Local-first evaluation framework for RAG pipelines and AI agents
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description

Local-first RAG evaluation framework for LLM applications
Evaluate, benchmark, and monitor your RAG pipelines — 100% locally, no API keys required.







Problem • Solution • Quick Start • Installation • Roadmap
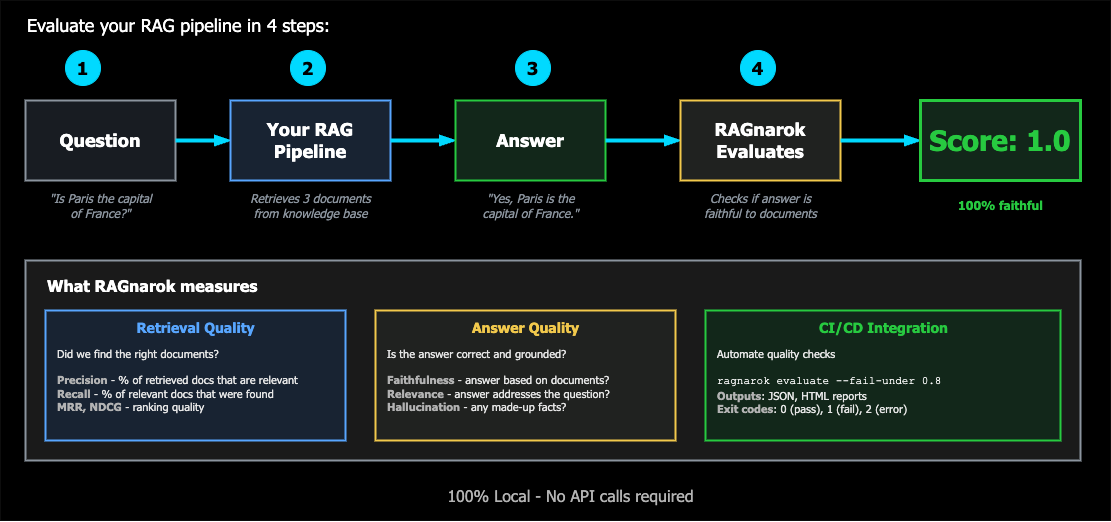
The Problem
Building RAG systems is easy. Knowing if they actually work is hard.
Current evaluation tools are either:
| Tool | Issue |
|---|---|
| Giskard | Heavy, slow (45-60 min scans), loses progress on crash, enterprise-focused |
| RAGAS | Requires OpenAI API keys, no local-first option |
| Manual testing | Doesn't scale, not reproducible |
You need a tool that:
- Runs 100% locally (Ollama, local models)
- Evaluates fast with checkpointing (no lost progress)
- Integrates with your existing stack (LangChain, LangGraph)
- Fits in CI/CD pipelines
- Doesn't require a PhD to use
The Solution
ragnarok-ai is a lightweight, local-first framework to evaluate RAG pipelines.
from ragnarok_ai import evaluate, generate_testset
# Generate test questions from your knowledge base
testset = await generate_testset(
knowledge_base="./docs/",
num_questions=50,
types=["simple", "multi_hop", "adversarial"],
llm="ollama/mistral",
checkpoint=True, # Resume if interrupted
)
# Evaluate your RAG pipeline
results = await evaluate(
rag_pipeline=my_rag,
testset=testset,
metrics=["retrieval", "faithfulness", "relevance"],
llm="ollama/mistral",
)
# Get actionable insights
results.summary()
# ┌─────────────────┬───────┬────────┐
# │ Metric │ Score │ Status │
# ├─────────────────┼───────┼────────┤
# │ Retrieval P@10 │ 0.82 │ PASS │
# │ Faithfulness │ 0.74 │ WARN │
# │ Relevance │ 0.89 │ PASS │
# │ Hallucination │ 0.12 │ PASS │
# └─────────────────┴───────┴────────┘
results.export("report.html")
v1.7.0 is now available! Alerting system with Webhook and Slack adapters. Install with
pip install ragnarok-ai
Key Features
| Feature | Description |
|---|---|
| 100% Local | Runs entirely on your machine with Ollama. No OpenAI, no API keys, no data leaving your network. |
| Production Monitoring | Collect traces, export Prometheus metrics, track latency and success rates in production. |
| LLM-as-Judge | Multi-criteria evaluation with Prometheus 2: faithfulness, relevance, hallucination, completeness. |
| Cost Tracking | Track token usage and costs. Local models = $0.00, see exactly what cloud APIs cost. |
| Jupyter Integration | Rich HTML display in notebooks with metrics visualization. |
| Fast & Resilient | Built-in checkpointing — crash mid-evaluation? Resume exactly where you left off. |
| Framework Agnostic | Works with LangChain, LangGraph, LlamaIndex, or your custom RAG. |
| Comprehensive Metrics | Retrieval quality, faithfulness, relevance, hallucination detection, latency tracking. |
| Test Generation | Auto-generate diverse test sets from your knowledge base. |
| CI/CD Ready | CLI-first design, JSON output, exit codes for pipeline integration. |
| Enterprise Ready | Kubernetes Helm charts, air-gapped deployment, data sovereignty. |
| Lightweight | Minimal dependencies. No torch/transformers in core. |
Comparison
| Feature | ragnarok-ai | Giskard | RAGAS |
|---|---|---|---|
| 100% Local | Yes | Partial | No |
| Checkpointing | Yes | No | No |
| Fast evaluation | Yes | No (45-60 min) | Yes |
| CLI support | Yes | No | No |
| LangChain integration | Yes | Yes | Yes |
| Minimal deps | Yes | No | Partial |
| Free & OSS | AGPL-3.0 | Open-core | Apache-2.0 |
Performance
Benchmarked on Apple M2 16GB, Python 3.10:
Retrieval Metrics: ~24,000 queries/sec
| Queries | Time | Peak RAM |
|---|---|---|
| 50 | 0.002s | 0.02 MB |
| 500 | 0.021s | 0.03 MB |
| 5000 | 0.217s | 0.17 MB |
LLM-as-Judge (Prometheus 2):
| Criterion | Avg Time |
|---|---|
| Faithfulness | ~25s |
| Relevance | ~22s |
| Hallucination | ~28s |
Retrieval is pure computation — instant. LLM-as-Judge is the bottleneck (~25s/eval), but runs 100% local.
Quick Start
Try it now: Open in Google Colab
Prerequisites
Install
pip install ragnarok-ai
With optional dependencies:
pip install ragnarok-ai[ollama,qdrant]
Run your first evaluation
# CLI demo
ragnarok evaluate --demo
# With options
ragnarok evaluate --demo --output results.json --fail-under 0.7
# Or in Python
python examples/basic_evaluation.py
Installation
Using pip
pip install ragnarok-ai
Optional dependencies
# LLM providers
pip install ragnarok-ai[ollama] # Ollama support
pip install ragnarok-ai[openai] # OpenAI support
pip install ragnarok-ai[anthropic] # Anthropic support
# Vector stores
pip install ragnarok-ai[qdrant] # Qdrant support
pip install ragnarok-ai[chroma] # ChromaDB support
pip install ragnarok-ai[faiss] # FAISS support
# RAG frameworks
pip install ragnarok-ai[langchain] # LangChain/LangGraph support
pip install ragnarok-ai[llamaindex] # LlamaIndex support
pip install ragnarok-ai[dspy] # DSPy support
# Observability
pip install ragnarok-ai[telemetry] # OpenTelemetry tracing
# Everything
pip install ragnarok-ai[all]
Development
git clone https://github.com/2501Pr0ject/RAGnarok-AI.git
cd RAGnarok-AI
pip install -e ".[dev]"
pre-commit install
Use Cases
Continuous RAG Testing in CI/CD
# .github/workflows/rag-tests.yml
- uses: 2501Pr0ject/ragnarok-evaluate-action@v1
with:
config: ragnarok.yaml
threshold: 0.8
# fail-on-threshold: false (default - advisory only)
# comment-on-pr: true (default - posts PR comment)
The action posts a PR comment distinguishing deterministic retrieval metrics from advisory LLM-as-Judge scores.
Compare Embedding Models
configs = [
{"embedder": "nomic-embed-text", "chunk_size": 512},
{"embedder": "mxbai-embed-large", "chunk_size": 256},
]
results = await benchmark(
rag_factory=create_rag,
configs=configs,
testset=testset,
)
results.compare() # Side-by-side comparison
Monitor Production Quality
# Track quality drift over time
metrics = await evaluate(rag, production_queries)
metrics.log_to("./metrics/") # Time-series storage
Metrics
Retrieval Metrics
- Precision@K — Relevant docs in top K results
- Recall@K — Coverage of relevant docs
- MRR — Mean Reciprocal Rank
- NDCG — Normalized Discounted Cumulative Gain
Generation Metrics
- Faithfulness — Is the answer grounded in retrieved context?
- Relevance — Does the answer address the question?
- Hallucination — Does the answer contain fabricated info?
- Completeness — Are all aspects of the question covered?
LLM-as-Judge (v1.2+)
Use Prometheus 2 for comprehensive, local evaluation:
from ragnarok_ai import LLMJudge
# Initialize judge (uses Prometheus 2 by default)
judge = LLMJudge()
# Evaluate a single response
result = await judge.evaluate_all(
context="Python was created by Guido van Rossum in 1991.",
question="Who created Python?",
answer="Guido van Rossum created Python.",
)
print(f"Overall: {result.overall_verdict} ({result.overall_score:.2f})")
# Overall: PASS (0.85)
print(f"Faithfulness: {result.faithfulness.verdict}")
print(f"Hallucination: {result.hallucination.verdict}")
Performance:
- ~20-30s per evaluation on Apple M2 16GB
- Prometheus 2 Q5_K_M: ~5GB RAM usage
keep_aliveenabled by default (prevents model unloading between requests)
Installation:
# Install Prometheus 2 (~5GB, runs on 16GB RAM)
ollama pull hf.co/RichardErkhov/prometheus-eval_-_prometheus-7b-v2.0-gguf:Q5_K_M
Medical Mode
Reduce false positives in healthcare RAG evaluation with automatic medical abbreviation normalization.
from ragnarok_ai import LLMJudge
# Enable medical mode
judge = LLMJudge(medical_mode=True)
# "CHF" and "congestive heart failure" are now treated as equivalent
result = await judge.evaluate_faithfulness(
context="Patient diagnosed with CHF.",
question="What condition does the patient have?",
answer="Patient has congestive heart failure.",
)
# Without medical_mode: may flag as unfaithful (text mismatch)
# With medical_mode: correctly identifies as faithful
Features:
- 350+ medical abbreviations (CHF, MI, COPD, DVT...)
- Context-aware disambiguation (MS = multiple sclerosis vs mitral stenosis)
- Multiple formats: dotted (q.d.), slash (s/p), mixed-case (SpO2)
- False positive filtering (OR, US, IT stay unchanged)
Also works with FaithfulnessEvaluator(llm, medical_mode=True).
Contributed by @harish1120
System Metrics
- Latency — End-to-end response time
- Token usage — Cost tracking for LLM calls
Cost Tracking (v1.3+)
Track exactly what your evaluations cost:
results = await evaluate(rag, testset, track_cost=True)
print(results.cost)
# +--------------------+------------+----------+
# | Provider | Tokens | Cost |
# +--------------------+------------+----------+
# | ollama (local) | 45,230 | $0.00 |
# | openai | 12,500 | $0.38 |
# +--------------------+------------+----------+
Local-first advantage: Ollama evaluations cost $0.00.
