Hybrid structure-aware retrieval — BM25 + embeddings + document graph expansion. Runs fully offline, no API key required.

Project description
RAGNav






Production-grade hybrid retrieval — BM25 plus dense embeddings plus optional structure-aware expansion. With sentence-transformers (default), you can index and query without any API key or separate LLM client for the common path below.
| Result | Detail |
|---|---|
| SQuAD R@3 | 0.956 (500 questions, hybrid RRF, zero paid API calls) |
| CUAD span S@3 | 0.071 (clause-friendly metric; see benchmarks) |
Frontier-LLM “build an index per document” stacks optimize a different cost and reproducibility tradeoff; RAGNav targets pip-install hybrid search with offline, reproducible benchmarks.
pip install ragnav[embeddings]
from ragnav import RAGNavIndex, RAGNavRetriever
from ragnav.ingest.markdown import ingest_markdown_string
doc, blocks = ingest_markdown_string(
"Paris is the capital of France.",
name="demo.md",
)
index = RAGNavIndex.build(
documents=[doc],
blocks=blocks,
use_sentence_transformers=True,
vector_model="all-MiniLM-L6-v2",
embed_batch_size=32,
)
retriever = RAGNavRetriever(index=index)
result = retriever.retrieve(
"What is the capital of France?",
top_k=5,
expand_structure=False,
expand_graph=False,
)
print(result.blocks[0].text)
print(result.confidence)
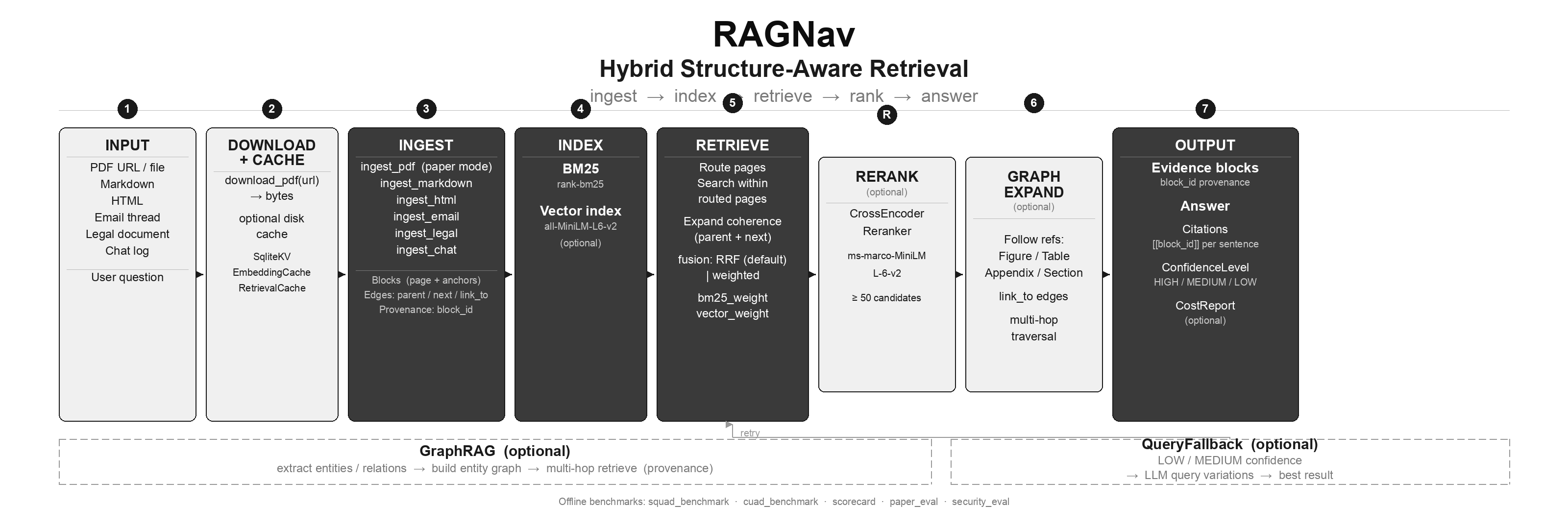
Regenerate this figure: python3 scripts/gen_architecture.py (needs Pillow, e.g. pip install ragnav[dev]).
Long PDFs and paper mode
For papers and long PDFs, use navigation-first routing (pages → evidence → optional link_to refs). That workflow is not required for the markdown snippet above; see Quickstart (Python): papers and the CLI section below.
The problem (why long-document QA fails)
LLMs have finite context windows and degrade on long inputs (“lost in the middle” effects). In long PDFs (papers, reports, manuals), naive retrieval often returns plausible text but misses the right place.
Why classic vector + chunk RAG fails (in PDFs)
- Intent mismatch: the query expresses intent; the most similar text isn’t always the most relevant.
- Hard chunking breaks meaning: chunks cut across sections/tables/captions, losing provenance and coherence.
- Similarity ≠ relevance: many sections look semantically similar (especially in technical documents).
- Cross-references: “see Figure 3 / Table 2 / Appendix A / Section 4.1” rarely matches the referenced content.
- No navigation: users don’t want “top-k chunks”; they want where the answer lives + traceable evidence.
RAGNav’s approach (navigation-first retrieval loop)
RAGNav is built around a simple loop:
- Ingest (paper mode): PDF → blocks with
anchors={"page": N}+ edges (parent,next,link_to). - Route: query → rank likely pages.
- Retrieve: search within routed pages (hybrid BM25 + embeddings).
- Expand: add coherence (section headers + adjacent “next” blocks).
- Follow refs (optional): traverse
link_toedges (Figure/Table/Appendix/Section). - Answer: generate from retrieved evidence (optionally with inline citations).
The “index” (what the model navigates)
RAGNav normalizes everything into a small graph:
Block {
block_id: "pdf:paper.pdf#b19"
doc_id: "pdf:paper.pdf"
text: "..."
anchors: { page: 5, line_start: 12, line_end: 20 }
}
Edge {
type: "parent" | "next" | "link_to" | ...
src: block_id
dst: block_id
}
This graph is the in-process “index” the retriever navigates: pages, headings, cross-references, and provenance.
Vector RAG vs RAGNav (paper-mode)
| Problem | Vector + chunks | RAGNav (navigation-first) |
|---|---|---|
| Find “where” in a paper | Not explicit | Routes pages + sections |
| Cross-references (“see Appendix”) | Usually missed | Follows link_to edges |
| Provenance | Weak (chunk ids) | Page + block ids + anchors |
| Coherence | Fragmented | Deterministic expansion (parent/next) |
| Evaluation | Ad-hoc | Built-in offline suites + scorecard |
Use cases
- Research papers (PDF): page routing + cross-ref following.
- Reports / manuals / specs: structure-aware retrieval (coherent evidence, not fragments).
- Grounded answers: inline citations
[[block_id]]per sentence (optional). - Security baseline: drop prompt-injection blocks and redact obvious secrets (optional).
- GraphRAG: entity graph + multi-hop traversal with provenance (optional).
Acknowledgements & prior art
RAGNav is an independent project. It builds on long-standing information retrieval practice (lexical BM25, hybrid fusion with dense retrieval) and open embedding models — document structure as a first-class signal has roots in IR, digital libraries, and structured PDF tooling, not a single product.
- PyMuPDF: PDF text extraction is powered by
pymupdf(optional dependency). - BM25 / classic IR: Lexical retrieval uses BM25-style scoring.
- Mistral: Optional LLM/embedding client for chat, routing, and API-backed embed fallback.
RAGNav is not affiliated with the vendors above. If you notice missing or incorrect attribution, please open an issue.
Install
From PyPI (recommended):
pip install ragnav[embeddings]
Optional extras: ragnav[pdf], ragnav[messy] (HTML), ragnav[reranking], ragnav[mistral], ragnav[all] (see pyproject.toml; mistral is omitted from all).
Development (clone)
git clone https://github.com/irfanalidv/RAGNav.git
cd RAGNav
pip install -e ".[dev,pdf,messy]"
# optional: pip install -e ".[mistral]"
Setup (Mistral)
Do not hardcode or commit keys. Use env vars:
export MISTRAL_API_KEY="your_key_here"
Quickstart (CLI): run on an arXiv PDF URL
Install:
pip install "ragnav[mistral,pdf]"
export MISTRAL_API_KEY="..."
Run (recommended: paper-mode navigation):
ragnav paper-pdf --pdf-url "https://arxiv.org/pdf/2507.13334.pdf" --query "What is Context Engineering?"
Jupyter notebook quickstart
Open:
cookbook/ragnav_quickstart.ipynb— offline SQuAD demo + confidence + QueryFallback (run in Colab)cookbook/ragnav_paper_quickstart.ipynb
Other modes (optional):
- Hybrid (BM25 + embeddings, generic PDF blocks):
ragnav hybrid-pdf --pdf-url "https://arxiv.org/pdf/2507.13334.pdf" --query "What is Context Engineering?"
- Vectorless (BM25-only, generic PDF blocks):
ragnav vectorless-pdf --pdf-url "https://arxiv.org/pdf/2507.13334.pdf" --query "What is Context Engineering?"
- Agentic retrieval loop:
ragnav agentic-pdf --pdf-url "https://arxiv.org/pdf/2507.13334.pdf" --query "Summarize the paper's main contribution."
Real example output (paper-mode navigation)
This repo includes a paper-mode demo that downloads an arXiv PDF and runs page routing + retrieval:
python3 examples/papers/ragnav_paper_rag_pdf.py \
--pdf-url "https://arxiv.org/pdf/2507.13334.pdf" \
--pdf-name "2507.13334.pdf" \
--max-pages 25
Output (real, trimmed):
## Routed pages
- doc_id=pdf:2507.13334.pdf page=4 score=0.5423 N=3
- doc_id=pdf:2507.13334.pdf page=14 score=0.5298 N=7
- doc_id=pdf:2507.13334.pdf page=9 score=0.4662 N=4
- doc_id=pdf:2507.13334.pdf page=5 score=0.4597 N=3
## Retrieved evidence blocks (first 10)
- page=14 title=Sr-Nle [1130] id=pdf:2507.13334.pdf#b106
- page=2 title=Related Work id=pdf:2507.13334.pdf#b11
...
Quickstart (Python): papers (recommended)
PaperRAG (page routing + cross-ref following)
from ragnav.llm.mistral import MistralClient
from ragnav.net import download_pdf
from ragnav.papers import PaperRAG, PaperRAGConfig
llm = MistralClient()
cfg = PaperRAGConfig(max_pages=25, top_pages=4, follow_refs=True)
pdf_bytes = download_pdf("https://arxiv.org/pdf/2507.13334.pdf")
paper = PaperRAG.from_pdf_bytes(pdf_bytes, llm=llm, pdf_name="paper.pdf", cfg=cfg)
print(paper.answer("What experiments were conducted?", cfg=cfg))
Grounded answering (inline citations per sentence)
print(paper.answer_cited("What does Figure 1 show?", cfg=cfg))
Output format:
Sentence one [[pdf:paper.pdf#b12]].
Sentence two [[pdf:paper.pdf#b47]] [[pdf:paper.pdf#b48]].
Quickstart: GraphRAG (entity multi-hop with provenance)
from ragnav.graphrag import build_entity_graph, EntityGraphRetriever
eg = build_entity_graph(blocks) # blocks are RAGNav Block objects
egr = EntityGraphRetriever(graph=eg, blocks_by_id={b.block_id: b for b in blocks})
out = egr.retrieve("Which dataset was BERT evaluated on?")
for b in out["blocks"][:3]:
print(b.block_id, b.anchors.get("page"))
Networked PDF demo:
pip install "ragnav[mistral,pdf]"
export MISTRAL_API_KEY="..."
python3 examples/graphs/ragnav_entity_graphrag_pdf.py
Production features
Features PageIndex does not have:
| Feature | What it does |
|---|---|
ConfidenceLevel |
Every retrieval result carries HIGH/MEDIUM/LOW confidence so you can decide whether to show the answer or say "I'm not sure." |
QueryFallback |
On LOW/MEDIUM confidence, automatically retries with LLM-generated query rephrasing. Prevents silent failures. |
CostTracker |
Tracks token usage and cost per LLM call. Set a budget_usd to get BudgetExceededError before you overspend. |
CrossEncoderReranker |
Optional second-stage reranker with ≥50 first-stage candidates (see retrieve()). On small SQuAD-style corpora the default MS MARCO MiniLM reranker can trail hybrid RRF alone; use domain-tuned models or skip reranking when the pool is easy. |
| Multi-format ingest | PDF, markdown, HTML, email chains, chat logs, legal/numbered documents. |
| No API key required | Runs fully offline with sentence-transformers. |
Use any LLM
RAGNav works with any LLM. Built-in: Mistral. For others, one small wrapper:
from openai import OpenAI
from ragnav.llm.base import LLMClient
from ragnav.llm.mistral import MistralClient
# Mistral (built-in) — MISTRAL_API_KEY
llm = MistralClient()
# OpenAI — pip install openai — OPENAI_API_KEY
class OpenAIClient(LLMClient):
def __init__(self):
self.client = OpenAI()
def chat(self, *, messages, model=None, temperature=0.0):
r = self.client.chat.completions.create(
model=model or "gpt-4o-mini",
messages=messages,
temperature=temperature,
)
return r.choices[0].message.content or ""
def embed(self, *, inputs, model=None):
r = self.client.embeddings.create(
model=model or "text-embedding-3-small",
input=list(inputs),
)
return [d.embedding for d in r.data]
# Pass either client to RAGNavRetriever(..., llm=...), PaperRAG(..., llm=...), QueryFallback(..., llm=...).
Anthropic, Groq, Ollama — same pattern (~10 lines each).
Benchmarks
Reproduce with benchmarks/squad_benchmark.py and benchmarks/cuad_benchmark.py after pip install ragnav[embeddings] datasets. No API key for SQuAD or CUAD. Default hybrid path uses RRF; optional cross-encoder reranking is RAGNavRetriever(reranker=...).
Retrieval accuracy
| Dataset | Method | R@1 | R@3 | R@5 | MRR@10 |
|---|---|---|---|---|---|
| SQuAD | BM25-only | 0.852 | 0.932 | 0.950 | 0.896 |
| SQuAD | Embedding-only | 0.772 | 0.906 | 0.942 | 0.844 |
| SQuAD | RAGNav hybrid (RRF 0.5/0.5) | 0.864 | 0.956 | 0.978 | 0.912 |
| SQuAD | Hybrid RRF + cross-encoder reranker | 0.862 | 0.944 | 0.968 | 0.906 |
| CUAD (block-level) | BM25-only | 0.017 | 0.040 | 0.044 | 0.032 |
| CUAD (block-level) | RAGNav hybrid (legal ingest + RRF) | 0.007 | 0.047 | 0.051 | 0.027 |
| CUAD (block-level) | RAGNav + graph expansion | 0.007 | 0.047 | 0.051 | 0.027 |
CUAD — span recall (concatenated top-k blocks)
Gold answer span may sit across legal-ingest block boundaries; span S@k is true if any gold string appears in the concatenation of the top-k retrieved blocks’ text (fairer for clauses).
| Dataset | Method | S@1 | S@3 | S@5 | MRR@10 |
|---|---|---|---|---|---|
| CUAD (span) | BM25-only | 0.020 | 0.061 | 0.071 | 0.044 |
| CUAD (span) | RAGNav hybrid (legal ingest + RRF) | 0.010 | 0.071 | 0.074 | 0.037 |
| CUAD (span) | RAGNav + graph expansion | 0.010 | 0.071 | 0.074 | 0.037 |
SQuAD: 500 questions, 447 unique passages, rajpurkar/squad validation set, CC BY-SA 4.0
CUAD: 300 questions sampled (297 with gold locatable in the indexed blocks after legal ingest), theatticusproject/cuad-qa test JSON (official zip), CC BY 4.0. Block-level R@k requires a gold block_id in the top-k list; span S@k only requires the gold answer text to appear in the merged text of those blocks.
vs. PageIndex (illustrative)
| PageIndex | RAGNav | |
|---|---|---|
| Requires GPT-4o / paid LLM for core tree workflow | Yes | No — hybrid retrieval with local embeddings by default |
| Fully offline (no API key) | No | Yes |
| SQuAD R@3 | Not published | 0.956 (hybrid RRF) |
| CUAD clause retrieval (span S@3) | Not published | 0.071 (hybrid RRF + legal ingest; block-level R@3 in results file) |
| Handles markdown / chat / email | No | Yes |
| Structure-aware graph expansion | No | Yes |
FinanceBench: Often cited with a frontier LLM and a finance-PDF setup. RAGNav does not ship that harness: it would imply paid API runs and a different evaluation contract than the offline SQuAD/CUAD suites above. Treat FinanceBench as out of scope for this repo until a reproducible, keyless or clearly documented protocol is added.
One-command scorecard (offline)
python3 -m benchmarks.scorecard
Example output:
{
"ok": true,
"suites": [
{ "name": "offline_smoke", "ok": true },
{ "name": "paper_eval", "ok": true, "json": { "suite": "paper_crossref_v1", "follow_refs_true": { "block_hit_rate": 1.0 } } },
{ "name": "entity_eval_excerpt", "ok": true, "json": { "suite": "entity_excerpt_v1" } },
{ "name": "security_eval", "ok": true }
]
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters







