A toolkit to quickly analyze topic models using various methods

Project description
Quick Topic Mining Toolkit (QTMT)
The quick-topic toolkit allows us to quickly evaluate topic models in various methods.
Features
- Topic Prevalence Trends Analysis
- Topic Interaction Strength Analysis
- Topic Transition Analysis
- Topic Trends of Numbers of Document Containing Keywords
- Topic Trends Correlation Analysis
- Topic Similarity between Trends
- Summarize Sentence Numbers By Keywords
- Topic visualization
- This version supports topic modeling from both English and Chinese text.
Basic Usage
Example: generate topic models for each category in the dataset files
from quick_topic.topic_modeling.lda import build_lda_models
# step 1: data file
meta_csv_file="datasets/list_country.csv"
raw_text_folder="datasets/raw_text"
# term files used for word segementation
list_term_file = [
"../datasets/keywords/countries.csv",
"../datasets/keywords/leaders_unique_names.csv",
"../datasets/keywords/carbon2.csv"
]
# removed words
stop_words_path = "../datasets/stopwords/hit_stopwords.txt"
# run shell
list_category = build_lda_models(
meta_csv_file=meta_csv_file,
raw_text_folder=raw_text_folder,
output_folder="results/topic_modeling",
list_term_file=list_term_file,
stopwords_path=stop_words_path,
prefix_filename="text_",
num_topics=6
)
GUI
After installing the quick-topic package, run qtmt in the Terminal to call the GUI application.
$ qtmt
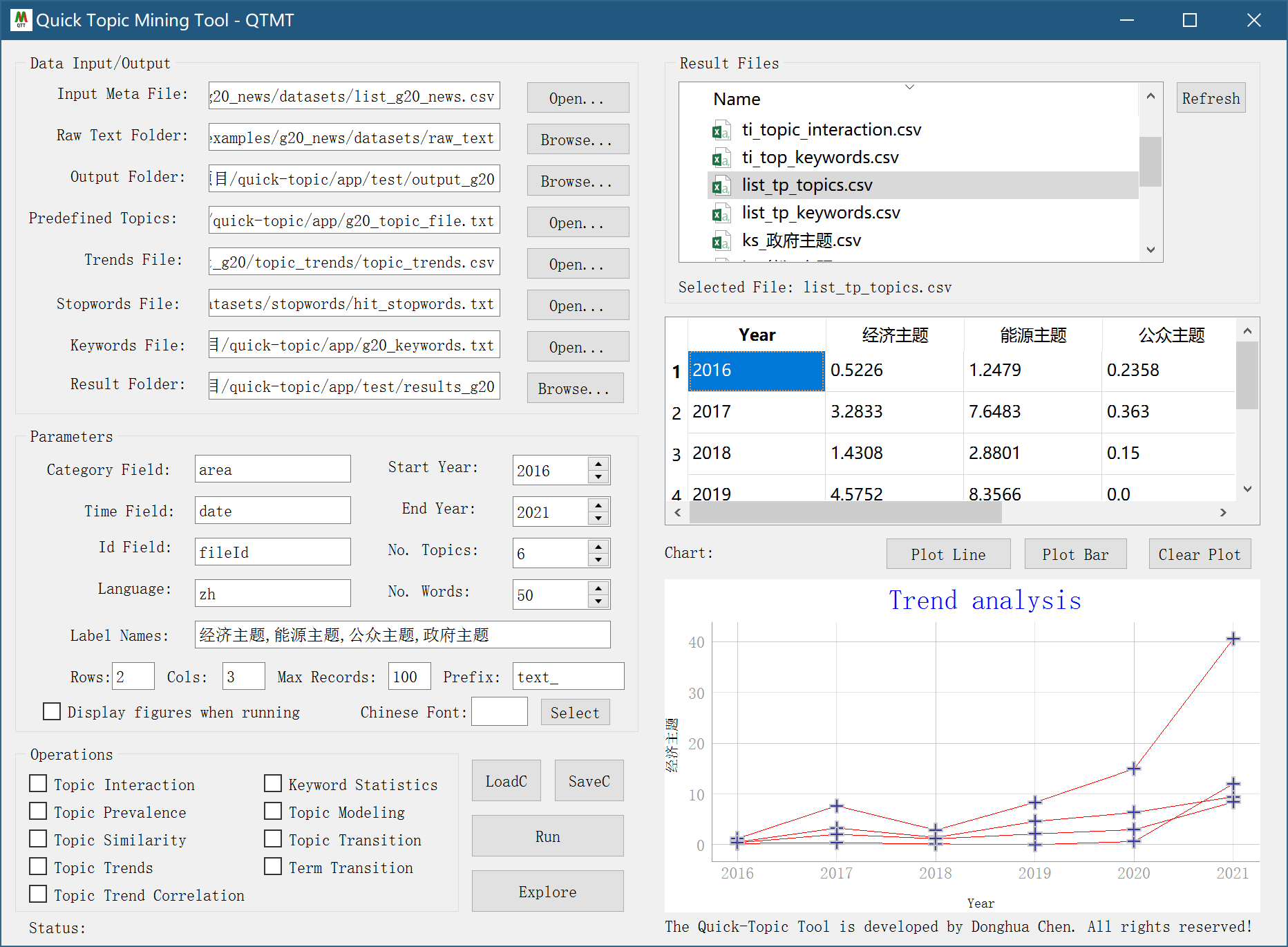
Advanced Usage
Example 1: Topic Prevalence over Time
from quick_topic.topic_prevalence.main import *
# data file: a csv file; a folder with txt files named the same as the ID field in the csv file
meta_csv_file = "datasets/list_country.csv"
text_root = r"datasets/raw_text"
# word segmentation data files
list_keywords_path = [
"../datasets/keywords/countries.csv",
"../datasets/keywords/leaders_unique_names.csv",
"../datasets/keywords/carbon2.csv"
]
# remove keywords
stop_words_path = "../datasets/stopwords/hit_stopwords.txt"
# date range for analysis
start_year=2010
end_year=2021
# used topics
label_names = ['经济主题', '能源主题', '公众主题', '政府主题']
topic_economics = ['投资', '融资', '经济', '租金', '政府', '就业', '岗位', '工作', '职业', '技能']
topic_energy = ['绿色', '排放', '氢能', '生物能', '天然气', '风能', '石油', '煤炭', '电力', '能源', '消耗', '矿产', '燃料', '电网', '发电']
topic_people = ['健康', '空气污染', '家庭', '能源支出', '行为', '价格', '空气排放物', '死亡', '烹饪', '支出', '可再生', '液化石油气', '污染物', '回收',
'收入', '公民', '民众']
topic_government = ['安全', '能源安全', '石油安全', '天然气安全', '电力安全', '基础设施', '零售业', '国际合作', '税收', '电网', '出口', '输电', '电网扩建',
'政府', '规模经济']
list_topics = [
topic_economics,
topic_energy,
topic_people,
topic_government
]
# run-all
run_topic_prevalence(
meta_csv_file=meta_csv_file,
raw_text_folder=text_root,
save_root_folder="results/topic_prevalence",
list_keywords_path=list_keywords_path,
stop_words_path=stop_words_path,
start_year=start_year,
end_year=end_year,
label_names=label_names,
list_topics=list_topics,
tag_field="area",
time_field="date",
id_field="fileId",
prefix_filename="text_",
)
Example 2: Estimate the strength of topic interaction (shared keywords) from different topics
from quick_topic.topic_interaction.main import *
# step 1: data file
meta_csv_file = "datasets/list_country.csv"
text_root = r"datasets/raw_text"
# step2: jieba cut words file
list_keywords_path = [
"../datasets/keywords/countries.csv",
"../datasets/keywords/leaders_unique_names.csv",
"../datasets/keywords/carbon2.csv"
]
# remove files
stopwords_path = "../datasets/stopwords/hit_stopwords.txt"
# set predefined topic labels
label_names = ['经济主题', '能源主题', '公众主题', '政府主题']
# set keywords for each topic
topic_economics = ['投资', '融资', '经济', '租金', '政府', '就业', '岗位', '工作', '职业', '技能']
topic_energy = ['绿色', '排放', '氢能', '生物能', '天然气', '风能', '石油', '煤炭', '电力', '能源', '消耗', '矿产', '燃料', '电网', '发电']
topic_people = ['健康', '空气污染', '家庭', '能源支出', '行为', '价格', '空气排放物', '死亡', '烹饪', '支出', '可再生', '液化石油气', '污染物', '回收',
'收入', '公民', '民众']
topic_government = ['安全', '能源安全', '石油安全', '天然气安全', '电力安全', '基础设施', '零售业', '国际合作', '税收', '电网', '出口', '输电', '电网扩建',
'政府', '规模经济']
# a list of topics above
list_topics = [
topic_economics,
topic_energy,
topic_people,
topic_government
]
# if any keyword is the below one, then the keyword is removed from our consideration
filter_words = ['中国', '国家', '工作', '领域', '社会', '发展', '目标', '全国', '方式', '技术', '产业', '全球', '生活', '行动', '服务', '君联',
'研究', '利用', '意见']
# dictionaries
list_country=[
'巴西','印度','俄罗斯','南非'
]
# run shell
run_topic_interaction(
meta_csv_file=meta_csv_file,
raw_text_folder=text_root,
output_folder="results/topic_interaction/divided",
list_category=list_country, # a dictionary where each record contain a group of keywords
stopwords_path=stopwords_path,
weights_folder='results/topic_interaction/weights',
list_keywords_path=list_keywords_path,
label_names=label_names,
list_topics=list_topics,
filter_words=filter_words,
# set field names
tag_field="area",
keyword_field="", # ignore if keyword from csv exists in the text
time_field="date",
id_field="fileId",
prefix_filename="text_",
)
Example 3: Divide datasets by year or year-month
By year:
from quick_topic.topic_transition.divide_by_year import *
divide_by_year(
meta_csv_file="../datasets/list_g20_news_all_clean.csv",
raw_text_folder=r"datasets\g20_news_processed",
output_folder="results/test1/divided_by_year",
start_year=2000,
end_year=2021,
)
By year-month:
from quick_topic.topic_transition.divide_by_year_month import *
divide_by_year_month(
meta_csv_file="../datasets/list_g20_news_all_clean.csv",
raw_text_folder=r"datasets\g20_news_processed",
output_folder="results/test1/divided_by_year_month",
start_year=2000,
end_year=2021
)
Example 4: Show topic transition by year
from quick_topic.topic_transition.transition_by_year_month_topic import *
label="经济"
keywords=['投资','融资','经济','租金','政府', '就业','岗位','工作','职业','技能']
show_transition_by_year_month_topic(
root_path="results/test1/divided_by_year_month",
label=label,
keywords=keywords,
start_year=2000,
end_year=2021
)
Example 5: Show keyword-based topic transition by year-month for keywords in addition to mean lines
from quick_topic.topic_transition.transition_by_year_month_term import *
root_path = "results/news_by_year_month"
select_keywords = ['燃煤', '储能', '电动汽车', '氢能', '脱碳', '风电', '水电', '天然气', '光伏', '可再生', '清洁能源', '核电']
list_all_range = [
[[2010, 2015], [2016, 2021]],
[[2011, 2017], [2018, 2021]],
[[2009, 2017], [2018, 2021]],
[[2011, 2016], [2017, 2021]],
[[2017, 2018], [2019, 2021]],
[[2009, 2014], [2015, 2021]],
[[2009, 2014], [2015, 2021]],
[[2009, 2015], [2016, 2021]],
[[2008, 2011], [2012, 2015], [2016, 2021]],
[[2011, 2016], [2017, 2021]],
[[2009, 2012], [2013, 2016], [2017, 2021]],
[[2009, 2015], [2016, 2021]]
]
output_figure_folder="results/figures"
show_transition_by_year_month_term(
root_path="results/test1/divided_by_year_month",
select_keywords=select_keywords,
list_all_range=list_all_range,
output_figure_folder=output_figure_folder,
start_year=2000,
end_year=2021
)
Example 6: Get time trends of numbers of documents containing topic keywords with full text.
from quick_topic.topic_trends.trends_by_year_month_fulltext import *
# define a group of topics with keywords, each topic has a label
label_names=['经济','能源','公民','政府']
keywords_economics = ['投资', '融资', '经济', '租金', '政府', '就业', '岗位', '工作', '职业', '技能']
keywords_energy = ['绿色', '排放', '氢能', '生物能', '天然气', '风能', '石油', '煤炭', '电力', '能源', '消耗', '矿产', '燃料', '电网', '发电']
keywords_people = ['健康', '空气污染', '家庭', '能源支出', '行为', '价格', '空气排放物', '死亡', '烹饪', '支出', '可再生', '液化石油气', '污染物', '回收',
'收入', '公民', '民众']
keywords_government = ['安全', '能源安全', '石油安全', '天然气安全', '电力安全', '基础设施', '零售业', '国际合作', '税收', '电网', '出口', '输电', '电网扩建',
'政府', '规模经济']
list_topics = [
keywords_economics,
keywords_energy,
keywords_people,
keywords_government
]
# call function to show trends of number of documents containing topic keywords each year-month
show_year_month_trends_with_fulltext(
meta_csv_file="datasets/list_country.csv",
list_topics=list_topics,
label_names=label_names,
save_result_path="results/topic_trends/trends_fulltext.csv",
minimum_year=2010,
raw_text_path=r"datasets/raw_text",
id_field='fileId',
time_field='date',
prefix_filename="text_"
)
Example 7: Estimate the correlation between two trends
from quick_topic.topic_trends_correlation.topic_trends_correlation_two import *
trends_file="results/topic_trends/trends_fulltext.csv"
label_names=['经济','能源','公民','政府']
list_result=[]
list_line=[]
for i in range(0,len(label_names)-1):
for j in range(i+1,len(label_names)):
label1=label_names[i]
label2=label_names[j]
result=estimate_topic_trends_correlation_single_file(
trend_file=trends_file,
selected_field1=label1,
selected_field2=label2,
start_year=2010,
end_year=2021,
show_figure=False,
time_field='Time'
)
list_result=[]
line=f"({label1},{label2})\t{result['pearson'][0]}\t{result['pearson'][1]}"
list_line.append(line)
print()
print("Correlation analysis resutls:")
print("Pair\tPearson-Stat\tP-value")
for line in list_line:
print(line)
Example 8: Estimate topic similarity between two groups of LDA topics
from quick_topic.topic_modeling.lda import build_lda_models
from quick_topic.topic_similarity.topic_similarity_by_category import *
# Step 1: build topic models
meta_csv_file="datasets/list_country.csv"
raw_text_folder="datasets/raw_text"
list_term_file = [
"../datasets/keywords/countries.csv",
"../datasets/keywords/leaders_unique_names.csv",
"../datasets/keywords/carbon2.csv"
]
stop_words_path = "../datasets/stopwords/hit_stopwords.txt"
list_category = build_lda_models(
meta_csv_file=meta_csv_file,
raw_text_folder=raw_text_folder,
output_folder="results/topic_similarity_two/topics",
list_term_file=list_term_file,
stopwords_path=stop_words_path,
prefix_filename="text_",
num_topics=6,
num_words=50
)
# Step 2: estimate similarity
output_folder = "results/topic_similarity_two/topics"
keywords_file="../datasets/keywords/carbon2.csv"
estimate_topic_similarity(
list_topic=list_category,
topic_folder=output_folder,
list_keywords_file=keywords_file,
)
Example 9: Stat sentence numbers by keywords
from quick_topic.topic_stat.stat_by_keyword import *
meta_csv_file='datasets/list_country.csv'
raw_text_folder="datasets/raw_text"
keywords_energy = ['煤炭', '天然气', '石油', '生物', '太阳能', '风能', '氢能', '水力', '核能']
stat_sentence_by_keywords(
meta_csv_file=meta_csv_file,
keywords=keywords_energy,
id_field="fileId",
raw_text_folder=raw_text_folder,
contains_keyword_in_sentence='',
prefix_file_name='text_'
)
Example 9: English topic modeling
from quick_topic.topic_visualization.topic_modeling_pipeline import *
## data
meta_csv_file = "datasets_en/list_blog_meta.csv"
raw_text_folder = f"datasets_en/raw_text"
stopwords_path = ""
## parameters
chinese_font_file = ""
num_topics=8
num_words=20
n_rows=2
n_cols=4
max_records=-1
## output
result_output_folder=f"results/en_topic{num_topics}"
if not os.path.exists(result_output_folder):
os.mkdir(result_output_folder)
run_topic_modeling_pipeline(
meta_csv_file=meta_csv_file,
raw_text_folder=raw_text_folder,
stopwords_path=stopwords_path,
top_record_num=max_records,
chinese_font_file="",
num_topics=num_topics,
num_words=num_words,
n_rows=n_rows,n_cols=n_cols,
result_output_folder = result_output_folder,
load_existing_models=False,
lang='en',
prefix_filename=''
)
License
The quick-topic toolkit is provided by Donghua Chen with MIT License.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file quick-topic-1.0.2.tar.gz.
File metadata
- Download URL: quick-topic-1.0.2.tar.gz
- Upload date:
- Size: 159.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.2 readme-renderer/34.0 requests/2.27.1 requests-toolbelt/0.9.1 urllib3/1.26.9 tqdm/4.63.0 importlib-metadata/4.11.3 keyring/23.5.0 rfc3986/2.0.0 colorama/0.4.4 CPython/3.9.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4cc52832fece7fd0f7dfafc8f15f8264631007a3fe5dba3a5a34d846bd9ed57e
|
|
| MD5 |
2b330eb6bafc1f364ab023891243326f
|
|
| BLAKE2b-256 |
2054ce0c4eb13ce6a95c50f6605bfdc7ea799042b37abb39ec10972a3b32c071
|
File details
Details for the file quick_topic-1.0.2-py3-none-any.whl.
File metadata
- Download URL: quick_topic-1.0.2-py3-none-any.whl
- Upload date:
- Size: 248.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.2 readme-renderer/34.0 requests/2.27.1 requests-toolbelt/0.9.1 urllib3/1.26.9 tqdm/4.63.0 importlib-metadata/4.11.3 keyring/23.5.0 rfc3986/2.0.0 colorama/0.4.4 CPython/3.9.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0aa240f47672ec236a84a5a547ca32351a3476acdf30c7594821aea97a00eb30
|
|
| MD5 |
5cb9ab8fbad13cc9df720c16c4aabb0c
|
|
| BLAKE2b-256 |
4d4bf739ea1a10a5bdf627083e5f47e14035d75a21025f9e997e549c71b53cb5
|







