Library for implementing reservoir computing models (Echo State Networks) for multivariate time series classification, clustering, and forecasting.

Project description
Time series classification and clustering with Reservoir Computing


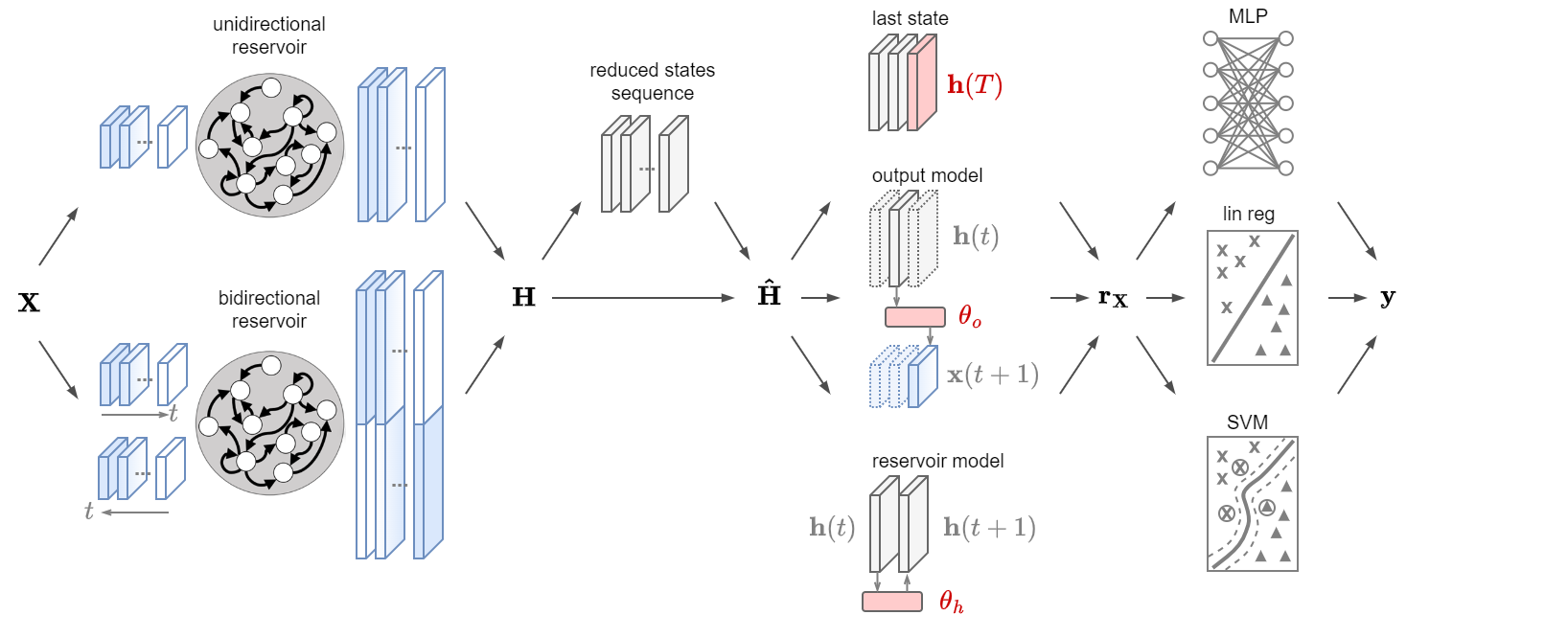
Figure 1: Overview of the RC classifier.
This library allows to quickly implement different architectures for time series data based on Reservoir Computing (RC), the family of approaches popularized in machine learning by Echo State Networks. This library is primarly design to perform classification and clustering of both univariate and multivariate time series. However, it can also be used to perform time series forecasting.
🛠️ Setup
The recommended installation is with pip:
pip install reservoir-computing
Alternatively, you can install the library from source:
git clone https://github.com/FilippoMB/Time-series-classification-and-clustering-with-Reservoir-Computing.git
cd Time-series-classification-and-clustering-with-Reservoir-Computing
pip install -e .
🚀 Getting Started
The following scripts provide minimalistic examples that illustrate how to use the library for different tasks.
To run them, download the project and cd to the root folder:
git clone https://github.com/FilippoMB/Time-series-classification-and-clustering-with-Reservoir-Computing.git
cd Time-series-classification-and-clustering-with-Reservoir-Computing
Classification
python examples/classification_example.py


Clustering
python examples/clustering_example.py
Forecasting
python examples/forecasting_example.py
👀 Overview of the framework
In the following, we present the three main functionalities of this library.
Classification
Referring to Figure 1, the RC classifier consists of four different modules.
- The reservoir module specifies the reservoir configuration (e.g., bidirectional, leaky neurons, circle topology). Given a multivariate time series $\mathbf{X}$ it generates a sequence of the same length of Reservoir states $\mathbf{H}$.
- The dimensionality reduction module (optionally) applies a dimensionality reduction on the sequence of the reservoir's states $\mathbf{H}$ generating a new sequence $\mathbf{\bar H}$.
- The representation generates a vector $\mathbf{r}_\mathbf{X}$ from the sequence of reservoir's states, which represents in vector form the original time series $\mathbf{X}$.
- The readout module is a classifier that maps the representation $\mathbf{r}_\mathbf{X}$ into the class label $\mathbf{y}$, associated with the time series $\mathbf{X}$.
[!Note] This library implements also the reservoir model space, a very powerful representation $\mathbf{r}_\mathbf{X}$ for the time series. Details about the methodology are found in the original paper.
The class RC_model contained in modules.py permits to specify, train and test an RC-model.
Several options are available to customize the RC model, by selecting different configurations for each module.
The training and test function requires in input training and test data, which must be provided as multidimensional numpy arrays of shape [N,T,V], with:
- N = number of samples
- T = number of time steps in each sample
- V = number of variables in each sample
Training and test labels (Ytr and Yte) must be provided in one-hot encoding format, i.e. a matrix [N,C], where C is the number of classes.
from reservoir_computing.modules import RC_model
clf = RC_model()
clf.fit(Xtr, Ytr) # Training
Yhat = clf.predict(Xte) # Prediction
Clustering
The representation $\mathbf{r}_\mathbf{X}$ obtained from the representation module (step 3) can be used to perform time series clustering.
The same class RC_model used for classification can be configured to directly return the time series representations, which can be used in unsupervised tasks such as clustering and dimensionality reduction.
As in the case of classification, the data must be provided as multidimensional NumPy arrays of shape [N,T,V]
from reservoir_computing.modules import RC_model
clst = RC_model(readout_type=None)
clst.fit(X)
rX = clst.input_repr # representations of the input data
The representations rX can be used to perfrom clustering using traditional clustering algorithms for vectorial data, such as those from sk-learn.
Forecasting
The sequences $\mathbf{H}$ and $\mathbf{\bar H}$ obtained at steps 1 and 2 can be directly used to forecast the future values of the time series.
The class RC_forecaster contained in modules.py permits to specify, train and test an RC-model for time series forecasting.
from reservoir_computing.modules import RC_forecaster
fcst = RC_forecaster()
fcst.fit(Xtr, Ytr) # Training
Yhat = fcst.predict(Xte) # Predictions
Here, Xtr, Ytr are current and future values, respectively, used for training.
🧩 Advanced examples
The following notebooks illustrate more advanced use-cases.
- Perform dimensionality reduction, cluster analysis, and visualize the results:
- Probabilistic forecasting with advanced regression models as readout:
- Use advanced classifiers as readout:
- Impute missing data in time series
- Reconstruct the attractor of a dynamical system in the phase space
📦 Datasets
There are several datasets available to perform time series classification/clustering and forecasting.
Classification and clustering
from reservoir_computing.datasets import ClfLoader
downloader = ClfLoader()
downloader.available_datasets(details=True) # Print available datasets
Xtr, Ytr, Xte, Yte = downloader.get_data('Libras') # Download dataset and return data
Forecasting
Real-world time series
from reservoir_computing.datasets import PredLoader
downloader = PredLoader()
downloader.available_datasets(details=False) # Print available datasets
X = downloader.get_data('CDR') # Download dataset and return data
Synthetic time series
from reservoir_computing.datasets import SynthLoader
synth = SynthLoader()
synth.available_datasets() # Print available datasets
Xs = synth.get_data('Lorenz') # Generate synthetic time series
📝 Citation
Please, consider citing the original paper if you are using this library in your reasearch
@article{bianchi2020reservoir,
title={Reservoir computing approaches for representation and classification of multivariate time series},
author={Bianchi, Filippo Maria and Scardapane, Simone and L{\o}kse, Sigurd and Jenssen, Robert},
journal={IEEE Transactions on Neural Networks and Learning Systems},
year={2020},
publisher={IEEE}
}
🌐 License
The code is released under the MIT License. See the attached LICENSE file.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file reservoir_computing-1.0.2.tar.gz.
File metadata
- Download URL: reservoir_computing-1.0.2.tar.gz
- Upload date:
- Size: 19.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.0.1 CPython/3.9.21
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
07ea08a559f821123f09bfe200f4fe13c7ad4b17eeb41973af75359fc25c2904
|
|
| MD5 |
856519505b8323286573284563a48f74
|
|
| BLAKE2b-256 |
e62e71f240b03ee89dce970ac0c83d8f35be7bb8a133dd8c1156870eb5902436
|
File details
Details for the file reservoir_computing-1.0.2-py3-none-any.whl.
File metadata
- Download URL: reservoir_computing-1.0.2-py3-none-any.whl
- Upload date:
- Size: 18.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.0.1 CPython/3.9.21
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
09aceacd38bb04adc461edf1675d3ebb772530582160721e3374534ed782d147
|
|
| MD5 |
966a5820459d80b7e4508670fc643442
|
|
| BLAKE2b-256 |
eddb334a02f3d6142817544d5c05a757a02e275c9a0e848a917b66b0c49b04e6
|







