Reverse Engineering of Supervised Semantic Speech Tokenizer (S3Tokenizer) proposed in CosyVoice

Project description
Reverse Engineering of S3Tokenizer
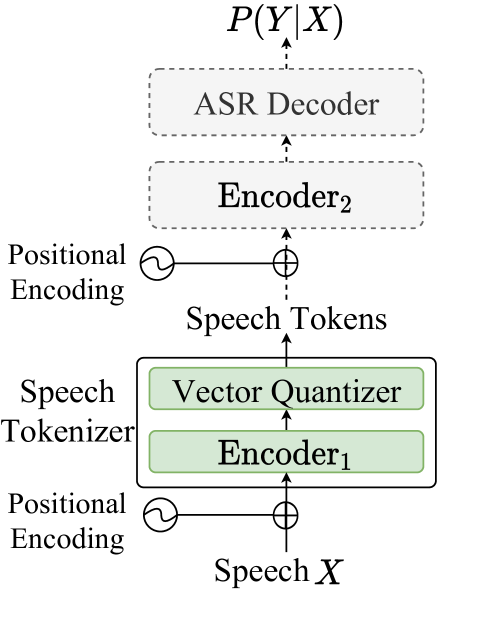
Supervised Semantic Speech Tokenizer (S3Tokenizer)
S3Tokenizer was initially introduced in CosyVoice [Paper] [Repo], it is a Supervised Semantic Speech Tokenizer based on the pre-trained SenseVoice-Large model, which enhances the semantic relationship of extracted tokens to textual and paralinguistic information, is robust to data noise, and reduces the reliance on clean data collection, thereby enabling the use of a broader range of data for model training.
However, as indicated in this [issue], the authors have no intention to open-source the PyTorch implementation of the S3Tokenizer, and only plan to release an ONNX file. Additionally, users aiming to fine-tune CosyVoice must extract speech codes offline, with the batch size restricted to 1, a process that is notably time-consuming (refer to [cosyvoice/tools/extract_speech_token.py]).
This repository undertakes a reverse engineering of the S3Tokenizer, offering:
- A pure PyTorch implementation of S3Tokenizer (see [model.py]), compatible with initializing weights from the released ONNX file (see [utils.py::onnx2torch()]).
- High-throughput (distributed) batch inference, achieving a ~790x speedup compared to the original inference pipeline in [cosyvoice/tools/extract_speech_token.py].
- The capability to perform online speech code extraction during SpeechLLM training.
Latest News 🎉
- [2025/07/07] S3Tokenizer now has built-in long audio processing capabilities, requiring no additional operations from users!
Supported Models 🔥
- Model: S3Tokenizer V1 50hz
- Model: S3Tokenizer V1 25hz
- Model: S3Tokenizer V2 25hz
- Model: S3Tokenizer V3 25hz
Setup
pip install s3tokenizer
Usage-1: Offline batch inference
import s3tokenizer
tokenizer = s3tokenizer.load_model("speech_tokenizer_v1").cuda() # or "speech_tokenizer_v1_25hz speech_tokenizer_v2_25hz speech_tokenizer_v3_25hz"
mels = []
wav_paths = ["s3tokenizer/assets/BAC009S0764W0121.wav", "s3tokenizer/assets/BAC009S0764W0122.wav"]
for wav_path in wav_paths:
audio = s3tokenizer.load_audio(wav_path)
mels.append(s3tokenizer.log_mel_spectrogram(audio))
mels, mels_lens = s3tokenizer.padding(mels)
codes, codes_lens = tokenizer.quantize(mels.cuda(), mels_lens.cuda()) # Automatically handles long audio internally!
for i in range(len(wav_paths)):
print(codes[i, :codes_lens[i].item()])
Usage-2: Distributed offline batch inference via command-line tools
2.1 CPU batch inference
s3tokenizer --wav_scp xxx.scp \
--device "cpu" \
--output_dir "./" \
--batch_size 32 \
--model "speech_tokenizer_v1" # or "speech_tokenizer_v1_25hz speech_tokenizer_v2_25hz speech_tokenizer_v3_25hz"
https://github.com/user-attachments/assets/d37d10fd-0e13-46a3-86b0-4cbec309086f
2.2 (Multi) GPU batch inference (a.k.a Distributed inference)
torchrun --nproc_per_node=8 --nnodes=1 \
--rdzv_id=2024 --rdzv_backend="c10d" --rdzv_endpoint="localhost:0" \
`which s3tokenizer` --wav_scp xxx.scp \
--device "cuda" \
--output_dir "./" \
--batch_size 32 \
--model "speech_tokenizer_v1" # or "speech_tokenizer_v1_25hz speech_tokenizer_v2_25hz speech_tokenizer_v3_25hz"
https://github.com/user-attachments/assets/79a3fb11-7199-4ee2-8a35-9682a3b4d94a
2.3 Performance Benchmark
| Method | Time cost on Aishell Test Set | Relative speed up | Miss Rate |
|---|---|---|---|
| [cosyvoice/tools/extract_speech_token.py], cpu | 9 hours | ~ | ~ |
| cpu, batchsize 32 | 1.5h | ~6x | 0.00% |
| 4 gpus (3090), batchsize 32 per gpu | 41s | ~790x | 0.00% |
The miss rate represents the proportion of tokens that are inconsistent between the batch inference predictions and the ONNX (batch=1) inference predictions.
Usage-3: Online speech code extraction
| Before (extract code offline) | After (extract code online) |
|---|---|
class SpeechLLM(nn.Module):
...
def __init__(self, ...):
...
def forward(self, speech_codes: Tensor, text_ids: Tensor, ...):
...
|
import s3tokenizer
class SpeechLLM(nn.Module):
...
def __init__(self, ...):
...
self.speech_tokenizer = s3tokenizer.load_model("speech_tokenizer_v1") # or "speech_tokenizer_v1_25hz"
self.speech_tokenizer.freeze()
def forward(self, speech: Tensor, speech_lens: Tensor, text_ids: Tensor, ...):
...
speech_codes, speech_codes_lens = self.speech_tokenizer.quantize(speech, speech_lens)
speech_codes = speech_codes.clone() # for backward compatbility
speech_codes_lens = speeech_codes_lens.clone() # for backward compatbility
|
Usage-4: Long Audio Processing (Built-in Automatic Processing)
- Automatic Detection: Model automatically detects audio length (>30 seconds triggers long audio processing)
- Sliding Window: 30-second window with 4-second overlap, automatically segments long audio
- Batch Processing: Internal batch processing of multiple segments for improved efficiency
- Complete Transparency: User calling method is identical to short audio
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file s3tokenizer-0.3.0.tar.gz.
File metadata
- Download URL: s3tokenizer-0.3.0.tar.gz
- Upload date:
- Size: 227.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.8.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
786a5ff8b5ca023507e0a6a8c7793a6aa1b1550a73d7676851d1b8c8b12889c5
|
|
| MD5 |
2012883f59713dd973ef3b7997ef2d97
|
|
| BLAKE2b-256 |
944ee64bb980309a22d186efedcd9e5f060a5b1cbffc5c19b356bb42dcc82e07
|
File details
Details for the file s3tokenizer-0.3.0-py3-none-any.whl.
File metadata
- Download URL: s3tokenizer-0.3.0-py3-none-any.whl
- Upload date:
- Size: 226.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.8.18
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c9e93b1892a124a2c4d958ab53610a1b4433fcb4172056e2f2bd3c09cfe249a6
|
|
| MD5 |
b63a301843ff31cc22af2ad6256935ef
|
|
| BLAKE2b-256 |
6b8fceddf749baf17405e755643e4d33c7c85bbb609a0c8cf43fc12aaea1c7ab
|







