Using XGboost and Sentence-Transformers to perform schema matching task on tables.

Project description

Python Schema Matching by XGboost and Sentence-Transformers
A python tool using XGboost and sentence-transformers to perform schema matching task on tables. Support multi-language column names and instances matching and can be used without column names. Both csv and json file type are supported.
What is schema matching?
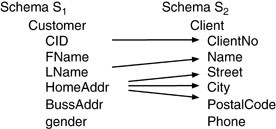
Schema matching is the problem of finding potential associations between elements (most often attributes or relations) of two schemas. source
Dependencies
- numpy==1.19.5
- pandas==1.1.5
- nltk==3.6.5
- python-dateutil==2.8.2
- sentence-transformers==2.1.0
- xgboost==1.5.2
- strsimpy==0.2.1
Package usage
Install
pip install schema-matching
Conduct schema matching
from schema_matching import schema_matching
df_pred,df_pred_labels,predicted_pairs = schema_matching("Test Data/QA/Table1.json","Test Data/QA/Table2.json")
print(df_pred)
print(df_pred_labels)
for pair_tuple in predicted_pairs:
print(pair_tuple)
Return:
- df_pred: Predict value matrix, pd.DataFrame.
- df_pred_labels: Predict label matrix, pd.DataFrame.
- predicted_pairs: Predict label == 1 column pairs, in tuple format.
Parameters:
- table1_pth: Path to your first csv, json or jsonl file.
- table2_pth: Path to your second csv, json or jsonl file.
- threshold: Threshold, you can use this parameter to specify threshold value, suggest 0.9 for easy matching(column name very similar). Default value is calculated from training data, which is around 0.15-0.2. This value is used for difficult matching(column name masked or very different).
- strategy: Strategy, there are three options: "one-to-one", "one-to-many" and "many-to-many". "one-to-one" means that one column can only be matched to one column. "one-to-many" means that columns in Table1 can only be matched to one column in Table2. "many-to-many" means that there is no restrictions. Default is "many-to-many".
- model_pth: Path to trained model folder, which must contain at least one pair of ".model" file and ".threshold" file. You don't need to specify this parameter.
Raw code usage: Training
Data
See Data format in Training Data and Test Data folders. You need to put mapping.txt, Table1.csv and Table2.csv in new folders under Training Data. For Test Data, mapping.txt is not needed.
1.Construct features
python relation_features.py
2.Train xgboost models
python train.py
3.Calculate similarity matrix (inference)
Example:
python cal_column_similarity.py -p Test\ Data/self -m /model/2022-04-12-12-06-32 -s one-to-one
python cal_column_similarity.py -p Test\ Data/authors -m /model/2022-04-12-12-06-32-11 -t 0.9
Parameters:
- -p: Path to test data folder, must contain "Table1.csv" and "Table2.csv" or "Table1.json" and "Table2.json".
- -m: Path to trained model folder, which must contain at least one pair of ".model" file and ".threshold" file.
- -t: Threshold, you can use this parameter to specify threshold value, suggest 0.9 for easy matching(column name very similar). Default value is calculated from training data, which is around 0.15-0.2. This value is used for difficult matching(column name masked or very different).
- -s: Strategy, there are three options: "one-to-one", "one-to-many" and "many-to-many". "one-to-one" means that one column can only be matched to one column. "one-to-many" means that columns in Table1 can only be matched to one column in Table2. "many-to-many" means that there is no restrictions. Default is "many-to-many".
Output:
- similarity_matrix_label.csv: Labels(0,1) for each column pairs.
- similarity_matrix_value.csv: Average of raw values computed by all the xgboost models.
