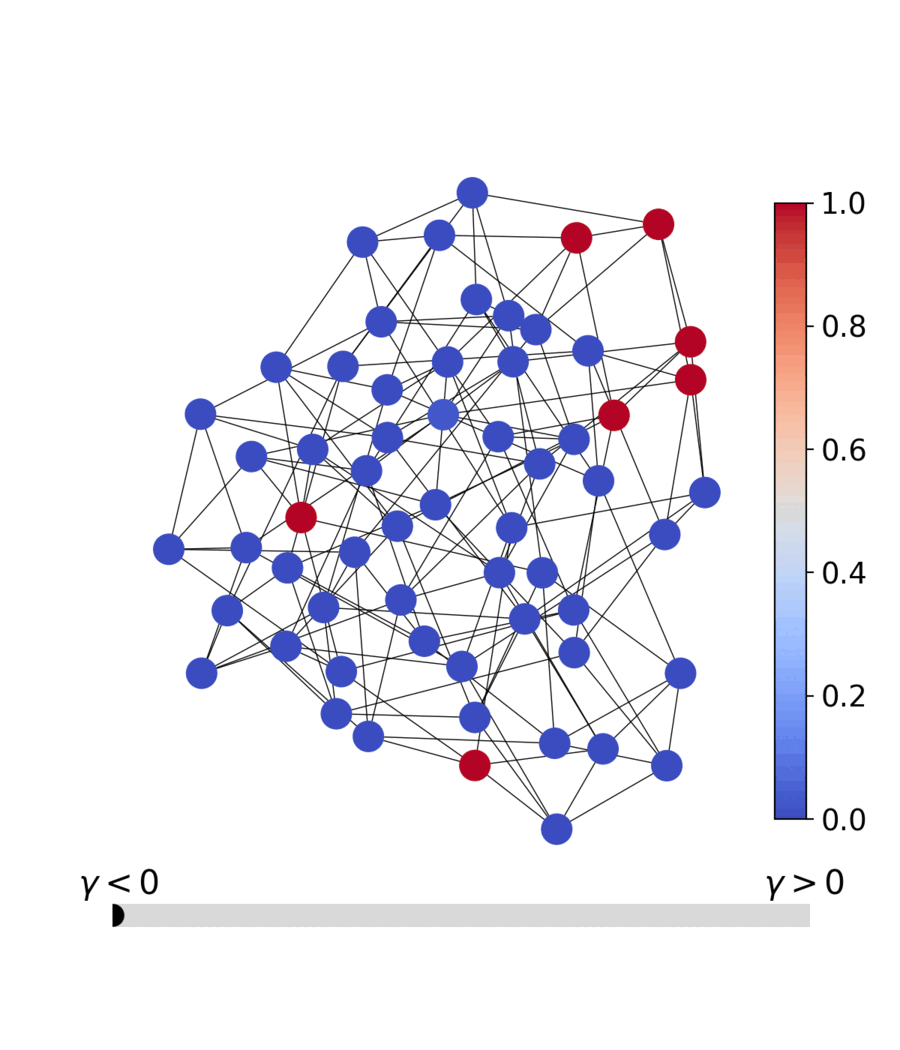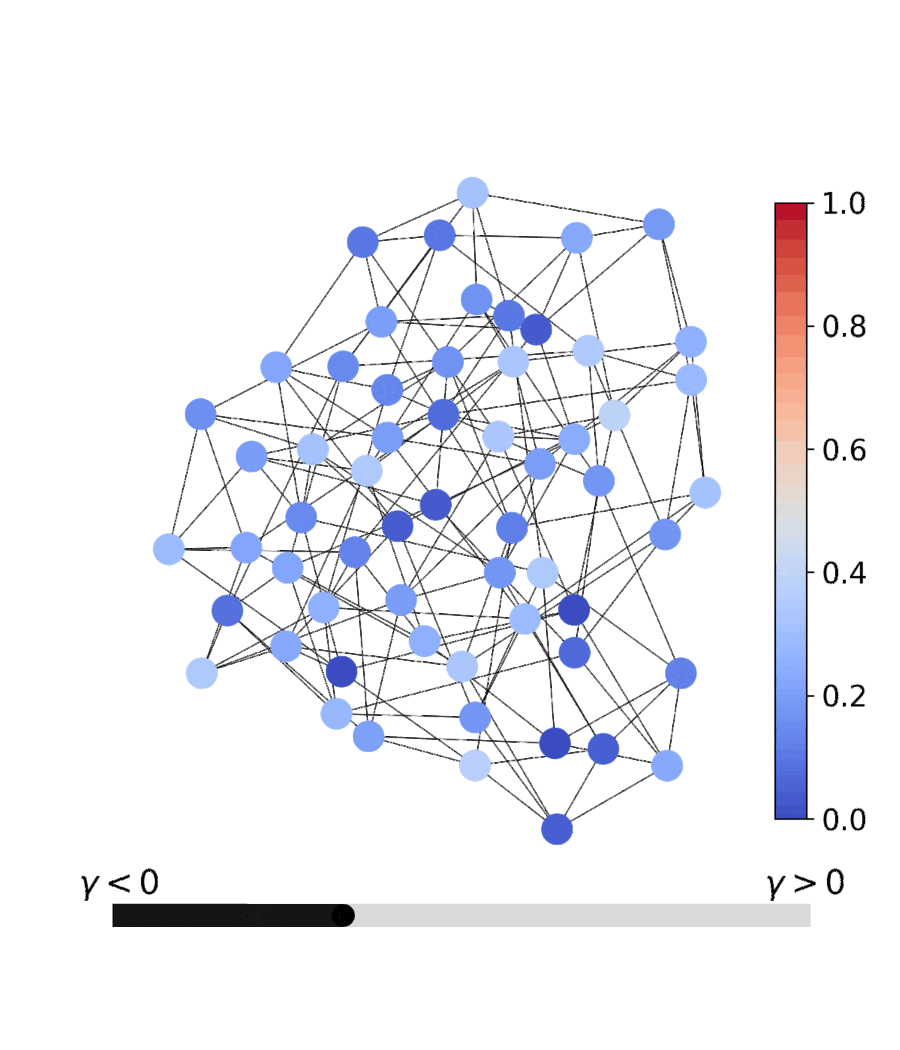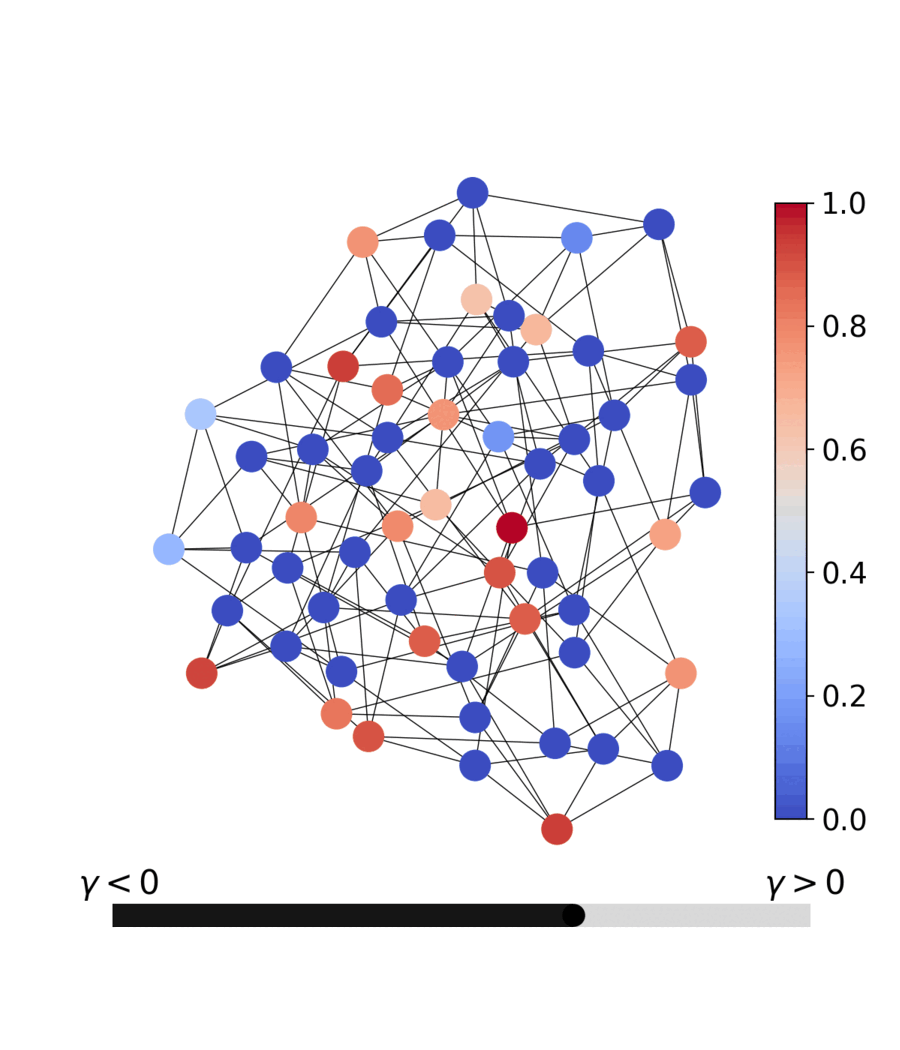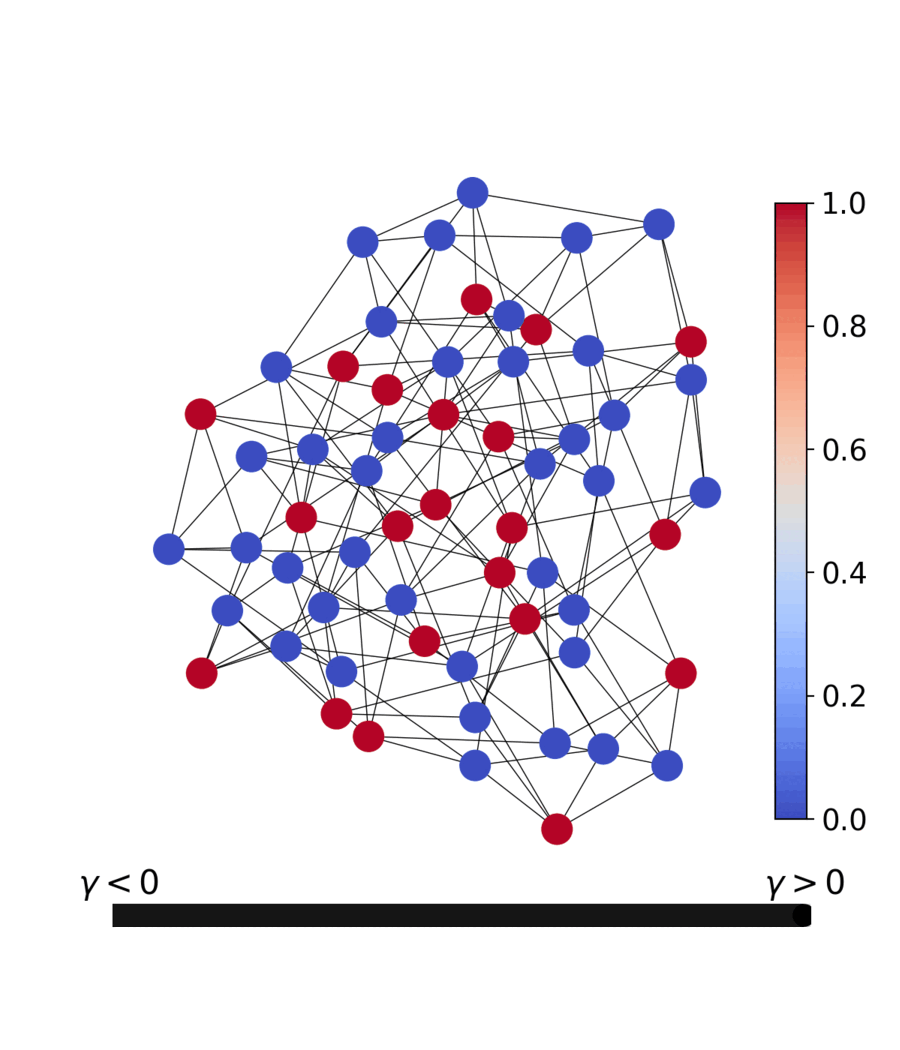
The dashboard is a four-page Streamlit app that drives the same qqa.anneal
solver this README documents — pick a problem, watch the relaxed variables
discretise live, race PQQA against simulated annealing, and inspect the
parallel population in 3D solution-space PCA / loss-spectrogram views.
| Page | What you can do |
|---|---|
| Home | Pick from 19 problems (MIS, Max-Cut, MaxClique, Vertex Cover, GraphBisection, MinDominatingSet, Coloring, BalancedGraphPartition, TSP, QAP, NQueens, Knapsack, NumberPartitioning, MaxSAT3, 1D Ising, Edwards–Anderson, SK, p-spin, RFIM, BinaryPerceptron, HopfieldMemory). Auxiliary sliders are problem-aware. |
| Solve | Run PQQA / CRA-PI-GNN / CPRA with live progress, polish (1-flip local search) and warm-start toggles, and a per-problem solution viewer (TSP tour, NQueens board, highlighted IS, colouring, …). |
| Visualize | 10 tabs of post-hoc plots — solution-space PCA of the final parallel population (3D, replicas coloured by loss, global best highlighted), loss spectrogram over time, diversity, replica fate, schedule, ridgeline. |
| Compare | Hyper-parameter grid sweep with parallel-coordinates view, and a head-to-head PQQA vs. SA vs. Population-Annealing shootout that reports the wall-clock speed-up at matched compute budget. |
Or run it locally — same UI, your hardware
pip install "qqa[gui]" # pulls Streamlit + Plotly
qqa gui # opens http://localhost:8501
Or with uv:
uv sync --extra gui
uv run qqa gui
CUDA is picked up automatically when available.
What's in the box
- The PQQA solver (
qqa.anneal) — a parallel, population-based annealer that lifts any QUBO / Ising / categorical / permutation problem into a continuous relaxation and minimises it with gradient descent + diversity regularisation. CPU / CUDA / MPS, deterministic withqqa.fix_seed. - A 20+ class problem catalogue spanning QUBO graphs (MIS, Max-Cut,
MaxClique, Vertex Cover, Graph Bisection, Minimum Dominating Set),
classic CO (Knapsack, NumberPartitioning, MaxSAT3), permutation problems
(TSP, QAP, NQueens), categorical/assignment (graph Coloring, Balanced
K-way Partition), spin glasses (1D Ising, Edwards-Anderson 2D/3D, SK,
p-spin, Random-Field Ising) and statistical-physics models
(BinaryPerceptron, HopfieldMemory). Every class implements the same
loss_fn/score_summarycontract, so the solver, CLI and dashboard are completely problem-agnostic. - An optional GNN backend (
qqa.pignn, install withqqa[pignn]) that plugs GNN-based unsupervised-learning CO solvers into the same API. PQQA, the CRA-PI-GNN baseline (NeurIPS 2024) and the CPRA diverse-solution framework (TMLR 2025) all shareAnnealResult,score_summary, the same problem builders and the same CLI flags — A/B comparing methods is one--backendswitch away. - GPU-parallel MCMC baselines for honest head-to-head comparisons —
classical Simulated Annealing (
qqa.simulated_annealing) with a QUBO Glauber fast path, and Population Annealing (qqa.population_annealing, Hukushima-Iba / Machta) with systematic or multinomial resampling between temperature steps. Both expose the samebest_sol/best_obj/historysurface asqqa.anneal, so the Streamlit Compare page can race PQQA against either at a matched compute budget. - A polished Streamlit dashboard (light / dark, live progress, parallel
population view, per-problem solution viz, hyper-parameter sweeps) and a
qqaCLI (solve / bench / gui / version) for reproducible experiments. A hosted instance lives at https://parallelquasiquantum4co.streamlit.app/. - MkDocs + Material reference docs with auto-generated API pages, a
runnable
examples/notebook gallery (Open-in-Colab badges) and ascripts/verify_all_problems.pycorrectness sweep that benchmarks every problem against ground truth or a strong baseline (29 / 29 instances pass in the latest sweep — seedocs/verification.md).
Reference papers
QQA4CO implements and unifies the following peer-reviewed work:
-
Optimization by Parallel Quasi-Quantum Annealing with Gradient-Based Sampling — Yuma Ichikawa. International Conference on Learning Representations (ICLR), 2025. [OpenReview] The headline PQQA algorithm — parallel quasi-quantum annealing with gradient-based sampling. Implemented as
qqa.anneal. -
Continuous Parallel Relaxation for Finding Diverse Solutions in Combinatorial Optimization Problems — Yuma Ichikawa, Hiroaki Iwashita. Transactions on Machine Learning Research (TMLR), 2025. [OpenReview] The CPRA framework — generates penalty- and structure-diversified solutions from a single training run.
-
Controlling Continuous Relaxation for Combinatorial Optimization — Yuma Ichikawa. Neural Information Processing Systems (NeurIPS), 2024. [OpenReview] · [NeurIPS poster] The CRA-PI-GNN GNN-based unsupervised-learning solver. Ported to PyTorch Geometric and exposed under
qqa.pignn.
Install
With uv (recommended for development):
git clone https://github.com/Yuma-Ichikawa/QQA4CO.git && cd QQA4CO
uv sync # core only
uv sync --extra plotly --extra gui --extra dev # everything
uv run pytest -q # sanity check
With pip:
pip install qqa # core
pip install "qqa[plotly]" # + interactive plots
pip install "qqa[gui]" # + Streamlit dashboard
pip install "qqa[all]" # everything
Quickstart
import networkx as nx
import qqa
qqa.fix_seed(0)
g = nx.random_regular_graph(d=3, n=100, seed=0)
problem = qqa.MaximumIndependentSet(g, penalty=2)
result = qqa.anneal(problem, sol_size=100, num_epochs=1500)
print(f"MIS size: {-int(result.best_obj)} in {result.runtime:.2f}s")
The same call style applies to spin systems:
problem = qqa.SherringtonKirkpatrick(N=100, seed=0)
result = qqa.anneal(problem, sol_size=200, num_epochs=2000, verbose=False)
print(f"E_0 / N ≈ {result.best_obj / 100:.4f} (target ≈ -0.7632)")
Optional CRA-PI-GNN backend (PyTorch Geometric)
QQA4CO ships an optional PyTorch Geometric port of the CRA-PI-GNN
solver from Ichikawa, NeurIPS 2024 — "Controlling Continuous Relaxation
for Combinatorial Optimization" (paper,
reference DGL implementation).
This lets you compare against CRA-PI-GNN from the same codebase as QQA, on
hardware that the original DGL stack does not yet target (e.g. NVIDIA
Blackwell B200 / sm_100).
Install with the pignn extra (pulls in torch-geometric):
pip install "qqa[pignn]"
Python API — drop-in alternative to qqa.anneal, returns the same AnnealResult:
import networkx as nx
import qqa
from qqa.pignn import train_cra_pi_gnn
qqa.fix_seed(0)
g = nx.random_regular_graph(d=3, n=200, seed=0)
problem = qqa.MaximumIndependentSet(g, penalty=2)
result = train_cra_pi_gnn(
problem,
learning_rate=1e-3,
init_reg_param=-2.0,
annealing_rate=5e-4,
num_epochs=5000,
)
print(result.score) # {'label': 'IS size', 'value': ..., 'feasible': True, ...}
CLI — same problem builders, just add --backend pignn:
qqa solve --problem mis --size 200 --backend pignn \
--learning-rate 1e-3 --pignn-init-reg-param -2 \
--pignn-annealing-rate 5e-4 --epochs 5000
Supported problems for the PyG backend: mis, maxcut, maxclique,
vertex_cover, graph_bisection (anything QUBO-on-a-graph). For spin
glasses, TSP, perceptron, etc. use the default qqa.anneal.