Jupyter Notebook (v1.3.1+)
Rich HTML display for evaluation results:
from ragnarok_ai.notebook import display, display_comparison
# Full dashboard with metrics, cost, latency
display(results)
# Compare multiple pipelines side-by-side
display_comparison([
("Baseline", baseline_results),
("Improved", improved_results),
])
Roadmap
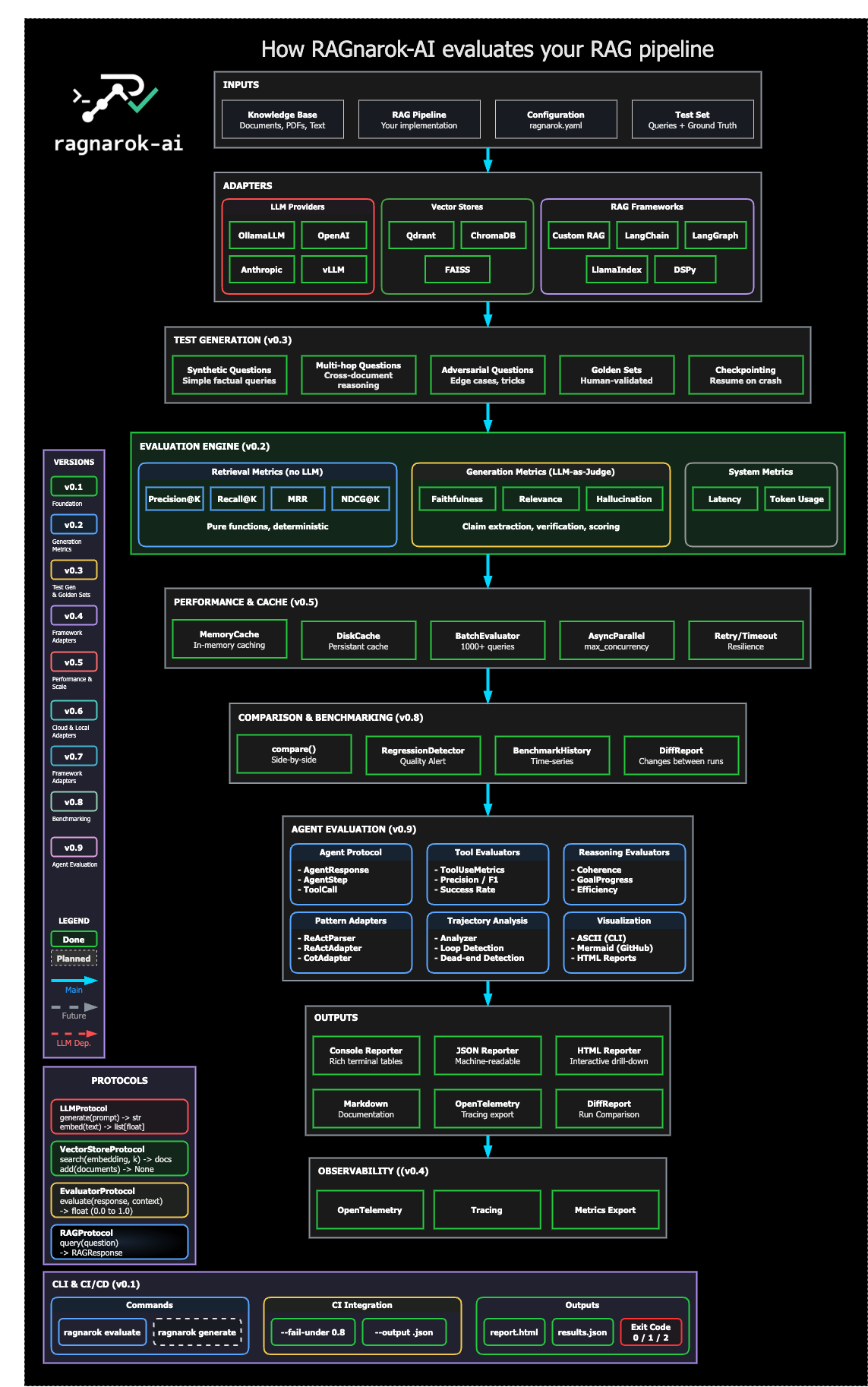
Completed
v0.1 — Foundation
- Project setup & architecture
- Core retrieval metrics (precision, recall, MRR, NDCG)
- Ollama adapter
- Console reporter
- JSON reporter
- Basic CLI
- CI/CD with GitHub Actions
v0.2 — Generation Metrics & Reporting
- Qdrant adapter
- Faithfulness evaluator
- Relevance evaluator
- Hallucination detection
- HTML report with drill-down (failed questions, retrieved chunks)
- Intelligent CI gating (stable metrics fail, LLM judgments warn)
v0.3 — Test Generation & Golden Sets
- Synthetic question generation
- Multi-hop question support
- Adversarial question generation
- Checkpointing system
- Golden set support (human-validated, versioned question sets)
- Baselines library (configs + expected results)
- NovaTech example dataset for quickstart
v0.4 — Framework Adapters & Observability
- LangChain integration
- LangGraph integration
- Custom RAG protocol support
- OpenTelemetry export for tracing & debugging
v0.5 — Performance & Scale
- Async parallelization (
max_concurrencyparameter) - Result caching (
MemoryCache,DiskCache,CacheProtocol) - Batch processing (
BatchEvaluatorfor 1000+ queries) - Progress callbacks (sync and async support)
- Timeout and retry (
timeout,max_retries,retry_delay) - Cache error handling (graceful degradation)
v0.6 — Cloud & Local Adapters
- vLLM adapter (local high-performance inference)
- OpenAI adapter (optional cloud fallback)
- Anthropic adapter
- ChromaDB adapter
- FAISS adapter (pure local, no server)
v0.7 — Framework Adapters
- LlamaIndex adapter (Retriever, QueryEngine, Index)
- DSPy adapter (Retrieve, Module, RAG pattern)
- Custom RAG support via
RAGProtocol - Adapter contribution guide
v0.8 — Comparison & Benchmarking
- Comparison mode (
compare()for side-by-side evaluation) - Regression detection (alert on quality drop vs baseline)
- Benchmark history tracking (time-series storage)
- Diff reports (what changed between runs)
v0.9 — Agent Evaluation
-
AgentProtocolfor agent pipelines - Tool-use correctness metrics (precision, recall, F1)
- Multi-step reasoning evaluators (coherence, goal progress, efficiency)
- ReAct/CoT pattern adapters
- Trajectory analysis (loops, dead ends, failure detection)
- Visualization (ASCII, Mermaid, HTML reports)
v1.0 — Production Ready
- PyPI publish (
pip install ragnarok-ai) - Stable public API
- Complete README with examples
- CHANGELOG.md (v0.1 → v1.0)
v1.1 — CLI Complete
-
ragnarok generatecommand (synthetic testset generation) -