Feature Engineering
Features: "is_url","is_numeric","is_date","is_string","numeric:mean", "numeric:min", "numeric:max", "numeric:variance","numeric:cv", "numeric:unique/len(data_list)", "length:mean", "length:min", "length:max", "length:variance","length:cv", "length:unique/len(data_list)", "whitespace_ratios:mean","punctuation_ratios:mean","special_character_ratios:mean","numeric_ratios:mean", "whitespace_ratios:cv","punctuation_ratios:cv","special_character_ratios:cv","numeric_ratios:cv", "colname:bleu_score", "colname:edit_distance","colname:lcs","colname:tsm_cosine", "colname:one_in_one", "instance_similarity:cosine"
- tsm_cosine: Cosine similarity of column names computed by sentence-transformers using "paraphrase-multilingual-mpnet-base-v2". Support multi-language column names matching.
- instance_similarity:cosine: Select 20 instances each string column and compute its mean embedding using sentence-transformers. Cosine similarity is computed by each pairs.
Performance
Cross Validation on Training Data(Each pair to be used as test data)
- Average Precision: 0.755
- Average Recall: 0.829
- Average F1: 0.766
Average Confusion Matrix:
| Negative(Truth) | Positive(Truth) | |
|---|---|---|
| Negative(pred) | 0.94343111 | 0.05656889 |
| Positive(pred) | 0.17135417 | 0.82864583 |
Inference on Test Data (Give confusing column names)
Data: https://github.com/fireindark707/Schema_Matching_XGboost/tree/main/Test%20Data/self
| title | text | summary | keywords | url | country | language | domain | name | timestamp | |
|---|---|---|---|---|---|---|---|---|---|---|
| col1 | 1(FN) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| col2 | 0 | 1(TP) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| col3 | 0 | 0 | 1(TP) | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| words | 0 | 0 | 0 | 1(TP) | 0 | 0 | 0 | 0 | 0 | 0 |
| link | 0 | 0 | 0 | 0 | 1(TP) | 0 | 0 | 0 | 0 | 0 |
| col6 | 0 | 0 | 0 | 0 | 0 | 1(TP) | 0 | 0 | 0 | 0 |
| lang | 0 | 0 | 0 | 0 | 0 | 0 | 1(TP) | 0 | 0 | 0 |
| col8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1(TP) | 0 | 0 |
| website | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0(FN) | 0 |
| col10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1(TP) |
F1 score: 0.889
Cite
@software{fireinfark707_Schema_Matching_by_2022,
author = {fireinfark707},
license = {MIT},
month = {4},
title = {{Schema Matching by XGboost}},
url = {https://github.com/fireindark707/Schema_Matching_XGboost},
year = {2022}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file schema_matching-1.0.4.tar.gz.
File metadata
- Download URL: schema_matching-1.0.4.tar.gz
- Upload date:
- Size: 877.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.2 readme-renderer/34.0 requests/2.27.1 requests-toolbelt/0.9.1 urllib3/1.26.7 tqdm/4.62.3 importlib-metadata/4.8.2 keyring/23.4.1 rfc3986/1.5.0 colorama/0.4.4 CPython/3.6.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ff4c8ca9f580ad856e6a0074dffa195fa0b862a4a640f702c2434d44460bcd6a
|
|
| MD5 |
5b20b970bf7e3b16e252e27384ecb654
|
|
| BLAKE2b-256 |
4852f5e3e1b4597005bf8c0db94d320750b1eb4940ccd9eeefe2faa52f27edc6
|
File details
Details for the file schema_matching-1.0.4-py3-none-any.whl.
File metadata
- Download URL: schema_matching-1.0.4-py3-none-any.whl
- Upload date:
- Size: 890.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.8.0 pkginfo/1.8.2 readme-renderer/34.0 requests/2.27.1 requests-toolbelt/0.9.1 urllib3/1.26.7 tqdm/4.62.3 importlib-metadata/4.8.2 keyring/23.4.1 rfc3986/1.5.0 colorama/0.4.4 CPython/3.6.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9a11e35dc7ba9c9d6238c99d5ef84c36d6597c0eac3a67684481b08474abc4e1
|
|
| MD5 |
579de05adb6a616c693989f260077d13
|
|
| BLAKE2b-256 |
6c59b02082044ce891664fb43cd58a386272ac4f9630ad392693eaceaf64c082
|







