A Python library that enables smooth keyword extraction from any text using the RAKE(Rapid Automatic Keyword Extraction) algorithm.

Project description
rake_new2
rake_new2 is a Python library that enables simple and fast keyword extraction from any text. As the name implies, this library works on the RAKE(Rapid Automatic Keyword Extraction) algorithm.
It tries to determine the key phrases in a text by calculating the co-occurrences of every word in a key phrase and also its frequency in the entire text.
New in this version
-
Handles repetitive keywords/key-phrases
-
Handles consecutive punctuations.
-
Handles HTML tags in text : The user is allowed an option to choose if they want to keep HTML tags as keywords too.
Installation
Use the package manager pip to install rake_new2.
pip install rake_new2
Quick Start
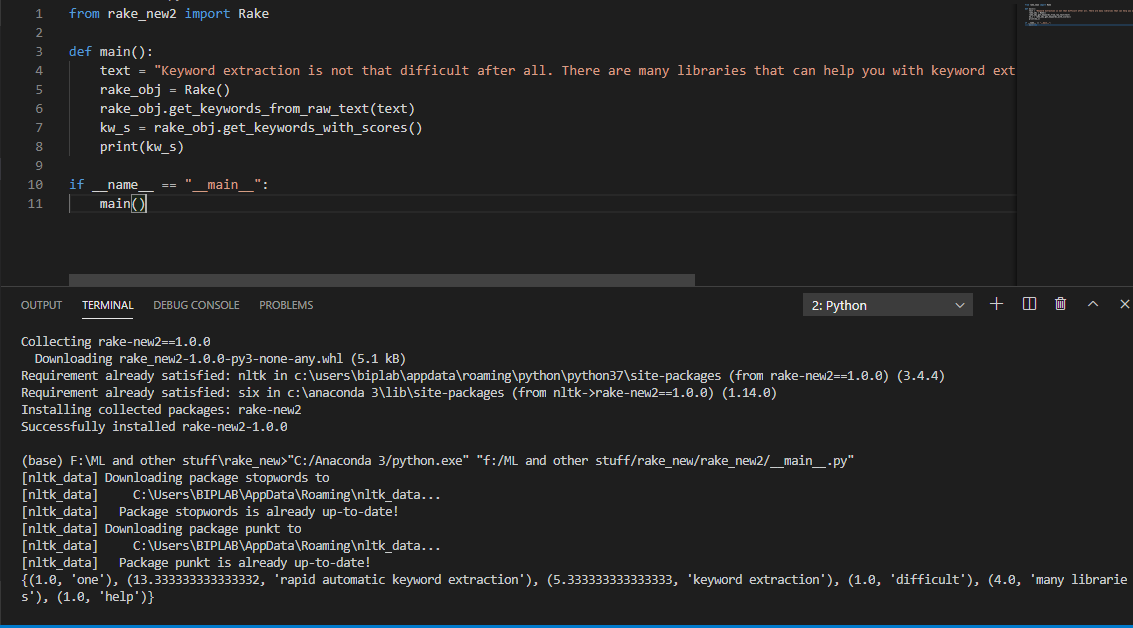
from rake_new2 import Rake
text = "Red apples are good in taste."
text2 = "<h1> Hello world !</h1>"
rk,rk_new1,rk_new2 = Rake(),Rake(keep_html_tags=True),Rake(keep_html_tags=False)
# Case 1
# Initialize
rk.get_keywords_from_raw_text(text)
kw_s = rk.get_keywords_with_scores()
# Returns keywords with degree scores : {(1.0, 'taste'), (1.0, 'good'), (4.0, 'red apples')}
kw = rk.get_ranked_keywords()
# Returns keywords only : ['red apples', 'taste', 'good']
f = rk.get_word_freq()
# Returns word frequencies as a Counter object : {'red': 1, 'apples': 1, 'good': 1, 'taste': 1}
deg = rk.get_kw_degree()
# Returns word degrees as defaultdict object : {'red': 2.0, 'apples': 2.0, 'good': 1.0, 'taste': 1.0}
# Case 2 : Sample case for testing the 'keep_html_tags' parameter. Default = False
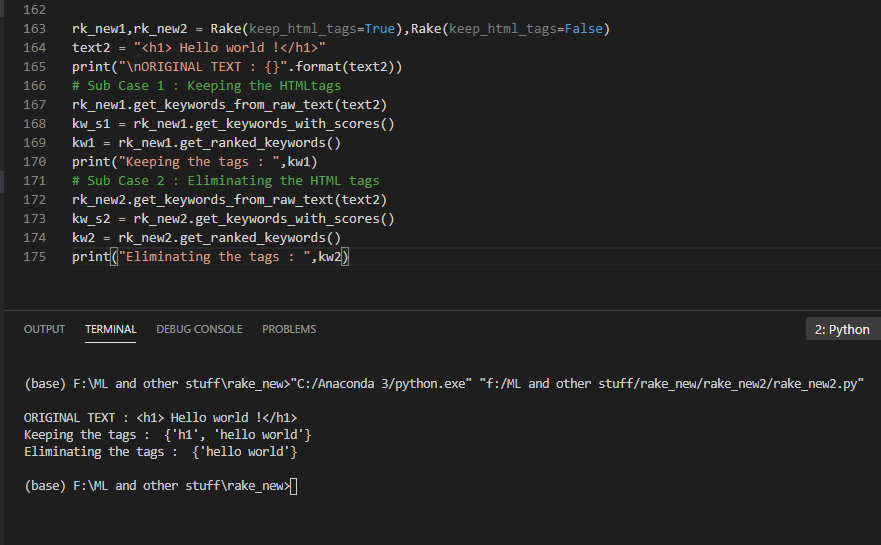
print("\nORIGINAL TEXT : {}".format(text))
# Sub Case 1 : Keeping the HTMLtags
rk_new1.get_keywords_from_raw_text(text2)
kw_s1 = rk_new1.get_keywords_with_scores()
kw1 = rk_new1.get_ranked_keywords()
print("Keeping the tags : ",kw1)
# Sub Case 2 : Eliminating the HTML tags
rk_new2.get_keywords_from_raw_text(text2)
kw_s2 = rk_new2.get_keywords_with_scores()
kw2 = rk_new2.get_ranked_keywords()
print("Eliminating the tags : ",kw2)
'''OUTPUT >>
ORIGINAL TEXT : <h1> Hello world !</h1>
Keeping the tags : {'h1', 'hello'}
Eliminating the tags : {'hello world'}
'''
Debugging
You might come across a stopwords error.
It implies that you do not have the stopwords corpus downloaded from NLTK.
To download it, use the command below.
python -c "import nltk; nltk.download('stopwords')"
Contributing
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.
Please make sure to update tests as appropriate.
License


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file rake_new2-1.0.5.tar.gz.
File metadata
- Download URL: rake_new2-1.0.5.tar.gz
- Upload date:
- Size: 4.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.22.0 setuptools/46.1.3 requests-toolbelt/0.9.1 tqdm/4.32.1 CPython/3.7.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6a48686b20d048c2294a89146c93ed0b73674f997e30d2419f0ae48344e845c3
|
|
| MD5 |
c402ba5e60a396e776da120fa8265a6f
|
|
| BLAKE2b-256 |
ac355ddfa8b5dc9eef44e1a61ff01157ed89f3ad6024f96e9c4f7b08858a7b7b
|
File details
Details for the file rake_new2-1.0.5-py3-none-any.whl.
File metadata
- Download URL: rake_new2-1.0.5-py3-none-any.whl
- Upload date:
- Size: 6.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.1.1 pkginfo/1.5.0.1 requests/2.22.0 setuptools/46.1.3 requests-toolbelt/0.9.1 tqdm/4.32.1 CPython/3.7.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d846098a213a1c8d71ed0b858e31a2a9b01c2c884dfbc541e3582594061fd1b7
|
|
| MD5 |
330e2ee2e6cf9e324a21108c8399cbe1
|
|
| BLAKE2b-256 |
92cc735ecde47d1eac530558039742d6295452ae142965fb830069dde6b58678
|