ragnarok benchmarkcommand (history tracking, regression detection) - Standardized JSON envelope for
--jsonoutput - E2E tests for CLI workflow
- Trusted Publishing (PyPI OIDC)
v1.2 — LLM-as-Judge
-
LLMJudgeclass with Prometheus 2 integration - Multi-criteria evaluation (faithfulness, relevance, hallucination, completeness)
- 100% local evaluation with Ollama (Q5_K_M quantization, ~5GB)
- Rubric-based prompts with 1-5 scoring normalized to 0-1
- Detailed explanations for each judgment
- Batch evaluation support
- Robust JSON parsing for LLM responses (handles incomplete JSON)
-
keep_alivesupport for Ollama (prevents model unloading between requests)
v1.2.5 — Plugin Architecture
- Plugin system based on Python entry points
-
PluginRegistrysingleton for adapter discovery - Dynamic discovery of external plugins via
importlib.metadata -
ragnarok pluginsCLI command (list, info, filters) - Support for 4 namespaces: llm, vectorstore, framework, evaluator
- LOCAL/CLOUD classification for all adapters
- Plugin documentation (
docs/PLUGINS.md) - E2E plugin test with mock package
v1.3.0 — Cost Tracking
- Cost tracking module (
ragnarok_ai.cost) - Pricing table for OpenAI, Anthropic, Groq, Mistral, Together AI
- Token counting with tiktoken (fallback to estimation)
-
CostTrackerclass with context manager support -
track_cost=Trueparameter inevaluate() - Formatted summary table and JSON export
- Local providers (Ollama, vLLM) = $0.00
- Automatic tracking in LLM adapters
v1.3.1 — Jupyter Integration
- Jupyter notebook module (
ragnarok_ai.notebook) - Rich HTML display for evaluation results
- Metrics visualization with progress bars
- Cost breakdown tables
- Pipeline comparison display
- Auto-detection of notebook environment
v1.4.0 — More Integrations
- LLM Adapters: Groq, Mistral, Together AI
- VectorStore Adapters: Pinecone, Weaviate, Milvus, pgvector
- Framework Adapters: Haystack, Semantic Kernel
- Medical Mode: Abbreviation normalizer with 350+ terms (contributed by @harish1120)
- CLI:
ragnarok judgecommand,--config ragnarok.yamlsupport - Docs: MkDocs documentation site, performance benchmarks
v1.4.1 — Dataset Versioning
- Shared hashing utilities: Canonical JSON, SHA256, content-based keys
- TestSet versioning:
schema_version,dataset_version,created_at,author,source - Dataset diff:
ragnarok dataset diffCLI command - Stable item keys:
metadata.idor content hash fallback - Diff report: Added/removed/modified/unchanged detection
v1.5.0 — Enterprise Deployment
- Kubernetes Helm Chart: Job and CronJob modes, ConfigMap, PVC support
- Air-Gapped Deployment Guide: Complete documentation for offline environments
- Docker improvements: Fixed Dockerfile for proper module installation
- Data Sovereignty: Full support for GDPR, HIPAA, defense environments
v1.6.0 — Production Monitoring
- MonitorClient: Instrument RAG pipelines with configurable sampling