CPRA — diverse solutions in a single run (TMLR 2025)
The same qqa[pignn] extra also installs CPRA (Continual Parallel
Relaxation Annealing) from Ichikawa & Iwashita, TMLR 2025 —
"Continuous Parallel Relaxation for Finding Diverse Solutions in
Combinatorial Optimization Problems"
(paper,
reference repo). CPRA shares
QQA4CO's GCN backbone with CRA-PI-GNN but exposes R parallel output
heads, so a single training run produces R diverse continuous
solutions. Two diversification regimes are supported out of the box:
- Penalty diversification — pass one problem instance per replica
(e.g. MIS with different penalty weights) to sweep a hyperparameter
in one shot instead of training
Rseparate models. - Variation diversification — leave
replica_problems=Noneand setvari_param > 0to add the inter-replica diversity term-R · Σᵢ stdᵣ(p_{i,r}), pulling replicas apart on the same problem.
Python API:
import networkx as nx
import qqa
from qqa.pignn import train_cpra_pi_gnn
qqa.fix_seed(0)
g = nx.random_regular_graph(d=3, n=200, seed=0)
base = qqa.MaximumIndependentSet(g, penalty=2)
# Penalty diversification: 4 replicas, one per penalty level.
penalties = [1.5, 2.0, 2.5, 3.0]
replica_problems = [qqa.MaximumIndependentSet(g, penalty=p) for p in penalties]
result = train_cpra_pi_gnn(
base,
num_replicas=len(replica_problems),
replica_problems=replica_problems,
learning_rate=1e-3,
init_reg_param=-2.0,
annealing_rate=5e-4,
num_epochs=5000,
)
# Inspect every replica, not only the best one.
for record in result.score["extra"]["replicas"]:
r, score = record["replica"], record["score"]
print(f"replica {r}: |IS|={score['value']} feasible={score['feasible']}")
Variation diversification on a fixed problem is the same call without
replica_problems and a positive vari_param:
result = train_cpra_pi_gnn(
qqa.MaxCut(g),
num_replicas=4,
vari_param=0.4, # encourages between-replica spread
learning_rate=1e-3,
init_reg_param=-2.0,
annealing_rate=5e-4,
num_epochs=5000,
)
CLI — same problem builders, add --backend cpra:
qqa solve --problem mis --backend cpra --size 200 \
--cpra-num-replicas 4 \
--cpra-penalty-levels 1.5,2.0,2.5,3.0 \
--learning-rate 1e-3 --pignn-init-reg-param -2 \
--pignn-annealing-rate 5e-4 --epochs 5000
--cpra-penalty-levels is currently supported for --problem mis and
--problem vertex_cover (the QUBO classes that accept a penalty=...
constructor kwarg). For variation diversification on any other graph
problem, drop --cpra-penalty-levels and pass --cpra-vari-param 0.4
instead. All --pignn-* flags above (--pignn-init-reg-param,
--pignn-annealing-rate, --pignn-tol, --pignn-patience,
--pignn-hidden, --pignn-no-annealing) apply unchanged to the CPRA
backend.
The returned AnnealResult carries the best replica's discrete
solution in best_sol / best_obj; every replica's solution and score
are stored in result.score["extra"]["replicas"], and per-epoch
per-replica objectives in result.history["per_replica_obj"] (shape
(epochs, R)) for downstream plotting.
When to use which
| Use case | Recommended |
|---|---|
| Most CO and spin-glass problems (default) | qqa.anneal |
| Reproducing the NeurIPS 2024 CRA-PI-GNN paper | qqa.pignn.train_cra_pi_gnn |
| Reproducing the TMLR 2025 CPRA paper / sweep penalties in one run | qqa.pignn.train_cpra_pi_gnn |
| Spin glasses, perceptron, Hopfield, TSP, coloring | qqa.anneal (PyG backend not supported) |
| Need parallel replicas + diversity term (gradient-based sampler) | qqa.anneal |
| Need a single deterministic GNN solver for ablation comparison | qqa.pignn.train_cra_pi_gnn |
| Need diverse GNN solutions (penalty- or variation-diversified) in one run | qqa.pignn.train_cpra_pi_gnn |
Empirical comparison (CPU, single thread)
Both solvers given the same instance and seed; QQA uses default 100 parallel
replicas, CRA-PI-GNN uses 5000 epochs of single-replica GCN training. Numbers
from scripts/bench_qqa_vs_pignn.py on the bundled CPU runner:
| Instance | qqa.anneal (IS, runtime) |
qqa.pignn.train_cra_pi_gnn (IS, runtime) |
|---|---|---|
| MIS, N=100, d=3-reg | 43, 5.9 s | 2†, 12.7 s |
| MIS, N=300, d=3-reg | 125, 8.1 s | 126, 201 s |
| MIS, N=500, d=20-reg | 29, 8.2 s | 1†, 414 s |
† CRA-PI-GNN collapsed to a near-trivial solution under the README's
"medium-graph" hyperparameters. The paper's headline numbers use a
larger init_reg_param (e.g. -20) and longer schedule for N >= 1000;
small / dense graphs need per-instance retuning. QQA is robust to
hyperparameter choice across all three rows.
Takeaways
- For raw quality and wall-clock speed,
qqa.annealis the recommended default. Its parallel-replica diversity makes it far less hyperparameter- sensitive than CRA-PI-GNN. - CRA-PI-GNN is included so users can A/B against the paper from one
installation and one device. On its native large-graph regime
(
N >= 1000,dlow, paper defaults) it produces competitive solutions — but see the original CRA4CO repository for the canonical DGL implementation.
Problem catalog
| Category | Classes |
|---|---|
| Binary QUBO | MaximumIndependentSet, MaxClique, MaxCut (+ *Instance batched variants) |
| Binary (classic CO) | Knapsack, NumberPartitioning, VertexCover, GraphBisection, MaxSAT3 |
| Categorical | Coloring, BalancedGraphPartition |
| Categorical (permutation) | TSP, QAP, NQueens |
| 1D Ising | Ising1D |
| Spin glass | EdwardsAnderson, SherringtonKirkpatrick |
| Statistical physics | BinaryPerceptron, HopfieldMemory |
Every class implements score_summary(x_disc) -> dict so the CLI and GUI can
report a human-readable metric ("IS size: 22", "packed value: 358",
"tour length: 3.28") and a feasibility flag alongside the raw loss. Full
mathematical definitions live in docs/problems.md.
Command-line interface
qqa version
qqa solve --problem sk --size 100 --sol-size 128 --epochs 1000
qqa solve --problem mis --graph-file mygraph.gpickle --epochs 1500
qqa bench --preset er-small --epochs 500
qqa gui # opens http://localhost:8501
Run qqa <command> --help for the full option list.
All CO benchmarks in one command (DISCS + G-set + PQQA + EA3D)
Every benchmark instance lives on the Hugging Face Hub:
Dataset:
huggingface.co/datasets/Yuma-Ichikawa/qqa4co-bench· DISCS (MaxCut / MIS / MaxClique / NormCut) + MaxCut G-set (Helmberg & Rendl 2000, 71 graphs G1-G67 + G70/72/77/81) + Graph Coloring (COLOR) + MIS on d-regular random graphs (PQQA §5.1) + 3D Edwards-Anderson spin glass + Balanced k-way partition — one repo,make bench-all-setuppulls everything.
Third parties benchmark a solver in three one-liners:
pip install -e ".[discs,dev]"
make bench-all-setup # 1. fetch every family from HF Hub
qqa bench-run --suite all --output mine.json # 2. run your solver
qqa bench-plot bench_results/mine.json --output report.png # 3. render the report
Outputs land under ./bench_results/ (git-ignored). For an A/B plot
against a baseline, pass multiple JSON files to qqa bench-plot:
qqa bench-plot bench_results/qqa.json bench_results/sa.json \
--labels "QQA (ours)" "SA baseline" \
--title "QQA vs SA on the CO suite" \
--output ab.png
qqa bench-list prints every suite id that is resolvable from the
current ./data/ tree:
qqa bench-list # nested tree
qqa bench-list --as-suites # one --suite id per line (for scripting)
--suite is longest-prefix-matched, so compound family names work
(e.g. mis-rrg-rrg-d20_n10000, balanced-partition-nets-MNIST).
Python API (same entry points as the CLI, with full keyword arg coverage):
from qqa import bench
bench.list_suites() # dict view of available suites
bench.run("mis-satlib", instances=3, output="mine.json")
bench.plot(["bench_results/mine.json"], output="report.png")
The scripts/setup_benchmarks.sh helper also supports --source local
to re-generate the procedural families offline, and
--only coloring,ea3d / --skip discs to cherry-pick families.
The original DISCS-only path (make bench-discs-setup,
make bench-discs-smoke, etc.) is still available and unchanged.
Reproducing the PQQA paper (Ichikawa, NeurIPS 2024 — arXiv:2409.02135).
The bench CLI exposes every paper-relevant hyper-parameter
(--learning-rate, --temp, --curve-rate, --gamma-min/max,
--div-param, --penalty). A preset target wires them to the PQQA
"fewer / S=100" recipe (Table 1, SATLIB MIS):
make bench-discs-paper SUITE=mis-satlib-uf DEVICE=cuda PARALLEL=1
# Override SOL_SIZE / NUM_EPOCHS / LEARNING_RATE for other paper rows:
make bench-discs-paper SUITE=mis-satlib-uf DEVICE=cuda PARALLEL=1 \
SOL_SIZE=1000 NUM_EPOCHS=30000 # "more steps, S=1000" row
The best_known field for SATLIB MIS is the optimum independent set
size derived from the underlying 3-SAT clause count (mean = 425.96 over
500 instances), which matches the KaMIS baseline reported in Table 1.
NormCut is not a benchmark in the PQQA paper — it is an additional
DISCS suite included for completeness.
See data/discs/README.md for the full layout,
optional Hugging Face source, the qqa.datasets.discs_* Python loaders,
and the batched-instance (parallel=True) API.
Planted-solution factorization Ising/QUBO benchmark (Hen 2026)
A second, complementary benchmark is the planted-solution
factorization Ising of Hen, Planted-solution SAT and Ising
benchmarks from integer factorization (arXiv:2604.09837, 2026). The
construction encodes N = p · q as a circuit of AND/XOR Ising
gadgets whose unique ground state is the bit-string of (p, q), so
every solver claim is verifiable against the known optimum.
import qqa
prob = qqa.IntegerFactorizationIsing(p=11, q=13) # N = 143
result = qqa.anneal(prob, sol_size=500, num_epochs=3000,
learning_rate=0.5,
schedule=qqa.LinearBGSchedule(min_bg=-2, max_bg=0.5))
print(result.score["extra"]["p_hat"], result.score["extra"]["q_hat"])
uv run python scripts/bench_factorization.py --bits 4 --instances 5
See data/factorization/README.md for
the construction details, scaling table, and the citation.
Visualising benchmark results
qqa bench-plot (or the underlying scripts/plot_benchmarks.py) turns
any qqa bench-run --output *.json payload into a polished
publication-quality report image with four panels chosen so each
one surfaces a different failure mode — improvements or regressions
become impossible to miss.
# one run, default layout
qqa bench-plot bench_results/mine.json --output report.png
# A/B comparison (baseline vs. your new method)
qqa bench-plot bench_results/baseline.json bench_results/mine.json \
--labels "baseline" "my method" --output ab.png
# dark theme for talks
qqa bench-plot bench_results/mine.json --theme dark --output dark.png
# Makefile shortcut (still available)
make bench-plot JSON=bench_results/mine.json
The image has a persistent header / KPI band / footer plus four data panels:
| panel | what it shows |
|---|---|
| Radar chart | mean approximation ratio on one axis per family, with filled polygons and per-family colours that carry into every other panel. Spokes below 1.0 reveal families where the solver has no signal. |
| Per-subset bars | horizontal bars of mean ratio per <family>/<subset>, sorted, with a light family-colour band behind each group. Catches subset-level regressions that the radar would average out. |
| Feasibility bars | share of replicas satisfying constraints per subset — lets a penalised QUBO admit a high objective while flagging that it was infeasible. |
| Per-instance violin | KDE violin + median + jittered strip of every replica, so variance, skew and per-instance outliers are visible at a glance. |
The --theme light|dark switch controls the palette (Okabe-Ito
colour-blind-safe methods + stable per-family hues). Output formats
follow the extension (.png / .svg / .pdf); use --format to
force. Only depends on matplotlib + numpy (core QQA4CO deps).

Streamlit dashboard
pip install "qqa[gui]" && qqa gui
| Page | Purpose |
|---|---|
| Home | Pick a problem family (Graph, Classic CO, Categorical/permutation, Physics), size, seed, and problem-specific parameters. |
| Solve | Configure QQA hyper-parameters, launch a run with a live progress bar, mean ± σ loss band over parallel replicas, population heatmap, diversity curve, score card. |
| Visualize | Tabbed views: dynamics, best trajectory, schedule, solution heatmap, parallel population, PCA trajectory, ridgeline, per-replica fate. |
| Compare | Sweep a small hyper-parameter grid; inspect with parallel coordinates and overlaid trajectories. |
A light/dark toggle lives in the sidebar; both themes share an academic, Plotly-aware palette. A hosted instance runs at https://parallelquasiquantum4co.streamlit.app/.
Deploy your own (free)
The repository ships everything Streamlit Community Cloud needs:
requirements.txt (CPU-only PyTorch),
runtime.txt (Python pin),
.streamlit/config.toml (theme + telemetry off).
- Sign in at https://share.streamlit.io with GitHub.
- New app → repository
Yuma-Ichikawa/QQA4CO, branchmain, main fileapp/streamlit_app.py, then Deploy. - In the app's
⋮→ Settings → Sharing, set "Who can view this app?" to "Anyone with the link can view". Without this every visitor is redirected to Streamlit SSO.
Re-deploys happen automatically on every push to main. The full runbook,
common failure modes, and the health-check endpoint live in
deploy/STREAMLIT_DEPLOY.md. Verify with:
uv run python scripts/check_streamlit_deploy.py
The custom-problem editor is off by default on public deployments
(it evaluates arbitrary Python via exec). Re-enable it on a trusted
machine with QQA_ALLOW_CUSTOM=1 uv run qqa gui.
Other free / cheap targets
The repository drops onto any of the usual platforms unchanged:
- Hugging Face Spaces (Streamlit SDK) — persistent URL, free CPU tier, HTTPS by default.
- Fly.io / Render — Docker-based; entry point
app/streamlit_app.py, depsrequirements.txt. - Google Cloud Run — container image, pay-per-request.
Each platform issues a permanent HTTPS URL out of the box.
Visualization
from qqa import visualization as viz
viz.plot_history(result) # loss / penalty / diversity
viz.plot_best_trajectory(result, backend="plotly")
viz.plot_schedule(qqa.LinearBGSchedule(-2, 0.1), num_epochs=2000)
viz.plot_run_comparison([r1, r2, r3], labels=["lr=1", "lr=0.5", "lr=2"])
viz.plot_solution_heatmap(result, problem)
Every helper accepts backend="matplotlib" (default) or backend="plotly".
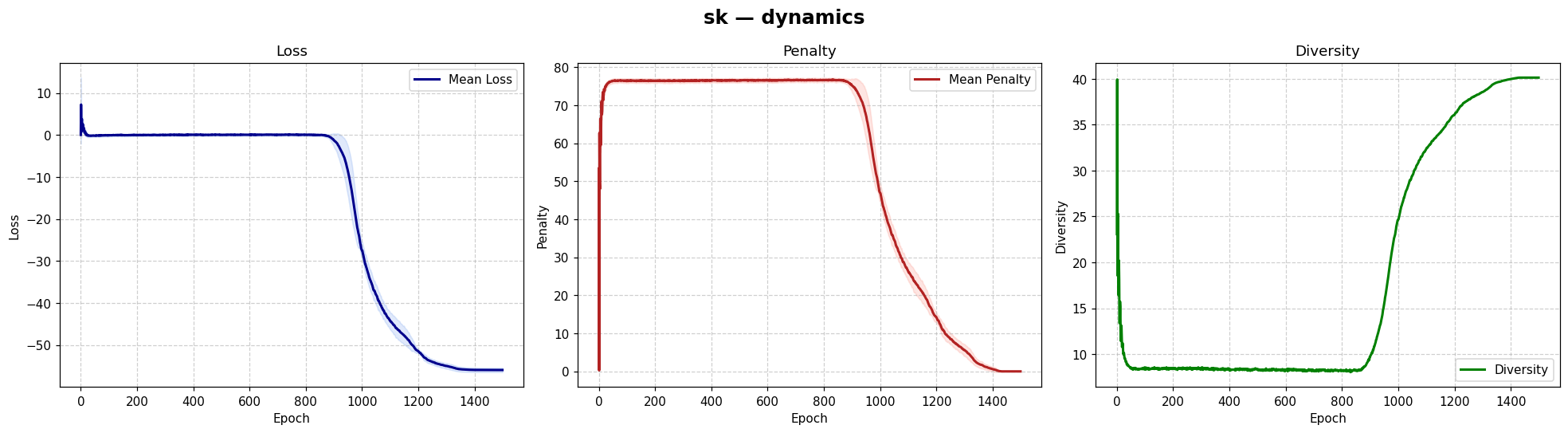
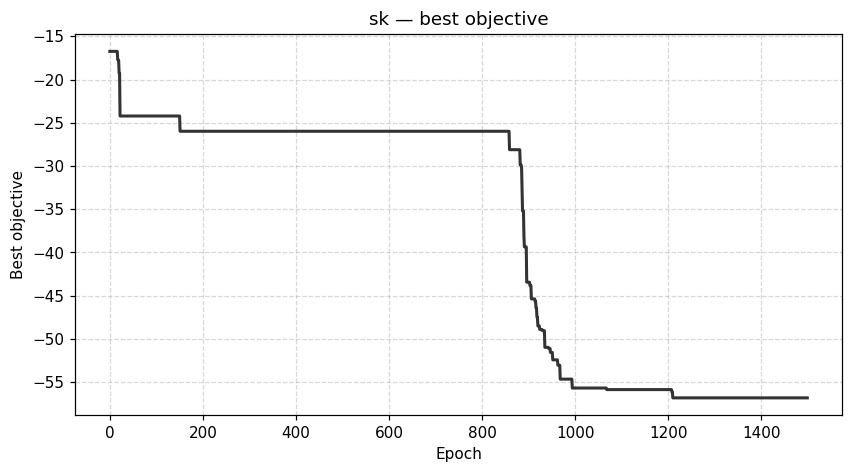
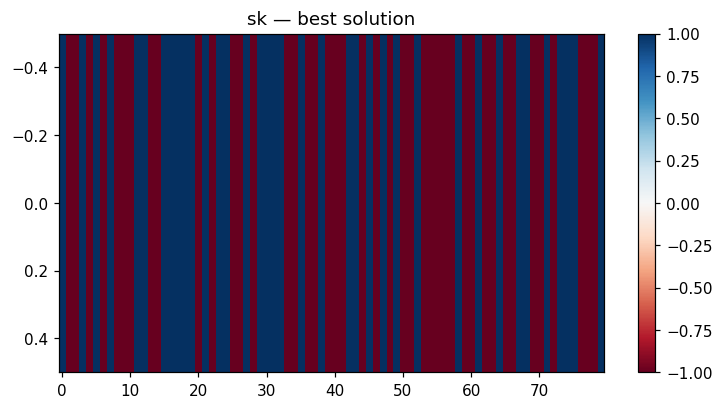
| Dynamics | Best trajectory | Best solution | Parallel population |
|---|---|---|---|
 |
 |
 |
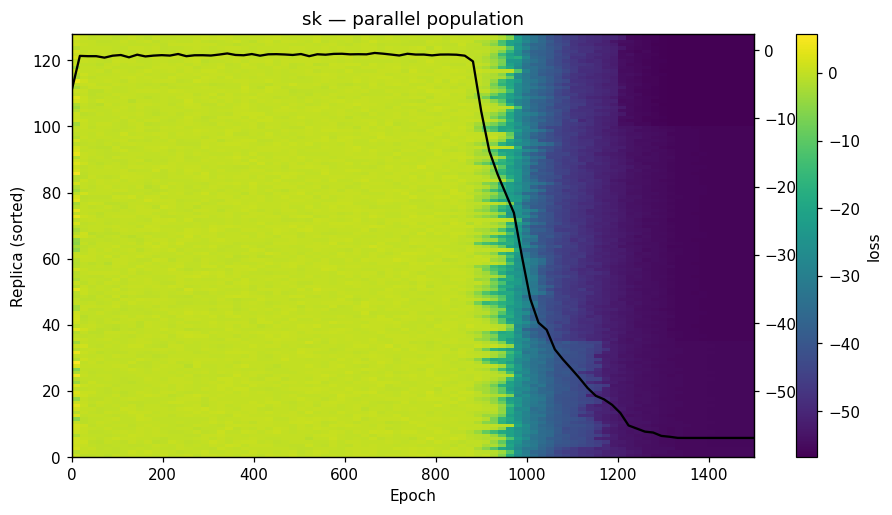 |
Sherrington–Kirkpatrick spin glass (N=80) — the same helpers work for every catalog problem.
The full per-problem gallery (MIS, Max-Cut, coloring, Ising 1D,
Edwards–Anderson, SK, binary perceptron, Hopfield) is in
docs/visualization.md. Regenerate the figures
with uv run python scripts/make_gallery.py.
Verified correctness
We benchmark QQA against ground truth or a strong baseline for every problem
in the catalog via scripts/verify_all_problems.py. The most recent sweep
(29 instances across 9 problem families) lives in
docs/verification.md:
| Problem | Instances | Reference | QQA |
|---|---|---|---|
| Maximum Independent Set | 3 × (3-reg, N=50) | networkx degree-greedy | matches or beats greedy on all seeds |
| MaxCut | 3 × ER (N=30/40/60) | best-of-400 random partition | +6 / +16 / +27 edges over random |
| MaxClique | 3 × ER (N=30/40/50) | nx.approximation.max_clique |
+1 vertex on every seed |
| Graph coloring (K=3) | 3 × (3-reg, N=40) | Welsh–Powell greedy | 0 conflicts on all seeds |
| Ising 1D ferromagnet | N ∈ {16, 32, 64} | exact E₀ = −N | gap = 0 on every size |
| Edwards–Anderson 2D, L=3 | 3 seeds | brute force (2⁹) | matches exact ground state |
| Edwards–Anderson 3D, L=4 | 2 seeds | — | E/N ≈ −1.61 (no exact solver) |
| Sherrington–Kirkpatrick | N ∈ {50, 100, 200} | Parisi e₀ = −0.7632 | ≤ 3.2 % gap at N=200 |
| Binary perceptron | α ∈ {0.3, 0.5, 0.7} | teacher reaches 0 errors | 0 errors on all α |
| Hopfield memory | (N, P) ∈ {(32,2),(64,3),(128,4)} | ≥ 0.95 overlap | overlap = 1.0 |
Overall: 29 / 29 checks pass (100 %). Re-run with
uv run python scripts/verify_all_problems.py to regenerate the report
in place.
Notebooks
Nine runnable notebooks live in examples/. Each carries an
Open in Colab badge in its first cell and auto-installs qqa.
| # | Notebook |
|---|---|
| 0 | 00_colab_quickstart.ipynb — one-click tour of every problem |
| 1 | 01_maximum_independent_set.ipynb |
| 2 | 02_graph_coloring.ipynb |
| 3 | 03_max_cut.ipynb |
| 4 | 04_edwards_anderson_3d.ipynb |
| 5 | 05_sherrington_kirkpatrick.ipynb |
| 6 | 06_binary_perceptron.ipynb |
| 7 | 07_hopfield_memory.ipynb |
| 8 | 08_parallel_benchmark.ipynb |
Regenerate them deterministically with
uv run python scripts/_generate_notebooks.py.
Documentation
uv run mkdocs serve # http://127.0.0.1:8000
uv run mkdocs build --strict # produces site/
The site covers the quickstart, full problem catalog with mathematical definitions, GUI walk-through, visualization guide, auto-generated API reference, and a migration guide from 0.2.x.
Scripts
| Script | Purpose |
|---|---|
scripts/demo_mis.py |
Minimal MIS end-to-end demo |
scripts/demo_coloring.py |
3-coloring end-to-end demo |
scripts/demo_parallel.py |
Parallel instances of MIS |
scripts/demo_pignn_mis.py |
MIS via the optional CRA-PI-GNN backend (PyG) |
scripts/bench_er_small.py |
Benchmark on the bundled ER-small MIS dataset |
scripts/bench_qqa_vs_pignn.py |
QQA vs. CRA-PI-GNN comparison (README table) |
scripts/make_gallery.py |
Regenerate the figures used in the README |
scripts/verify_all_problems.py |
Run the catalog-wide correctness sweep |
scripts/_generate_notebooks.py |
Regenerate the shipped example notebooks |
Run any script via uv run python scripts/<name>.py.
Notebooks
| Notebook | Purpose |
|---|---|
notebooks/cra_pignn_example.ipynb |
Walkthrough of the optional CRA-PI-GNN (PyTorch Geometric) backend on all five supported graph problems (MIS, MaxCut, MaxClique, VertexCover, GraphBisection) with side-by-side qqa.anneal runs. Requires the pignn extra. |
Repository layout
QQA4CO/
├── src/qqa/ # importable package (annealing, problems, viz, ...)
│ └── problems/ # qubo.py, categorical.py, spin.py, extras.py, user.py
├── app/ # Streamlit dashboard (streamlit_app.py + pages/)
├── docs/ # MkDocs site sources
├── examples/ # 9 example notebooks
├── scripts/ # demo, benchmark, verification, gallery scripts
├── tests/ # pytest suite
├── data/ # bundled datasets and gallery figures
├── pyproject.toml
└── README.md
Contributing
Issues and pull requests are welcome. See
CONTRIBUTING.md for setup, style, and test commands.
License
BSD-3-Clause-Clear (BSD-3-Clause with an explicit no-patent-grant
clause) — see LICENSE.
Cite
If you use the QQA4CO software in your research (regardless of which backend), please cite the software via its concept DOI alongside the companion paper:
@software{qqa4co_software,
title = {QQA4CO: Quasi-Quantum Annealing for Combinatorial Optimization},
author = {Ichikawa, Yuma and Arai, Yamato},
year = {2026},
version = {0.5.0},
doi = {10.5281/zenodo.19648231},
url = {https://github.com/Yuma-Ichikawa/QQA4CO}
}
If you use the PQQA solver (qqa.anneal), please also cite:
@inproceedings{ichikawa2025pqqa,
title = {Optimization by Parallel Quasi-Quantum Annealing with Gradient-Based Sampling},
author = {Ichikawa, Yuma and Arai, Yamato},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2025},
url = {https://openreview.net/forum?id=9EfBeXaXf0}
}
If you use the CPRA diverse-solution framework, please cite:
@article{ichikawa2025cpra,
title = {Continuous Parallel Relaxation for Finding Diverse Solutions in Combinatorial Optimization Problems},
author = {Ichikawa, Yuma and Iwashita, Hiroaki},
journal = {Transactions on Machine Learning Research (TMLR)},
year = {2025},
url = {https://openreview.net/forum?id=ix33zd5zCw}
}
If you use the optional CRA-PI-GNN backend (qqa.pignn), please also
cite the original paper and the reference DGL implementation it was ported
from:
@inproceedings{ichikawa2024controlling,
title = {Controlling Continuous Relaxation for Combinatorial Optimization},
author = {Ichikawa, Yuma},
booktitle = {The Thirty-eighth Annual Conference on Neural Information Processing Systems (NeurIPS)},
year = {2024},
url = {https://openreview.net/forum?id=ykACV1IhjD}
}
Reference implementation: https://github.com/Yuma-Ichikawa/CRA4CO.
If you use the DISCS combinatorial-optimization benchmark suite
(make bench-discs, qqa.datasets.discs_*, data/discs/), please cite the
original DISCS paper that defined the problem instances and provided the
raw graph data:
@inproceedings{goshvadi2023discs,
title = {{DISCS}: A Benchmark for Discrete Sampling},
author = {Goshvadi, Katayoon and Sun, Haoran and Liu, Xingchao
and Nova, Azade and Zhang, Ruqi and Grathwohl, Will
and Schuurmans, Dale and Dai, Hanjun},
booktitle = {Advances in Neural Information Processing Systems
(NeurIPS Datasets and Benchmarks Track)},
year = {2023},
url = {https://openreview.net/forum?id=oi1MUMk5NF}
}
Reference implementation: https://github.com/google-research/discs.
The unified data/discs/ layout (one .gpickle per instance plus a
manifest.jsonl sidecar) is QQA4CO-specific and described in
data/discs/README.md.
If you use the planted-solution factorization Ising benchmark
(qqa.IntegerFactorizationIsing, scripts/bench_factorization.py,
data/factorization/), please cite the paper that introduced the
construction and the gadget formulas this implementation follows:
@article{hen2026planted,
title = {Planted-solution {SAT} and Ising benchmarks from integer factorization},
author = {Hen, Itay},
journal = {arXiv preprint arXiv:2604.09837},
year = {2026}
}
Reference SAT/Ising compiler: https://github.com/itay-hen/pq-SAT-benchmark.
The QQA4CO implementation in src/qqa/problems/factorization.py is
independent and follows Eqs. 10–12 of the paper directly.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file qqa-0.6.0.tar.gz.
File metadata
- Download URL: qqa-0.6.0.tar.gz
- Upload date:
- Size: 217.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
58073fbe587e5187c4e246f517b37b558dd6cf8baf6541ed33e9b489efd51035
|
|
| MD5 |
698d52b748cf2b3b4c431a4a12ecb80d
|
|
| BLAKE2b-256 |
d2ded31f6dd5359de2a9f07ad6400927b04068574683e35a01e022e66990fe6a
|
Provenance
The following attestation bundles were made for qqa-0.6.0.tar.gz:
Publisher:
publish.yml on Yuma-Ichikawa/QQA4CO
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
qqa-0.6.0.tar.gz -
Subject digest:
58073fbe587e5187c4e246f517b37b558dd6cf8baf6541ed33e9b489efd51035 - Sigstore transparency entry: 1342640581
- Sigstore integration time:
-
Permalink:
Yuma-Ichikawa/QQA4CO@d69ac6b2e8ee880f1001e300b8e8e84d9acef9fa -
Branch / Tag:
refs/tags/v0.6.0 - Owner: https://github.com/Yuma-Ichikawa
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@d69ac6b2e8ee880f1001e300b8e8e84d9acef9fa -
Trigger Event:
release
-
Statement type:
File details
Details for the file qqa-0.6.0-py3-none-any.whl.
File metadata
- Download URL: qqa-0.6.0-py3-none-any.whl
- Upload date:
- Size: 206.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c9b6a88ec48faf2a7401ceb80fca183cd93c0eeeb1339c2a3722942c05c1ed9e
|
|
| MD5 |
d95dd33629290b1a580cc4d9abeb54cb
|
|
| BLAKE2b-256 |
977921991a573b459be374539b1a474d4b21f46e0fabf66134a0d1d384f1361d
|
Provenance
The following attestation bundles were made for qqa-0.6.0-py3-none-any.whl:
Publisher:
publish.yml on Yuma-Ichikawa/QQA4CO
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
qqa-0.6.0-py3-none-any.whl -
Subject digest:
c9b6a88ec48faf2a7401ceb80fca183cd93c0eeeb1339c2a3722942c05c1ed9e - Sigstore transparency entry: 1342640591
- Sigstore integration time:
-
Permalink:
Yuma-Ichikawa/QQA4CO@d69ac6b2e8ee880f1001e300b8e8e84d9acef9fa -
Branch / Tag:
refs/tags/v0.6.0 - Owner: https://github.com/Yuma-Ichikawa
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@d69ac6b2e8ee880f1001e300b8e8e84d9acef9fa -
Trigger Event:
release
-
Statement type:







