High-performance OpenAI-compatible embedding server for Roo Code indexing on Apple Silicon
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
roocode-code-indexer-macos
High-performance OpenAI-compatible embedding server for Roo Code codebase indexing on Apple Silicon.
Runs Qwen3 embedding models locally via MLX with optimized batched GPU inference — no API keys needed. Up to 5x faster than Ollama for the same models.
Quick Start
# From PyPI
uvx roocode-code-indexer-macos
# Or from GitHub (latest)
uvx --from git+https://github.com/dmarkey/roocode-code-indexer-macos roocode-code-indexer-macos
Or with the recommended 4B model:
uvx roocode-code-indexer-macos --model mlx-community/Qwen3-Embedding-4B-4bit-DWQ
Roo Code Configuration
In Roo Code settings, set the embedding provider to OpenAI-compatible and point it at:
http://localhost:8000/v1
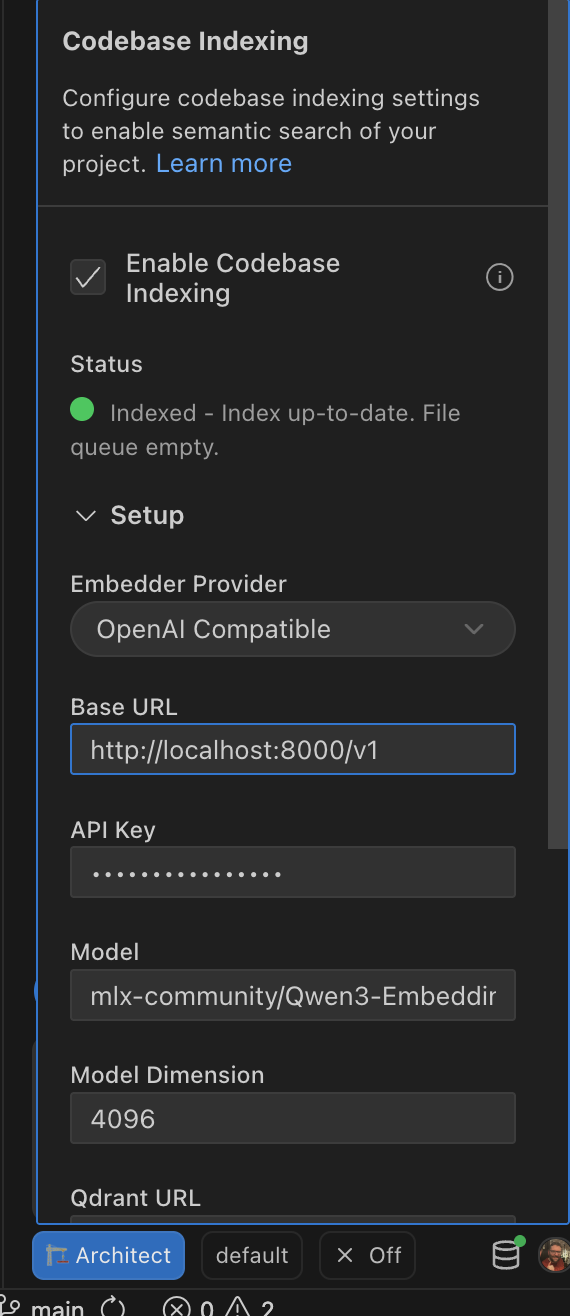
Example using mlx-community/Qwen3-Embedding-8B-4bit-DWQ (4096 dimensions). mlx-community/Qwen3-Embedding-4B-4bit-DWQ (2560 dimensions) is recommended for most use cases.
Available Models
| Model | Embedding Dim | Size | Description |
|---|---|---|---|
mlx-community/Qwen3-Embedding-0.6B-4bit-DWQ |
1024 | ~900MB | Fast, good for small codebases (default) |
mlx-community/Qwen3-Embedding-4B-4bit-DWQ |
2560 | ~2.5GB | Recommended — best speed/quality tradeoff |
mlx-community/Qwen3-Embedding-8B-4bit-DWQ |
4096 | ~4.5GB | Highest quality, slower |
Models are downloaded automatically from HuggingFace on first use.
Benchmarks: MLX vs Ollama
Synthetic code-like text data (10 concurrent requests x 60 texts = 600 texts), simulating Roo Code's indexing burst pattern. Reproducible via python benchmark.py.