- Monitor Daemon: HTTP server with
/ingest,/metrics,/health,/stats - Prometheus Export: Request counts, success rate, latency percentiles
- SQLite Storage: 7-day trace retention, 90-day aggregate retention
- CLI Commands:
ragnarok monitor start|stop|status|stats - PII Safety: Query hashing (SHA256)
- Custom Metadata: Tenant/route slicing support
v1.7.0 — Alerting
- AlertManager: Multi-channel alert dispatch with concurrent sending
- AlertRule: Threshold-based rules with cooldown support
- WebhookAlertAdapter: Generic HTTP webhook notifications
- SlackAlertAdapter: Slack notifications with Block Kit formatting
- Alert Protocols: Alert, AlertResult, AlertSeverity (INFO, WARNING, CRITICAL)
- Public Exports: AlertManager, AlertRule, AlertSeverity from package root
Planned
v1.8+
- More alert adapters (Discord, Email)
- Drift detection
- Web UI dashboard
Future
Web UI
- Basic Web UI (read-only dashboard)
- Full Web UI dashboard
Developer Experience
- GitHub Action (
2501Pr0ject/ragnarok-evaluate-action) - VS Code extension
- Interactive CLI (TUI)
- Rust acceleration for hot paths
Advanced Features
- Streaming evaluation
- A/B testing support
- Dataset versioning
- Fine-tuning recommendations
- Multi-modal evaluation (images, audio)
Enterprise (On-Premise)
- SSO support (SAML, OIDC)
- Role-based access control
- Audit logging
- Air-gapped deployment guide
- Docker/Kubernetes helm charts
Architecture
View project structure
ragnarok-ai/
├── src/ragnarok_ai/
│ ├── core/ # Types, protocols, exceptions
│ ├── evaluators/ # Metric implementations
│ ├── generators/ # Test set generation
│ ├── adapters/ # LLM, vector store, framework adapters
│ ├── reporters/ # Output formatters (JSON, HTML, console)
│ └── cli/ # Command-line interface
├── tests/ # Test suite (pytest)
├── examples/ # Usage examples
├── benchmarks/ # Performance benchmarks
└── docs/ # Documentation
Development
# Setup
uv pip install -e ".[dev]"
pre-commit install
# Run checks
pytest # Tests
pytest --cov=ragnarok_ai # With coverage
ruff check . --fix # Lint
ruff format . # Format
mypy src/ # Type check
Advanced Usage
Importing Types
For advanced use cases (custom RAG implementations, type hints), import types directly from submodules:
# Core types
from ragnarok_ai.core.types import Document, Query, RAGResponse, TestSet
# Protocols (for implementing custom adapters)
from ragnarok_ai.core.protocols import RAGProtocol, LLMProtocol, VectorStoreProtocol
# Evaluators
from ragnarok_ai.evaluators import FaithfulnessEvaluator, RelevanceEvaluator
# Adapters
from ragnarok_ai.adapters.llm import OllamaLLM, OpenAILLM
from ragnarok_ai.adapters.vectorstore import ChromaVectorStore, QdrantVectorStore
Implementing a Custom RAG
from ragnarok_ai.core.protocols import RAGProtocol
from ragnarok_ai.core.types import RAGResponse, Document
class MyCustomRAG:
"""Custom RAG implementing the RAGProtocol."""
