A metrics toolkit to evaluate neural network explanations.

Project description

A toolbox for quantitative evaluation of XAI
PyTorch and Tensorflow




Quantus is currently under active development and has not yet reached a stable state! Interfaces may change suddenly and without warning, so please be careful when attempting to use Quantus in its current state.
Table of contents
Library overview
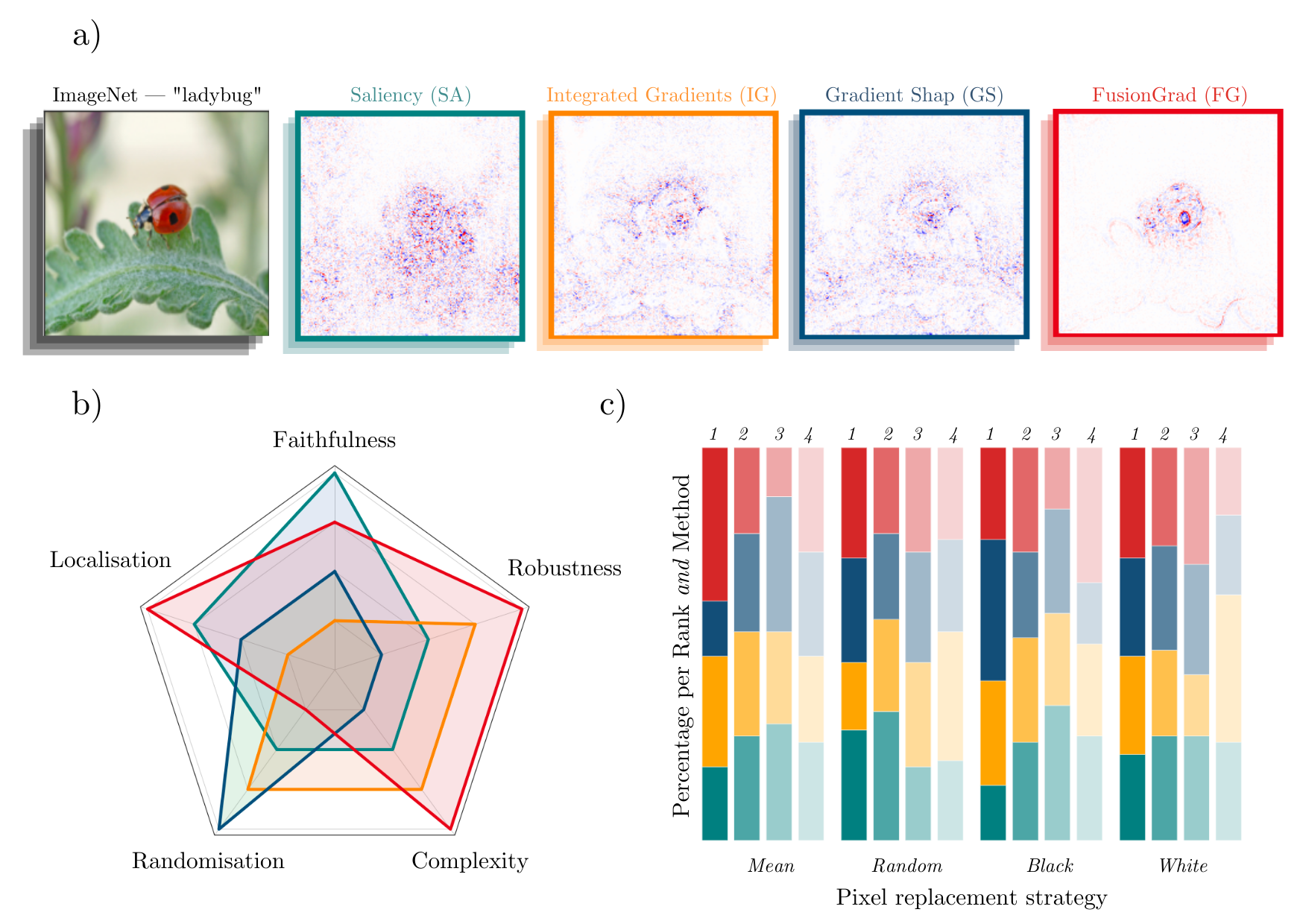
Simple qualitative comparison of XAI methods is often not sufficient to decide which explanation method works best as shown exemplary in Figure a) for four gradient-based methods — Saliency (Shrikumar et al., 2017), Integrated Gradients (Sundararajan et al., 2017), GradientShap (Lundberg and Lee, 2017) or FusionGrad (Bykov et al., 2021). Therefore, we developed Quantus, an easy to-use yet comprehensive toolbox for quantitative evaluation of explanations — including 25+ different metrics. With Quantus, we can obtain richer insights on how the methods compare e.g., b) by holistic quantification on several evaluation criteria and c) by providing sensitivity analysis of how a single parameter e.g. the pixel replacement strategy of a faithfulness test influences the ranking of the XAI methods.
Implementations. This project started with the goal of collecting existing evaluation metrics that have been introduced in the context of Explainable Artificial Intelligence (XAI) research. Along the way of implementation, it became clear that XAI metrics most often belong to one out of six categories i.e., 1) faithfulness, 2) robustness, 3) localisation 4) complexity 5) randomisation or 6) axiomatic metrics. It is important to note here that in XAI literature, the categories are often mentioned under different naming conventions e.g., 'robustness' is often replaced for 'stability' or 'sensitivity' and "'faithfulness' is commonly interchanged for 'fidelity'). The library contains implementations of the following evaluation metrics:
Faithfulness
quantifies to what extent explanations follow the predictive behaviour of the model (asserting that more important features play a larger role in model outcomes)- Faithfulness Correlation: iteratively replaces a random subset of given attributions with a baseline value and then measuring the correlation between the sum of this attribution subset and the difference in function output
- Faithfulness Estimate: computes the correlation between probability drops and attribution scores on various points
- Monotonicity Metric Arya: starts from a reference baseline to then incrementally replace each feature in a sorted attribution vector, measuing the effect on model performance
- Monotonicity Metric Nguyen: measures the spearman rank correlation between the absolute values of the attribution and the uncertainty in the probability estimation
- Pixel Flipping: aptures the impact of perturbing pixels in descending order according to the attributed value on the classification score
- Region Perturbation: is an extension of Pixel-Flipping to flip an area rather than a single pixel
- Selectivity: measures how quickly an evaluated prediction function starts to drop when removing features with the highest attributed values
- SensitivityN: computes the correlation between the sum of the attributions and the variation in the target output while varying the fraction of the total number of features, averaged over several test samples
- IROF: computes the area over the curve per class for sorted mean importances of feature segments (superpixels) as they are iteratively removed (and prediction scores are collected), averaged over several test samples
Robustness
measures to what extent explanations are stable when subject to slight perturbations of the input, assuming that model output approximately stayed the same- Local Lipschitz Estimate: tests the consistency in the explanation between adjacent examples
- Max-Sensitivity: measures the maximum sensitivity of an explanation using a Monte Carlo sampling-based approximation
- Avg-Sensitivity: measures the average sensitivity of an explanation using a Monte Carlo sampling-based approximation
- Continuity: captures the strongest variation in explanation of an input and it's perturbed version
Localisation
tests if the explainable evidence is centered around the object of interest (as defined by a bounding box or similar segmentation mask)- Pointing Game: checks whether attribution with the highest score is located within the targeted object
- Attribution Localization: measures the ratio of positive attributions within the targeted object towards the total positive attributions
- Top-K Intersection: computes the intersection between a ground truth mask and the binarized explanation at the top k feature locations
- Relevance Rank Accuracy: measures the ratio of highly attributed pixels within a ground-truth mask towards the size of the ground truth mask
- Relevance Mass Accuracy: measures the ratio of positively attributed attributions inside the ground-truth mask towards the overall positive attributions
- AUC: compares the ranking between attributions and a given ground-truth mask
Complexity
captures to what extent explanations are concise i.e., that few features are used to explain a model prediction- Sparseness: uses the Gini Index for measuring, if only highly attributed features are truly predictive of the model output
- Complexity: computes the entropy of the fractional contribution of all features to the total magnitude of the attribution individually
- Effective Complexity: measures how many attributions in absolute values are exceeding a certain threshold
Randomisation
tests to what extent explanations deteriorate as model parameters are increasingly randomised- Model Parameter Randomisation: randomises the parameters of single model layers in a cascading or independent way and measures the distance of the respective explanation to the original explanation
- andom Logit Test: computes for the distance between the original explanation and the explanation for a random other class
Axiomatic
- Completeness: assesses if explanations fulfill certain axiomatic properties
- Non-Sensitivity: measures whether the total attribution is proportional to the explainable evidence at the model output (and referred to as Summation to Delta (Shrikumar et al., 2017) Sensitivity-n (slight variation, Ancona et al., 2018) Conservation (Montavon et al., 2018))
- Input Invariance: adds a shift to input, asking that attributions should not change in response (assuming the model does not)
Additional metrics will be included in future releases.
Scope. There is a couple of metrics that are popular but have not been included in the first version of this library. Metrics that require re-training of the network e.g., RoAR (Hooker et al., 2018) and Label Randomisation Test (Adebayo et al., 2018) or rely on specifically designed datasets/ dataset modification e.g., Model Contrast Scores and Input Dependence Rate (Yang et al., 2019) and Attribution Percentage (Attr%) (Zhou et al., 2021) are considered out of scope of the first iteration.
Motivation. It is worth nothing that this implementation primarily is motivated by image classification tasks. Further, it has been developed with attribution-based explanations in mind (which is a category of explanation methods that aim to assign an importance value to the model features and arguably, is the most studied kind of explanation). As a result, there will be both applications and explanation methods e.g., example-based methods where this library won't be applicable.
Disclaimers. Note that the implementations of metrics in this library have not been verified by the original authors. Thus any metric implementation in this library may differ from the original authors. Also, metrics for XAI methods are often empirical interpretations (or translations) of qualities that some researcher(s) claimed were important for explanations to fulfill. Hence it may be a discrepancy between what the author claims to measure by the proposed metric and what is actually measured e.g., using entropy as an operationalisation of explanation complexity. Please read the user guidelines for further guidance on how to best use the library.
Installation
Quantus can be installed from PyPI
(this way assumes that you have either torch or tensorflow already installed on your machine).
pip install quantus
If you don't have torch or tensorflow installed, you can simply add the package you want and install it simultaneously.
pip install quantus[torch]
Or, alternatively for tensorflow you run:
pip install quantus[tensorflow]
Additionally, if you want to use the basic explainability functionaliy such as quantus.explain in your evaluations, you can run pip install quantus[extras] (this step requires that either torch or tensorflow is installed).
Alternatively, simply install requirements.txt (again, this requires that either torch or tensorflow is installed and won't include the explainability functionality to the installation):
pip install -r requirements.txt
Package requirements:
python>=3.7.0
pytorch>=1.10.1
tensorflow==2.6.2; python==3.7.0
tensorflow>=2.6.2; python>=3.7.0
Getting started
To use the library, you'll need a couple of ingredients; a torch model, some input data and labels (to be explained).
import quantus
import torch
import torchvision
# Load a pre-trained LeNet classification model (architecture at quantus/helpers/models).
model = LeNet()
model.load_state_dict(torch.load("tutorials/assets/mnist"))
# Load datasets and make loaders.
test_set = torchvision.datasets.MNIST(root='./sample_data', download=True)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=24)
# Load a batch of inputs and outputs to use for XAI evaluation.
x_batch, y_batch = iter(test_loader).next()
x_batch, y_batch = x_batch.cpu().numpy(), y_batch.cpu().numpy()
# Enable GPU.
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
Next, we generate some explanations for some test set samples that we wish to evaluate using quantus library.
import captum
from captum.attr import Saliency, IntegratedGradients
# Generate Integrated Gradients attributions of the first batch of the test set.
a_batch_saliency = Saliency(model).attribute(inputs=x_batch, target=y_batch, abs=True).sum(axis=1).cpu().numpy()
a_batch_intgrad = IntegratedGradients(model).attribute(inputs=x_batch, target=y_batch, baselines=torch.zeros_like(x_batch)).sum(axis=1).cpu().numpy()
# Save x_batch and y_batch as numpy arrays that will be used to call metric instances.
x_batch, y_batch = x_batch.cpu().numpy(), y_batch.cpu().numpy()
# Quick assert.
assert [isinstance(obj, np.ndarray) for obj in [x_batch, y_batch, a_batch_saliency, a_batch_intgrad]]
# You can use any function e.g., quantus.explain (not necessarily captum) to generate your explanations.

The qualitative aspects of the Saliency and Integrated Gradients explanations may look fairly uninterpretable - since we lack ground truth of what the explanations should be looking like, it is hard to draw conclusions about the explainable evidence that we see. So, to quantitatively evaluate the explanation we can apply Quantus. For this purpose, we may be interested in measuring how sensitive the explanations are to very slight perturbations. To this end, we can e.g., apply max-sensitivity by Yeh et al., 2019 to evaluate our explanations. With Quantus, we created two options for evaluation.
- Either evaluate the explanations in a one-liner - by calling the instance of the metric class.
# Define params for evaluation.
params_eval = {
"nr_samples": 10,
"perturb_radius": 0.1,
"norm_numerator": quantus.fro_norm,
"norm_denominator": quantus.fro_norm,
"perturb_func": quantus.uniform_sampling,
"similarity_func": quantus.difference,
"img_size": 28,
"nr_channels": 1,
"normalise": False,
"abs": False,
"disable_warnings": True,
}
# Return max sensitivity scores in an one-liner - by calling the metric instance.
scores_saliency = quantus.MaxSensitivity(**params_eval)(model=model,
x_batch=x_batch,
y_batch=y_batch,
a_batch=a_batch_saliency,
**{"explain_func": quantus.explain,
"method": "Saliency",
"device": device})
- Or use
quantus.evaluate()which is a high-level function that allow you to evaluate multiple XAI methods on several metrics at once.
import numpy as np
metrics = {"max-Sensitivity": quantus.MaxSensitivity(**params_eval),
}
xai_methods = {"Saliency": a_batch_saliency,
"IntegratedGradients": a_batch_intgrad}
results = quantus.evaluate(metrics=metrics,
xai_methods=xai_methods,
model=model,
x_batch=x_batch,
y_batch=y_batch,
agg_func=np.mean,
**{"explain_func": quantus.explain, "device": device})
# Summarise results in a dataframe.
df = pd.DataFrame(results)
df
When comparing the max-Sensitivity scores for the Saliency and Integrated Gradients explanations, we can conclude that in this experimental setting, Saliency can be considered less robust (scores 0.41 +-0.15std) compared to Integrated Gradients (scores 0.17 +-0.05std). To replicate this simple example please find a dedicated notebook: Getting started.
Tutorials
To get a more comprehensive view of the previous example, there is many types of analysis that can be done using Quantus. For example, we could use Quantus to verify to what extent the results - that Integrated Gradients "wins" over Saliency - are reproducible over different parameterisations of the metric e.g., by changing the amount of noise perturb_radius or the number of samples to iterate over nr_samples. With Quantus, we could further analyse if Integrated Gradients offers an improvement over Saliency also in other evaluation criteria such as faithfulness, randomisation and localisation.
For more use cases, please see notebooks in /tutorials folder which includes examples such as
- Basic example all metrics: shows how to instantiate the different metrics for ImageNet
- Metrics' parameterisation sensitivity: explores how sensitive a metric could be to its hyperparameters
- Understand how explanations robustness develops during model training: looks into how robustness of gradient-based explanations change as model gets increasingly accurate in its predictions
- Compare explanation methods using qualitative-, quantitative- and senitivity analysis: benchmarks explanation methods under different types of analysis: qualitative, quantitative and sensitivity
... and more.
Misc functionality
With Quantus, one can flexibly extend the library's functionality e.g., to adopt a customised explainer function explain_func or to replace a function that perturbs the input perturb_func with a user-defined one.
If you are replacing a function within the Quantus framework, make sure that your new function:
- returns the same datatype (e.g., np.ndarray or float) and,
- employs the same arguments (e.g., img=x, a=a) as the function you’re intending to replace.
Details on what datatypes and arguments that should be used for the different functions can be found in the respective function typing inquantus/helpers. For example, if you want to replace similar_func in your evaluation, you can do as follows.
import scipy
import numpy as np
def correlation_spearman(a: np.array, b: np.array, **kwargs) -> float:
"""Calculate Spearman rank of two images (or explanations)."""
return scipy.stats.spearmanr(a, b)[0]
def my_similar_func(a: np.array, b: np.array, **kwargs) -> float:
"""Calculate the similarity of a and b by subtraction."""
return a - b
# Simply initalise the metric with your own function.
metric = LocalLipschitzEstimate(similar_func=my_similar_func)
To evaluate multiple explanation methods over several metrics at oncewe user can leverage the evaluate method in Quantus. There are also other miscellaneous functionality built-into Quantus that might be helpful:
# Interpret scores.
quantus.evaluate
# Interpret scores of a given metric.
metric_instance.interpret_scores
# Understand what hyperparameters of a metric to tune.
sensitivity_scorer.get_params
# To list available metrics (and their corresponding categories).
quantus.AVAILABLE_METRICS
# To list available explainable methods.
quantus.AVAILABLE_XAI_METHODS
# To list available perturbation functions.
quantus.AVAILABLE_SIMILARITY_FUNCTIONS
# To list available similarity functions.
quantus.AVAILABLE_PERTURBATION_FUNCTIONS
# To list available normalisation function.
quantus.AVAILABLE_NORMALISATION_FUNCTIONS
# To get the scores of the last evaluated batch.
metric_instance_called.last_results
# To get the scores of all the evaluated batches.
metric_instance_called.all_results
With each metric intialisation, warnings are printed to shell in order to make the user attentive to the hyperparameters of the metric which may have great influence on the evaluation outcome. If you are running evaluation iteratively you might want to disable warnings, then set:
disable_warnings = True
in the params of the metric initalisation.
Contributing
If you would like to contribute to this project or add your metric to evaluate explanations please open an issue or submit a pull request.
Code Style
Code is written to follow PEP-8 and for docstrings we use numpydoc. We use flake8 for quick style checks and black for code formatting with a line-width of 88 characters per line.
Testing
Tests are written using pytest and executed together with codecov for coverage reports.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file quantus-0.1.0.tar.gz.
File metadata
- Download URL: quantus-0.1.0.tar.gz
- Upload date:
- Size: 66.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.2 readme-renderer/32.0 requests/2.26.0 requests-toolbelt/0.9.1 urllib3/1.26.7 tqdm/4.62.3 importlib-metadata/4.8.1 keyring/23.4.0 rfc3986/1.5.0 colorama/0.4.4 CPython/3.9.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2bc8b15e57f00affe153c40f93799dcc45346e243dc0636ce904d9b85566561a
|
|
| MD5 |
9c813d4d8662fe5f84b3d41ab19a7e03
|
|
| BLAKE2b-256 |
a83bf6808cd383cc532df453990c12f74703dc9fad2bf6eb39b7b45710fa04b1
|
File details
Details for the file quantus-0.1.0-py3-none-any.whl.
File metadata
- Download URL: quantus-0.1.0-py3-none-any.whl
- Upload date:
- Size: 85.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.2 readme-renderer/32.0 requests/2.26.0 requests-toolbelt/0.9.1 urllib3/1.26.7 tqdm/4.62.3 importlib-metadata/4.8.1 keyring/23.4.0 rfc3986/1.5.0 colorama/0.4.4 CPython/3.9.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1b7f7ab642368a8f9bd1295ea10d7b43c5a2f9989612e3bd33b6b573bcd682b1
|
|
| MD5 |
6604e394c2e0aeaf50f1cf26bdf89391
|
|
| BLAKE2b-256 |
4c2cfcdcd9ef51ba0b88ffcafedbac0e56841834da4c720f4b0bd1d37bfb287d
|