Cold cache (first indexing run)
| Server | Wall time | texts/sec | vs Ollama |
|---|---|---|---|
| Ollama qwen3-embedding:0.6b | 9.0s | 67 | baseline |
| Ollama qwen3-embedding:4b | 50.9s | 12 | 0.2x |
| Ollama qwen3-embedding:8b | errors | - | crashed under load |
| MLX Qwen3-Embedding-0.6B | 1.8s | 337 | 5x faster |
| MLX Qwen3-Embedding-4B | 9.0s | 67 | 5.7x faster |
| MLX Qwen3-Embedding-8B | 15.2s | 39 | - |
Warm cache (re-indexing with overlapping files)
| Server | Wall time | texts/sec |
|---|---|---|
| MLX Qwen3-Embedding-0.6B | 42ms | 14,414 |
| MLX Qwen3-Embedding-4B | 95ms | 6,340 |
| MLX Qwen3-Embedding-8B | 146ms | 4,106 |
Ollama has no embedding cache — every re-index pays full inference cost.
Why is MLX faster?
- Request coalescing — concurrent requests are merged into single GPU batches instead of queuing serially
- Length-bucketed sub-batching — minimizes padding waste across variable-length texts
- Compiled Metal kernels —
mx.compilewith fixed padding buckets for graph reuse - LRU embedding cache — repeated texts skip inference entirely
- Last-token pooling — matches Qwen3-Embedding training objective
Environment Variables
| Variable | Default | Description |
|---|---|---|
MODEL_NAME |
mlx-community/Qwen3-Embedding-0.6B-4bit-DWQ |
Default model |
PORT |
8000 |
Server port |
HOST |
0.0.0.0 |
Bind address |
MAX_BATCH_SIZE |
1024 |
Max texts per batch |
MAX_TEXT_LENGTH |
8192 |
Max tokens per text |
LOG_LEVEL |
INFO |
Logging level |
MAX_LOADED_MODELS |
2 |
Max models in memory (reduce to 1 on 8GB machines) |
Requirements
- macOS with Apple Silicon (M1/M2/M3/M4)
- Python 3.10+
License
MIT
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file roocode_code_indexer_macos-0.1.2.tar.gz.
File metadata
- Download URL: roocode_code_indexer_macos-0.1.2.tar.gz
- Upload date:
- Size: 124.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
152eb08cdb1fe483daa8ad110837dffd996c983367b934b68b8dc17a0025a3dc
|
|
| MD5 |
a30997f99a97fb08d0d85cef8de0cc68
|
|
| BLAKE2b-256 |
4c1ddd936a0a122f451441195d62fbf523f84b6a6159200f9020d6a3c4431c83
|
Provenance
The following attestation bundles were made for roocode_code_indexer_macos-0.1.2.tar.gz:
Publisher:
publish.yml on dmarkey/roocode-code-indexer-macos
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
roocode_code_indexer_macos-0.1.2.tar.gz -
Subject digest:
152eb08cdb1fe483daa8ad110837dffd996c983367b934b68b8dc17a0025a3dc - Sigstore transparency entry: 1176583603
- Sigstore integration time:
-
Permalink:
dmarkey/roocode-code-indexer-macos@e114b3b436c734acae855d7f862755025d808e93 -
Branch / Tag:
refs/tags/v0.1.2 - Owner: https://github.com/dmarkey
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@e114b3b436c734acae855d7f862755025d808e93 -
Trigger Event:
release
-
Statement type:
File details
Details for the file roocode_code_indexer_macos-0.1.2-py3-none-any.whl.
File metadata
- Download URL: roocode_code_indexer_macos-0.1.2-py3-none-any.whl
- Upload date:
- Size: 14.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9ec3e6c820eeae6d097591668abc5c83bb18b61009c28325bc5312a64320bc5f
|
|
| MD5 |
3a2dc37d11c40d8b73a5307b28c144c0
|
|
| BLAKE2b-256 |
d3b3c524c9e9cc759e88cf7870ff9950e72a37ce52988072a780247a49464a28
|
Provenance
The following attestation bundles were made for roocode_code_indexer_macos-0.1.2-py3-none-any.whl:
Publisher:
publish.yml on dmarkey/roocode-code-indexer-macos
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
roocode_code_indexer_macos-0.1.2-py3-none-any.whl -
Subject digest:
9ec3e6c820eeae6d097591668abc5c83bb18b61009c28325bc5312a64320bc5f - Sigstore transparency entry: 1176583771
- Sigstore integration time:
-
Permalink:
dmarkey/roocode-code-indexer-macos@e114b3b436c734acae855d7f862755025d808e93 -
Branch / Tag:
refs/tags/v0.1.2 - Owner: https://github.com/dmarkey
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@e114b3b436c734acae855d7f862755025d808e93 -
Trigger Event:
release
-
Statement type:







