Fast extraction of access summary data from S3 logs.
Project description

S3 Log Extraction








Fast extraction of access summary data from S3 logs.
Originally developed for the DANDI Archive.
Read more about S3 logging on AWS.
⚠️ This package currently only supports processing of access data (GET-type requests); if you wish to use this package for other types of requests (PUT/DELETE/HEAD, etc.) please reach out by raising an issue. ⚠️
Installation
pip install s3-log-extraction
Note for Windows users: This package requires GAWK and is not natively supported on Windows. Windows users should use Windows Subsystem for Linux (WSL) to run this package.
Workflow
flowchart TD
A[Configure cache<br/><br/>Initialize home and cache directories]
B[Extract logs<br/><br/>Process raw S3 logs and store minimal extracted data]
C[Update IP indexes<br/><br/>Generate anonymized indexes for each IP address]
D[Update region codes<br/><br/>Map IPs to ISO 3166 region codes using external API]
E[Update coordinates<br/><br/>Convert region codes to latitude/longitude for mapping]
F[Generate summaries<br/><br/>Create per-dataset summaries for reporting]
G[Generate totals<br/><br/>Aggregate statistics across datasets or archive]
H[Share!<br/><br/>Post the summaries and totals in a public data repository]
A --> B
B --> C
C --> D
D --> E
E --> F
F --> G
G --> H
Generic Usage
[Optional] Configure a non-default cache directory on a mounted disk that has sufficient space (the default is placed under ~/.cache). This will be the main location where extracted logs and other useful information will be stored.
s3logextraction config cache set <new cache directory>
To extract the logs:
s3logextraction extract <log directory>
To override the cache directory for a single extraction run (without changing global config):
s3logextraction extract <log directory> --cache <cache directory>
NOTE: If you feel like this command is taking a long time on your system, DO NOT interrupt it via ctrl+C or pkill. Instead, you can safely interrupt it by running:
s3logextraction stop
This will allow it to finish processing the current batch of logs and then exit gracefully.
After your logs are extracted, generate anonymized indexes for each IP address:
s3logextraction update ip indexes
Next, ensure some required environment variables related to external services are set:
- IPINFO_API_KEY
- Access token for the ipinfo.io service.
- Extracts geographic region information in ISO 3166 format (e.g. "US/California") for anonymized statistics.
- OPENCAGE_API_KEY
- Access token for the opencagedata.com service.
- Maps the ISO 3166 codes from the first step to latitude and longitude coordinates for the geographic heat maps used in visualizations.
export IPINFO_API_KEY="your_token_here"
export OPENCAGE_API_KEY="your_token_here"
To update the region codes and their coordinates:
s3logextraction update ip regions
s3logextraction update ip coordinates
To generate top-level summaries and totals (that is, per dataset):
s3logextraction update summaries
s3logextraction update totals
Finally, to generate archive-wide summaries and totals:
s3logextraction update summaries --mode archive
s3logextraction update totals --mode archive
How to Setup Logging
If you're new to using AWS S3 buckets and haven't yet enabled the logging this project utilizes, you can follow these simple instructions to get started.
- Log into your AWS console.
- Create a new PRIVATE S3 bucket - typically the name of the new bucket is the name of the one you wish to enable logging on with
-logsadded to the end. For example,dandiarchive-logs.- NEVER share this bucket publicly as it contains sensitive information.
- Navigate back to the S3 bucket you wish to enable logging on.
- Under the
Propertiestab, scroll down to the section calledServer access loggingand selectEdit. - Toggle the selection to
Enable, then specify the destination where logs will be stored as the new S3 bucket you created in step (2). - Recommended:
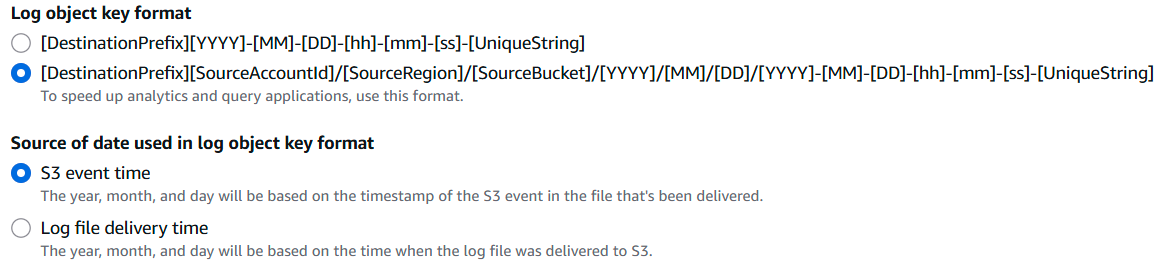
- Specify the
Log object key formatas the nested pattern shown below. - Ensure the
Source of date used in log object key formatis theS3 event time.
- Specify the
Developer Notes
Throughout the codebase, various processes are referred to in the following ways:
- parallelized: The process can be run in parallel across multiple workers, which increases throughput.
- interruptible: The process can be safely interrupted (
ctrl+Corpkill) with only a very low chance of causing corruption. For parallelized interruption you may have to eitherpkillthe main dispatch process or spamctrl+Cmultiple times. - updatable: The process can be resumed from the last checkpoint without losing any progress. It can also be run fresh at different times, such as on a CRON cycle, and it will only interact with unprocessed data.
Performance
By leveraging GAWK, this version of the S3 log handling is considerably more efficient than the previous attempts.
The previous attempt used a multistep process which took several days to run (even on multiple workers). It also required an additional ~200 GB cache to allow lazy updates of the per-object bins.
This version requires no intermediate cache, stores only the minimal amount of data to be shared, and takes less than a day to do a fresh run (and is also lazy regarding daily CRON updates).
Validation
In lieu of attempting fully validated parsing of each and every line from the log files (which is a hard, unsolved problem - see s3-log-parser), we instead validate the heuristics in a targeted manner through specific validation scripts.
These can also be used to verify the current state of the extraction process, such as warning about corrupt records or incomplete cache files.
Submission of line decoding errors
Should you discover any lines in your S3 log files that cause failures in the codebase, please email them to the core maintainer (cody.c.baker.phd@gmail.com) before raising issues or submitting PRs contributing them as examples, to more easily correct any aspects that might require anonymization.
Project details


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file s3_log_extraction-1.9.2.tar.gz.
File metadata
- Download URL: s3_log_extraction-1.9.2.tar.gz
- Upload date:
- Size: 70.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
de92dfc72ddc2dcfc562215224fc23893ed79fa392737ebf9518edb8fc11b189
|
|
| MD5 |
4c94a6223ebe66e0ae7c33dc6cc601c1
|
|
| BLAKE2b-256 |
ba0f2aa1cef99d096a5fb917ffd50ab44af304c750386fad2707f4e16fac0965
|
File details
Details for the file s3_log_extraction-1.9.2-py3-none-any.whl.
File metadata
- Download URL: s3_log_extraction-1.9.2-py3-none-any.whl
- Upload date:
- Size: 66.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
dc9ca92a47b9d52bcea7cda81934f6b1b29e24ce2dabb0d3589ca15364867a68
|
|
| MD5 |
4126352919d4b7d021562418006322aa
|
|
| BLAKE2b-256 |
f09b40fc7c1ea6a966e7d49b7a107baae4905dd44412eecc9fb30aa37145231b
|