async def query(self, question: str, k: int = 5) -> RAGResponse:
# Your retrieval logic here
docs = await self.retrieve(question, k)
answer = await self.generate(question, docs)
return RAGResponse(
answer=answer,
retrieved_docs=[
Document(id=d.id, content=d.text, metadata=d.meta)
for d in docs
],
)
# Use with ragnarok-ai
from ragnarok_ai import evaluate
results = await evaluate(
rag_pipeline=MyCustomRAG(),
testset=testset,
metrics=["retrieval", "faithfulness"],
)
Feedback
Your feedback helps improve RAGnarok-AI. Pick the right channel:
| Type | Link |
|---|---|
| Bug report | Report a bug |
| Feedback / UX | Share feedback |
| Feature request | Request a feature |
| Questions / Ideas | Discussions |
Contributing
Contributions are welcome! Please read CONTRIBUTING.md for guidelines.
Priority areas for contributions:
- Framework adapters (Haystack, Semantic Kernel)
- Agent evaluation features
- Streaming evaluation support
- Multi-modal evaluation
- Documentation & examples
License
RAGnarok-AI is dual-licensed:
| License | Use Case |
|---|---|
| AGPL-3.0 | Open source projects, personal use, research |
| Commercial | Proprietary software, SaaS, organizations with AGPL restrictions |
Why dual licensing?
- AGPL ensures improvements stay open-source
- Commercial license enables enterprise adoption without copyleft obligations
For commercial licensing inquiries: abdel.touati@gmail.com
Acknowledgments
Built out of frustration with complex evaluation setups. We wanted something that just works — locally, fast, and without API keys.
Built with ❤️ in Lyon, France
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file ragnarok_ai-1.7.0.tar.gz.
File metadata
- Download URL: ragnarok_ai-1.7.0.tar.gz
- Upload date:
- Size: 367.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
840deb441da53ecec4c8a91ad045ffae5847832a06a246db9daa928d2a36c726
|
|
| MD5 |
e7f1d0e98f70f9d7da99e17a67a9bdfd
|
|
| BLAKE2b-256 |
546740546d9e779bbcfc3395548003d75d1b561fbf0ae2c1e3ead7e87238ae2b
|
Provenance
The following attestation bundles were made for ragnarok_ai-1.7.0.tar.gz:
Publisher:
publish.yml on 2501Pr0ject/RAGnarok-AI
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
ragnarok_ai-1.7.0.tar.gz -
Subject digest:
840deb441da53ecec4c8a91ad045ffae5847832a06a246db9daa928d2a36c726 - Sigstore transparency entry: 955139660
- Sigstore integration time:
-
Permalink:
2501Pr0ject/RAGnarok-AI@c651c282564dacb3ce6d9c65564f0cad8f34deaf -
Branch / Tag:
refs/tags/v1.7.0 - Owner: https://github.com/2501Pr0ject
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@c651c282564dacb3ce6d9c65564f0cad8f34deaf -
Trigger Event:
push
-
Statement type:
File details
Details for the file ragnarok_ai-1.7.0-py3-none-any.whl.
File metadata
- Download URL: ragnarok_ai-1.7.0-py3-none-any.whl
- Upload date:
- Size: 309.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e6efc74fc49ed6ff0c3d0b654e54693e5295cf920c777fb74b7eecb8ad1641e8
|
|
| MD5 |
0d52cf3a248e0714cc069c6ff35804a2
|
|
| BLAKE2b-256 |
5f2026590a9c410ffd552cb0f96d76fc85d0ef53a07cee0f21a8be8f9ffc785e
|
Provenance
The following attestation bundles were made for ragnarok_ai-1.7.0-py3-none-any.whl:
Publisher:
publish.yml on 2501Pr0ject/RAGnarok-AI
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
ragnarok_ai-1.7.0-py3-none-any.whl -
Subject digest:
e6efc74fc49ed6ff0c3d0b654e54693e5295cf920c777fb74b7eecb8ad1641e8 - Sigstore transparency entry: 955139663
- Sigstore integration time:
-
Permalink:
2501Pr0ject/RAGnarok-AI@c651c282564dacb3ce6d9c65564f0cad8f34deaf -
Branch / Tag:
refs/tags/v1.7.0 - Owner: https://github.com/2501Pr0ject
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@c651c282564dacb3ce6d9c65564f0cad8f34deaf -
Trigger Event:
push
-
Statement type:







