CI evaluation framework for RAG and AI agents: groundedness, retrieval quality, hallucination, citations, latency, cost, and regression gating before production.

Project description
🛠️ rag-agent-eval-ci
Stop shipping RAG systems you can't test.
A CI evaluation framework for RAG and AI agents — gate every deploy on groundedness, retrieval quality, hallucination, citations, latency, cost, and regression.



⚠️ The Problem
Teams are shipping RAG assistants and AI agents into production, but most have no automated way to answer the one question that matters before a deploy:
[!IMPORTANT] "Is this version safe to ship, or did we just make it worse?"
A prompt tweak silently drops retrieval recall. A model swap doubles cost. A new chunking strategy starts hallucinating. Today these regressions are caught by users, not by CI.
rag-agent-eval-ci turns RAG quality into a pull-request gate. Developers write test questions in YAML; the tool measures groundedness, retrieval accuracy, hallucination, citations, latency, and cost, compares against a baseline, and fails the build when quality drops.
📺 Demo
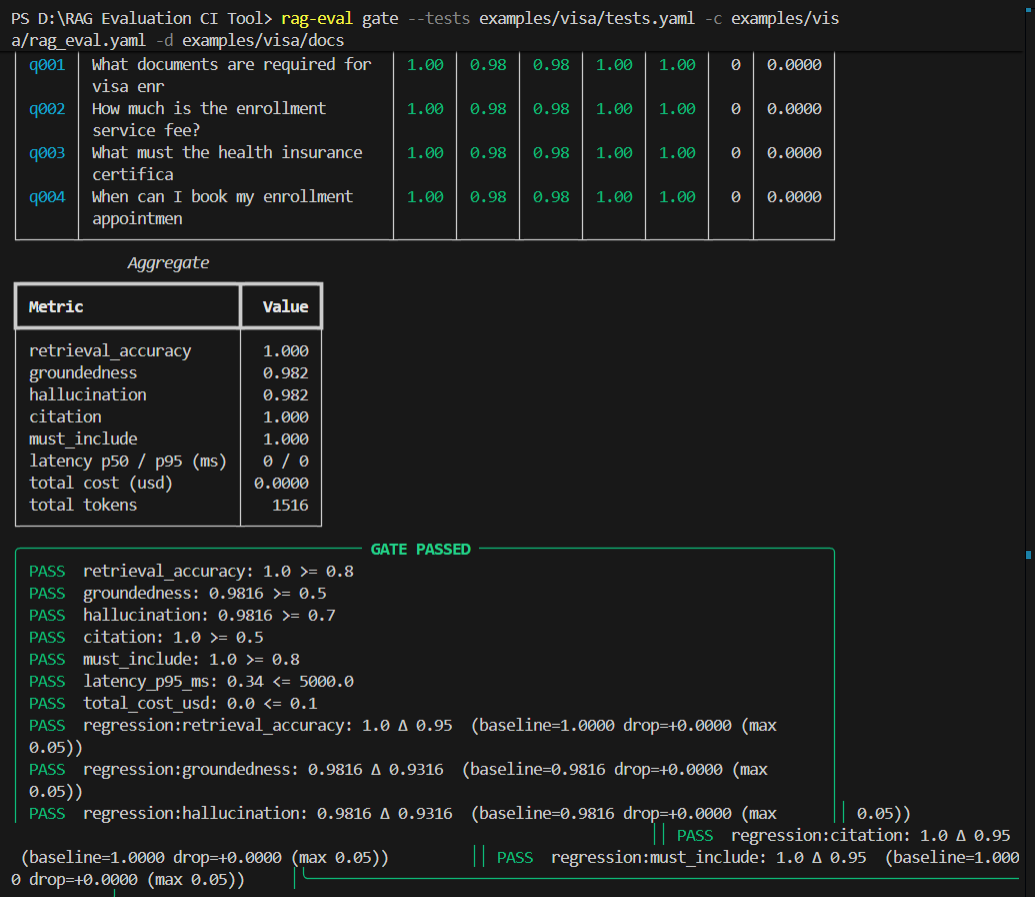
⚡ Quick Start (under 5 minutes, no API keys)
[!TIP] The default config uses a built-in mock provider + in-memory retriever, so the first run works with zero keys and zero network dependency.
Installation
pip install rag-agent-eval-ci # or: git clone https://github.com/martian7777/rag-agent-eval-ci && pip install -e .
Run the bundled visa-enrollment example end-to-end:
rag-eval gate \
--tests examples/visa/tests.yaml \
-c examples/visa/rag_eval.yaml \
-d examples/visa/docs
The exit code is 0 if the gate passes, and 1 if it fails — making it extremely straightforward to plug into your CI pipelines.
[!NOTE] Prefer Docker?
docker compose upbrings the API, dashboard, Postgres, and a local Ollama up together.
📄 Example Input
A developer just writes questions and expectations in tests.yaml:
suite: visa-docs
questions:
- question: "What documents are required for visa enrollment?"
expected_sources: ["visa_checklist.pdf"] # retrieval must surface this
must_include: ["passport", "admission letter", "insurance"] # answer completeness
must_not_include: ["bank statement is required"] # hallucination trap
📊 Example Output
Every run produces clean console output and CI-friendly artifacts in .rag_eval/reports/:
| File | Use case / Description |
|---|---|
report.json |
Machine-readable full evaluation results. |
junit.xml |
Standard format that renders as native test results in GitHub/GitLab CI. |
summary.md |
Clean markdown summary intended to be auto-posted to PR comments or job summaries. |
report.html |
Self-contained, premium visual report (perfect as a CI build artifact). |
🎯 What it Measures
| Metric | Question it answers | Core Evaluation Method |
|---|---|---|
| Retrieval accuracy | Did we retrieve the documents we expected? | Substring checking on returned sources vs expected. |
| Groundedness | Is the answer actually supported by the retrieved context? | LLM-judge verification or fallback token overlap. |
| Hallucination | Did the model invent unsupported or forbidden claims? | LLM-judge analysis plus must_not_include penalty checks. |
| Citation | Are the cited sources real and the right ones? | Compares cited sources vs retrieved context. |
| Answer completeness | Does the answer contain the key facts? | Validates presence of must_include phrases. |
| Latency | How fast is the system? | Tracks wall-clock time (gates on suite-level p95). |
| Cost | What is the financial footprint? | Live calculations (gates on suite-level total USD). |
| Regression | Did quality drop since the last release? | Auto-compares metrics against a tagged baseline run. |
🏗️ Architecture
flowchart TD
classDef main fill:#3b82f6,stroke:#1d4ed8,stroke-width:2px,color:#fff,font-weight:bold;
classDef input fill:#f8fafc,stroke:#64748b,stroke-width:1.5px;
classDef step fill:#fff,stroke:#cbd5e1,stroke-width:1px;
classDef eval fill:#fef2f2,stroke:#f87171,stroke-width:1.5px;
classDef storage fill:#ecfdf5,stroke:#34d399,stroke-width:1.5px;
classDef report fill:#fff7ed,stroke:#fb923c,stroke-width:1.5px;
classDef gate fill:#fef08a,stroke:#eab308,stroke-width:1.5px;
tests["tests.yaml<br><i>(Questions & Expectations)</i>"]:::input --> runner["Runner Engine"]:::main
runner --> target["Target System"]:::step
runner --> evals["Evaluator Suite"]:::step
runner --> reporting["Reporting System"]:::step
target --> target_desc["• Local RAG Pipeline<br>• HTTP Endpoint"]:::step
target_desc --> providers["Providers"]:::step
providers --> providers_list["• Mock (Offline)<br>• Ollama / OpenAI<br>• Gemini / OpenRouter"]:::step
providers_list --> vector["Vector Stores"]:::step
vector --> vector_list["• Memory / Chroma / Qdrant"]:::step
evals --> eval_list["• Retrieval Accuracy<br>• Groundedness <i>(LLM)</i><br>• Hallucination Penalty<br>• Citation & Source Precision<br>• Answer Completeness<br>• Latency & Cost"]:::eval
eval_list --> storage["Storage DB<br><i>(SQLite / Postgres)</i>"]:::storage
storage --> dashboard["Streamlit Dashboard<br>& FastAPI Backend"]:::storage
reporting --> report_formats["• Rich Console Output<br>• report.json<br>• junit.xml<br>• summary.md<br>• report.html"]:::report
report_formats --> gate_check["Gate Check"]:::gate
gate_check --> threshold_desc["Thresholds & Regression Checks"]:::gate
threshold_desc --> exit_code["CI Exit Code<br><i>(0 = Pass, 1 = Fail)</i>"]:::gate
storage -.-> gate_check
- Providers:
mock,ollama,openai,gemini,openrouter(any model via OpenRouter with live cost tracking). See docs/providers.md. - Vector stores:
memory(zero dependencies),chroma,qdrant. - Targets: Evaluate the built-in pipeline or point it at your own RAG HTTP endpoint — making it a plug-and-play evaluation utility for existing architectures.
💼 Use Cases
- Pull-Request Gate — Automatically block merges that regress retrieval/groundedness metrics or exceed cost limits.
- Model & Prompt Optimization — Run side-by-side comparison matrices (e.g.
gpt-4o-minivs local LLM) on quality and cost. - Nightly Regression Gates — Schedule automated cron runs against a tagged production baseline to capture silent drift.
- Provider Migration Assurance — Benchmark a new model/provider to prove compatibility before going live.
🚀 How to Use It in Your Company
- Seed a Test Suite: Write 10–20 high-value user questions in a
tests.yaml. - Configure Your Target: Point the runner to your pipeline. If using your own server, set
target.type: http:target: type: http url: https://your-rag.internal/answer question_field: question answer_field: answer sources_field: sources
- Select Your Judge: Configure a judging provider. Use
ollamafor a free local judge, or keys foropenrouter/openai/gemini. - Define Quality Thresholds: Set performance/cost bounds in
rag_eval.yaml. - Drop into CI: Copy the prebuilt .github/workflows/rag-eval.yml to auto-run on every PR.
- Freeze a Baseline: Run
rag-eval baseline save <run_id>on your main branch to establish a comparison reference.
Run history is persisted to Postgres/SQLite and can be monitored visually using the Streamlit dashboard (
docker compose up).
🐍 Python SDK
from rag_eval import Evaluator
# Run evaluations directly from your custom pipeline or test script
report = Evaluator.from_config("rag_eval.yaml").run(
"tests.yaml", ingest_dir="examples/visa/docs"
)
print(report.summary.quality) # e.g., {'groundedness': 0.98, ...}
assert report.passed # raise exceptions in standard test runners
🗺️ Roadmap
- Additional Evaluators: Context precision/recall, answer relevancy, and toxicity filters.
- Native Integrations: Direct connectors for LangChain / LlamaIndex pipelines.
- Agentic Evaluation: Support multi-turn agent conversations and tool usage tracking.
- Notification Exporters: Built-in Slack, Discord, and email alerts on gate failures.
- Visual Diffing: Comprehensive run-to-run comparisons on the dashboard.
- PyPI & Docker Images: Hosted pre-builds for zero setup.
🤝 Contributing
Contributions are very welcome! Please check out CONTRIBUTING.md to get started.
[!TIP] Looking for entry points? Check out our Good First Issues list.
📄 License
This project is licensed under the terms of the Apache-2.0 License.
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file rag_agent_eval_ci-0.1.0.tar.gz.
File metadata
- Download URL: rag_agent_eval_ci-0.1.0.tar.gz
- Upload date:
- Size: 46.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
363627b31b29447dc752ec817a7bfe28b40a0f3dd4eec69f4a2f4b31cec517df
|
|
| MD5 |
2f8c844ce88b77f1309a1f1e71716348
|
|
| BLAKE2b-256 |
929bbb976fbf69f2633dc3f13a048804ba47b3845b28e794f959d02fadc79c12
|
File details
Details for the file rag_agent_eval_ci-0.1.0-py3-none-any.whl.
File metadata
- Download URL: rag_agent_eval_ci-0.1.0-py3-none-any.whl
- Upload date:
- Size: 55.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bac4d0863c2c386a7901403989664f14ba7ebf982d5d85bc4169e62e2dabb876
|
|
| MD5 |
dd663faea9a322790396973bee74b283
|
|
| BLAKE2b-256 |
f8d274bbbd9c8851d752a3a20da9956b8ea33c3c33a33a0c594e84dfe709ecea
|







