The Ultimate Agentic RAG Framework.

Project description




🧠 RostaingChain
The Ultimate Agentic RAG Framework.
Autonomous Agent | Local & Remote LLMs | Real-time Watcher | Deep Data Profiling | DLP Security | Multi-Modal
RostaingChain is a production-ready framework designed to build autonomous RAG (Retrieval-Augmented Generation) systems. It bridges the gap between local privacy (Ollama, Local Docs) and cloud power (OpenAI, Groq, Datastores), featuring a unique Live Watcher that updates your AI's knowledge in real-time and Agentic RAG with Self-Healing Data Analysis.
🚀 Key Features
- Hybrid Intelligence: Switch instantly between Local LLMs (Ollama, Llama.cpp) and Remote giants (OpenAI, Groq, Claude, Gemini, DeepSeek, Grok).
- Live Watcher (Auto-Sync): Drop a file in a folder, modify a SQL row, update a website, or update a file -> The AI learns it instantly.
- Deep Profiling (Anti-Hallucination): Automatically calculates descriptive statistics (Max, Min, Mean, etc.), performs rigorous statistical tests (Hypothesis testing, P-values, Correlations, etc.), and generates automated visualizations (Charts, Histograms, etc.). By grounding the LLM in real-time data analysis and anomaly detection for CSV/Excel/SQL/NoSQL/DataFrame/Parquet sources, it ensures the model never hallucinates numbers or trends.
- DLP Security: Built-in Redaction system to mask sensitive data (See the Security Filters & Data Masking list below) before display. Set to True for ALL filters, False to disable, or a list to select specific fields.
- Multi-Modal Native: Understands Text, PDFs (OCR included), Images, Audio (Whisper), and YouTube videos.
- Universal Sources: Connects to Local Files, PostgreSQL, MySQL, Oracle, Microsoft SQL Server, SQLite, MongoDB, Neo4j, and the Web.
🛠 Environment Setup
To ensure stability and avoid dependency conflicts, we strongly recommend using a virtual environment. RostaingChain requires Python 3.9 or higher.
Option 1: Using Python venv (Standard)
This is the built-in method. Choose the commands based on your Operating System:
On Windows:
# 1. Create the environment
python -m venv venv
# 2. Activate it
venv\Scripts\activate
On macOS / Linux:
# 1. Create the environment
python3 -m venv venv
# 2. Activate it
source venv/bin/activate
Option 2: Using Conda (Recommended for Data Science)
Conda is often more robust for managing complex dependencies like pyodbc or chromadb.
# 1. Create the environment with a specific Python version
conda create -n rostaing_env python=3.12 -y
# 2. Activate the environment
conda activate rostaing_env
📦 Installation:
Once your environment is activated, you can install the framework.
pip install rostaingchain
🔑 Managing API Keys (Remote LLMs)
To use remote LLMs (like OpenAI, Groq, Claude, Gemini, Grok, Mistral, DeepSeek) without hardcoding your credentials in the code, RostaingChain supports environment variables.
- Create a file named
.envin your project root. - Add your API keys following this format:
# Standard Providers
OPENAI_API_KEY=...
ANTHROPIC_API_KEY=...
GOOGLE_API_KEY=...
# Fast Inference Providers
GROQ_API_KEY=...
MISTRAL_API_KEY=...
# OpenAI-Compatible Providers
DEEPSEEK_API_KEY=...
XAI_API_KEY=...
- Load the keys at the start of your script using
python-dotenv:
pip install python-dotenv
⚡ Quick Start
1. The "Chat with Anything" Mode
Simply point data_source to a file, a folder, a database, or a URL.
from rostaingchain import RostaingAgent
# Initialize the Agent
agent = RostaingAgent(
llm_model="llama3.2", # Use local Ollama and ensure you ran 'ollama pull llama3.2' in your terminal
data_source="/path/to/data", # Watches this folder
auto_update=True # Real-time ingestion
)
# Chat
response = agent.chat("What are the main topics in these documents?")
print(response)
2. 🚀 Quick Start: Interactive Console Agent
import os
from dotenv import load_dotenv
from rostaingchain import RostaingAgent
# 1. Load environment variables (Make sure your .env file is set up)
load_dotenv()
def main():
# 2. Initialize the Agent
# RostaingAgent automatically handles data profiling, vector indexing, and memory.
agent = RostaingAgent(
llm_model="gpt-4o",
llm_provider="openai",
llm_api_key=os.getenv("OPENAI_API_KEY"),
data_source="data/products.xlsx", # Path to your CSV/SQL/Excel/Image/Audio/Video/...
vector_db="faiss", # High-performance vector storage
reset_db=False, # Set to True to re-index the data
memory=True # Keep track of the conversation context
)
print("\n" + "="*40)
print("🤖 RotaingChain AGENT: CONSOLE MODE")
print("Type your question below or 'q' to exit.")
print("="*40 + "\n")
try:
while True:
# 3. Capture User Input
user_input = input("👤 You: ").strip()
# Exit condition
if user_input.lower() in ["q", "quit", "exit"]:
print("\nShutting down... Goodbye! 👋")
break
if not user_input:
continue
# 4. Generate & Display Response
print("🤖 Agent:", end=" ", flush=True)
try:
response = agent.chat(user_input)
print(response)
except Exception as e:
print(f"\n❌ Error: {str(e)}")
except KeyboardInterrupt:
print("\n\n[System] Session interrupted by user. Closing... 👋")
finally:
print("Program closed.")
if __name__ == "__main__":
main()
🛠️ Advanced Usage
1. YouTube Video Analysis
Extract transcripts and metadata automatically.
from rostaingchain import RostaingAgent
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
agent = RostaingAgent(
llm_model="openai/gpt-oss-120b",
llm_provider="groq",
data_source="https://www.youtube.com/watch?v=3mTK0vYYXA4",
vector_db="faiss",
stream=True
)
# Streaming response for better UX
generator = agent.chat("Summarize this video in 3 bullet points.")
for token in generator:
print(token, end="", flush=True)
2. Data Security (DLP)
Protect sensitive information from being displayed.
from rostaingchain import RostaingAgent
agent = RostaingAgent(
llm_model="llama3.2",
data_source="bank_statements.pdf",
# Enable Security
security_filters=["IBAN", "BIC", "PHONE", "EMAIL", "MONEY", "CREDIT_CARD"] # Optional: DLP Security. Set to True for ALL filters, False to disable, or a list to select specific fields.
)
response = agent.chat("Give me the IBAN of the supplier.")
print(response)
# Output: "The IBAN is [Protected IBAN bank details]."
3. Working with DataFrames (Pandas)
import pandas as pd
from rostaingchain import RostaingAgent
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
df = pd.read_csv("titanic.csv")
# Direct Memory Ingestion
agent = RostaingAgent(
llm_model="gpt-4o",
data_source=df,
vector_db="chroma"
)
print(agent.chat("What is the average age of passengers?"))
4. Audio Analysis with Streaming & Markdown Output
RostaingChain natively handles audio files (like .m4a, .mp3) using OpenAI Whisper locally. This example demonstrates how to process an audio file, enforce security filters, and stream the result in a specific JSON format.
from rostaingchain import RostaingAgent
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Assuming your API key is set
llm_api_key = os.getenv("GROQ_API_KEY")
agent = RostaingAgent(
llm_model="openai/gpt-oss-120b",
llm_provider="groq",
llm_api_key=llm_api_key,
data_source="C:/Users/Rostaing/Desktop/data/audio.m4a", # Supports: .m4a, .mp3, .wav, .ogg, .flac, .webm
poll_interval=3600, # Check for file updates every hour
vector_db="faiss", # Options: 'faiss' or 'chroma'
reset_db=True, # Re-index the file on startup
memory=True, # Enable conversation history
security_filters=["PHONE", "BIC", "IBAN", "DATE"], # Optional: DLP Security. Set to True for ALL filters, False to disable, or a list to select specific fields.
stream=True,
output_format="markdown" # Options: "json", "text", "cartoon"
)
# Request a summary in JSON format with streaming enabled
response = agent.chat("Give me a summary.") # output_format supports: "json", "text (default)", "markdown", "toon"
# Real-time display loop
for token in response:
# Prints every token as soon as it arrives (ChatGPT-like effect)
print(token, end="", flush=True)
5. Chat with a Website (Web RAG)
from rostaingchain import RostaingAgent
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# Direct Memory Ingestion
agent = RostaingAgent(
llm_model="gpt-4o",
llm_provider="openai",
data_source="https://en.wikipedia.org/wiki/Artificial_intelligence",
vector_db="chroma", # Options: 'faiss' or 'chroma'
)
response = gent.chat("Give me a summary.")
print(response)
6. Chat with an image (RAG)
from rostaingchain import RostaingAgent
# Direct Memory Ingestion
agent = RostaingAgent(
llm_model="llama3.2", # Ensure you ran 'ollama pull llama3.2' in your terminal
llm_provider="ollama", # Runs 100% locally on your machine for privacy
embedding_model="nomic-embed-text", # Ensure you ran 'ollama pull nomic-embed-text' in your terminal
data_source="invoice.jpg", # Supports: .png, .jpeg, .bmp, .tiff, .webp
memory=True, # Enable conversation history
vector_db="chroma", # Options: 'faiss' or 'chroma'
)
response = gent.chat("Give me a summary.")
print(response)
7. Video Analysis with Streaming & Cartoon Output
from rostaingchain import RostaingAgent
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# Direct Memory Ingestion
agent = RostaingAgent(
llm_model="gpt-4o",
llm_provider="openai",
data_source="your_video.mp4", # Supports: .avi, .mov, .mkv, etc.
vector_db="chroma", # Options: 'faiss' or 'chroma'
stream=True,
output_format="cartoon" # Options: "json", "text", "cartoon"
)
response = gent.chat("Give me a summary.")
# Real-time display loop
for token in response:
# Prints every token as soon as it arrives (ChatGPT-like effect)
print(token, end="", flush=True)
8. Chat with a file (Streaming RAG)
from rostaingchain import RostaingAgent
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# Direct Memory Ingestion
agent = RostaingAgent(
llm_model="gpt-4o",
llm_provider="openai",
data_source="your_file.txt", # Supports: .pdf, .docx, .doc, .xlsx, .xls, .pptx, .ppt, .html, .htm, .xml, .epub, .md, .json, .log, .py, .js, .sql, .yaml, .ini, etc.
vector_db="chroma", # Options: 'faiss' or 'chroma'
stream=True
)
response = gent.chat("Give me a summary.")
# Real-time display loop
for token in response:
# Prints every token as soon as it arrives (ChatGPT-like effect)
print(token, end="", flush=True)
9. Connecting to Databases (SQL / NoSQL)
RostaingAgent uses a Polling Watcher to monitor database changes.
from rostaingchain import RostaingAgent
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# PostgreSQL Configuration
db_config = {
"type": "sql",
"connection_string": "postgresql+psycopg2://your_username:your_password@localhost:5432/your_database",
"query": "SELECT * FROM sales" # Your query
}
agent = RostaingAgent(
llm_model="gpt-4o",
llm_provider="openai",
data_source=db_config,
poll_interval=30, # Check for DB changes every 30 seconds
reset_db=False, # Start with a fresh index
vector_db="faiss"
)
print(agent.chat("What is the total revenue for Q1?"))
# Thanks to Deep Profiling, the AI will know the exact sum/mean/max.
10 🗄️ Database Configuration Examples
To connect RostaingAgent to a database, create a dictionary db_config and pass it to the data_source parameter.
1. SQL Databases (via SQLAlchemy)
PostgreSQL
pg_config = {
"type": "sql",
"connection_string": "postgresql+psycopg2://your_username:your_password@localhost:5432/your_database",
"query": "SELECT * FROM sales" # Your query
}
MySQL
mysql_config = {
"type": "sql",
"connection_string": "mysql+pymysql://my_username:your_password@localhost:3306/your_database",
"query": "SELECT * FROM orders WHERE status = 'shipped'" # Your query
}
Oracle
# Requires Oracle Instant Client installed
# Ensure you ran 'pip install cx-oracle' in your terminal
oracle_config = {
"type": "sql",
"connection_string": "oracle+cx_oracle://your_username:your_password@localhost:1521/?service_name=ORCL",
"query": "SELECT * FROM employees" # Your query
}
SQLite
sqlite_config = {
"type": "sql",
"connection_string": "sqlite:///C:/path/to/your_data.db",
"query": "SELECT * FROM invoices" # Your query
}
Microsoft SQL Server
# Option 1
mssql_config = {
"type": "sql",
"connection_string": "mssql+pymssql://your_username:your_password@localhost:1433/your_database",
"query": "SELECT top 100 * FROM customers" # Your query
}
# Option 2 (Recommended)
# We build a valid SQLAlchemy URL.
# We use quote_plus to handle special characters like \ in the server name.
host = r"your_host" # Example: DESKTOP-9K6BSF8\SQLEXPRESS
db_name = "your_database"
username = "your_username"
password = "your_password"
connection_string = f"mssql+pyodbc://{username}:{password}@{host}/{db_name}?driver=ODBC+Driver+17+for+SQL+Server&TrustServerCertificate=yes"
mssql_config = {
"type": "sql",
"connection_string": connection_string,
"query": "SELECT * FROM customers" # Your query
}
2. NoSQL Databases
MongoDB
mongo_config = {
"type": "mongodb",
"uri": "mongodb://localhost:27017/",
"db": "ecommerce_db",
"collection": "products",
"limit": 50 # Optional: Limit the number of documents to ingest
}
Neo4j (Graph)
neo4j_config = {
"type": "neo4j",
"uri": "bolt://localhost:7687",
"user": "neo4j",
"password": "your_password",
"query": "MATCH (p:Person)-[:WROTE]->(a:Article) RETURN p.name, a.title LIMIT 20" # Your query
}
Usage Example
agent = RostaingAgent(
llm_model="gpt-4o",
data_source=mysql_config, # Pass the dictionary here.
poll_interval=3600, # Watch for changes every minute
reset_db=False
)
11. Use a custom LLM (e.g., vLLM on another server)
from rostaingchain import RostaingAgent
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
# Direct Memory Ingestion
agent = RostaingAgent(
llm_model="my-finetuned-model",
llm_provider="custom",
llm_base_url="http://192.168.1.50:8000/v1", # Your vLLM server
llm_api_key="token-if-needed",
memory=True,
vector_db="chroma", # Options: 'faiss' or 'chroma'
data_source="/path/to/your_file.pdf", # Supports: .txt, .docx, .doc, .xlsx, .xls, .pptx, .ppt, .html, .htm, .xml, .epub, .md, .json, .log, .py, .js, .sql, .yaml, .ini, .jpg, .png, .jpeg, .bmp, .tiff, .webp, SQL/NoSQL Databases, Audio/Video/Web(link)
reset_db=True, # Start with a fresh index
temperature=0,
top_k=0.1,
top_p=1,
max_tokens=1500,
stream=True
)
response = gent.chat("Give me a summary.")
# Real-time display loop
for token in response:
# Prints every token as soon as it arrives (ChatGPT-like effect)
print(token, end="", flush=True)
12. Universal Intelligence: Switching LLM Providers
A. Use DeepSeek (the cheaper GPT-4 alternative)
agent = RostaingAgent(
llm_model="deepseek-chat", # Auto-detection
provider="deepseek",
# If the key is not in the .env:
llm_api_key="sk-your-deepseek-key"
)
B. Use Groq (Lightning speed – 500 tokens/s)
agent = RostaingAgent(
llm_model="openai/gpt-oss-120b",
llm_provider="groq" # Force the provider to ensure it
)
C. Use Claude Sonnet (Best for coding)
agent = RostaingAgent(
llm_model="claude-4.5-sonnet",
llm_provider="anthropic" # Force the provider to ensure it
)
D. Use Gemini 3 Pro (Google)
agent = RostaingAgent(
llm_model="gemini-3-pro-preview",
llm_provider="google" # Force the provider to ensure it
)
E. Use Mistral (via Groq for Speed)
agent = RostaingAgent(
llm_model="mistral-large-2512",
llm_provider="mistral" # Force the provider for ultra-fast inference
)
F. Use Grok (xAI)
agent = RostaingAgent(
llm_model="grok-4.1",
llm_provider="grok" # Automatically configures the xAI API base_url
)
G. Use OpenAI (GPT-4o)
agent = RostaingAgent(
llm_model="gpt-4o",
llm_provider="openai" # Automatically uses OPENAI_API_KEY from your .env file
)
H. Use Local LLMs (Ollama)
agent = RostaingAgent(
llm_model="llama3.2", # Ensure you ran 'ollama pull llama3.2' in your terminal
llm_provider="ollama", # Runs 100% locally on your machine for privacy
# llm_base_url="http://localhost:11434" # Optional: Default URL
)
📝 Key Parameters Explained
-
stream=True: This is essential for User Experience (UX). Instead of waiting for the entire response to be generated (which can take time for long summaries), the method returns a Python Generator. You must iterate over it (using aforloop) to display tokens in real-time, exactly like ChatGPT. -
output_format: This parameter enforces the structure or style of the LLM's response. It accepts three values:"text"(Default): A standard, conversational plain text response."json": Forces the LLM to output a valid JSON object. Extremely useful if you are building an API or need to parse the result programmatically."cartoon": Makes the LLM generate responses in a playful, cartoon-style tone with simplified language and expressive descriptions. Useful for educational content, storytelling, or kid-friendly interfaces.
-
vector_db: Defines the local vector storage engine. RostaingChain currently supports two robust, file-based options:"chroma": Uses ChromaDB."faiss": Uses Facebook AI Similarity Search (highly efficient for CPU).
⚙️ Configuration Parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
| RostaingAgent | |||
llm_model |
str | "llama3.2" |
Name of the model (e.g., "gpt-4o", "claude-3-opus", "mistral"). |
llm_provider |
str | "auto" |
"openai", "groq", "ollama", "anthropic", "google", "deepseek". |
llm_api_key |
str | None |
API Key (optional if environment variable is set). |
llm_base_url |
str | None |
Custom endpoint URL (for local setups or proxies). |
embedding_model |
str | "BAAI/bge-small-en-v1.5" |
Model used for vectorizing documents. |
embedding_source |
str | "fastembed" |
"fastembed", "openai", "ollama", "huggingface". |
vector_db |
str | "chroma" |
Vector Store backend: "chroma", "faiss" |
data_source |
str/dict/obj | "./data" |
File path, Folder path, Image path, URL, SQL Config (dict), or DataFrame object. |
| Automation | |||
auto_update |
bool | True |
Activates real-time Watcher (File system) or Polling (DB/Web). |
poll_interval |
int | 60 |
Interval in seconds between DB/Web checks. |
reset_db |
bool | False |
Wipes/Resets vector database storage on startup. |
memory |
bool | False |
Enables conversational history (Multi-turn chat). |
| Generation Settings | |||
temperature |
float | 0.1 |
Creativity of the model (0.0 = deterministic, 1.0 = creative). |
max_tokens |
int | None |
Limit response length. |
top_p |
float | None |
Nucleus sampling parameter. |
top_k |
int | None |
Top-K sampling parameter. |
seed |
int | None |
Seed for reproducible/deterministic outputs. |
stream |
bool | False |
Enables streaming response (token by token). |
cache |
bool | True |
Enables In-Memory caching for speed. |
output_format |
str | "text" |
Enforce format: "text", "json", "markdown", "cartoon". |
| Agent Identity | |||
role |
str | "Helpful AI Assistant" |
Defines the persona/role of the agent. |
goal |
str | "Assist the user..." |
The primary objective of the agent. |
instructions |
str | "Answer concisely." |
Specific behavioral instructions or constraints. |
reflection |
bool | False |
Enables "Step-by-step" thinking and self-correction before answering. |
| Company Context | |||
company_name |
str | None |
Name of the organization for business context. |
company_description |
str | None |
Description of the company's activity. |
company_url |
str | None |
Website URL for context. |
| Security & User | |||
security_filters |
list/bool | None |
List of DLP filters (e.g., ["IBAN", "EMAIL"]) or True for all. |
user_profile |
str | None |
Natural language description of user rights (e.g., "Intern, no access to salaries"). |
user_id |
str | None |
Unique identifier for the user. |
session_id |
str | None |
Unique identifier for the chat session. |
agent_id |
str | None |
Unique identifier for the specific agent instance. |
system_prompt |
str | None |
Full override of the system prompt (Advanced). |
| Tools & UI | |||
mcp_tools |
list | None |
List of Model Context Protocol tools for external integrations. |
canvas |
object | None |
Canvas UI instance for visual updates (Charts/Graphs). |
🔒 Security Filters & Data Masking
| Data type | Alternative text |
|---|---|
[Email masked] |
|
| PHONE | [Phone masked] |
| ID_NUM | [ID masked] |
| PASSPORT | [Passport masked] |
| SSN | [SSN masked] |
| ADDRESS | [Address masked] |
| POSTAL | [Postal Code masked] |
| BIC | [BIC masked] |
| IBAN | [IBAN masked] |
| VAT_ID | [VAT masked] |
| CREDIT_CARD | [Card masked] |
| MONEY | [Amount masked] |
| CRYPTO | [Crypto masked] |
| IP_ADDR | [IP masked] |
| MAC_ADDR | [MAC masked] |
| API_KEY | [API Key redacted] |
| DATE | [Date masked] |
| SALARY | [Salary information confidential] |
| BIRTHDATE | [Birth date masked] |
| MEDICAL | [Medical information confidential] |
💡 Pro Tip: VSCode Autocomplete
Don't memorize the parameters! If you are using VSCode, you can view the complete list of available options for RostaingAgent instantly.
Just place your cursor inside the parentheses and press:
Ctrl + Space
This will trigger IntelliSense and display all configuration arguments (like memory, security_filters, temperature, cache, etc.) with their descriptions.
🏗️ Architecture
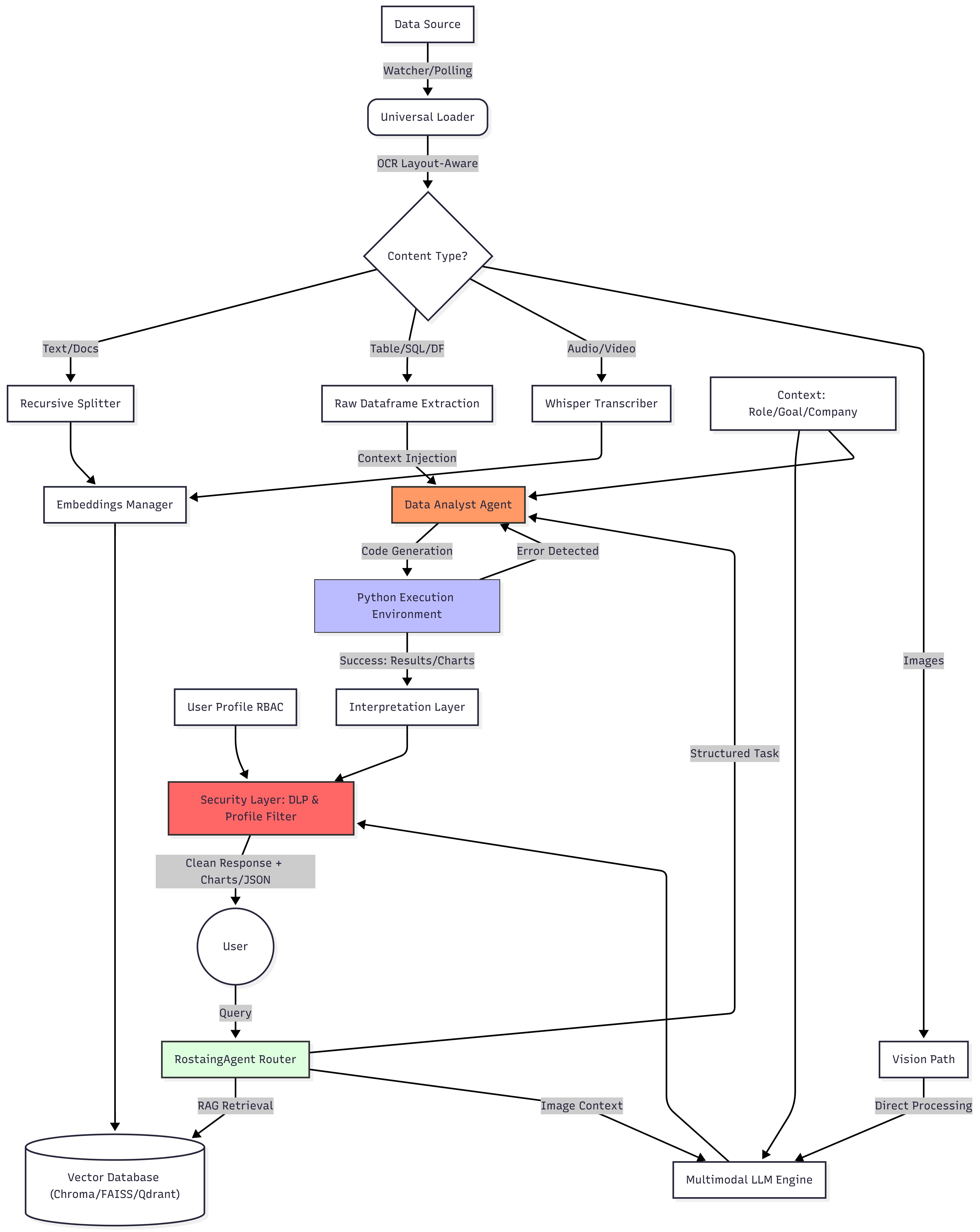
Useful Links
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file rostaingchain-1.1.0.tar.gz.
File metadata
- Download URL: rostaingchain-1.1.0.tar.gz
- Upload date:
- Size: 113.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
616a25c6b903070b3c522af1cd84e8750219e1e0604e47ebbf96235c72b591f6
|
|
| MD5 |
e9d84b5e36ef9dfa46d44e43f45e3860
|
|
| BLAKE2b-256 |
a07b67dc72bf03bccdc41e19736935a0107710687e24d620a05029aaf8ab7d56
|
File details
Details for the file rostaingchain-1.1.0-py3-none-any.whl.
File metadata
- Download URL: rostaingchain-1.1.0-py3-none-any.whl
- Upload date:
- Size: 128.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
be0d4602cb11f2e8f49d13d53f356c3dacc80c6c11ac50199e49214c405356dc
|
|
| MD5 |
0490c7560c5e5d5e88429d2eed444af9
|
|
| BLAKE2b-256 |
a0d625f09624c977ee69bd1f68a5007d17e520fab03ee2fa651447bf2600aa88
|







