Natural language database schema search with graph-aware semantic retrieval


Project description
Schema Search
An MCP Server for Natural Language Search over RDBMS Schemas. Find exact tables you need, with all their relationships mapped out, in milliseconds. No vector database setup is required.
Why
You have 200 tables in your database. Someone asks "where are user refunds stored?"
You could:
- Grep through SQL files for 20 minutes
- Pass the full schema to an LLM and watch it struggle with 200 tables
Or build schematic embeddings of your tables, store in-memory, and query in natural language in an MCP server.
Benefits
- No vector database setup is required
- Small memory footprint -- easily scales up to 1000 tables and 10,000+ columns.
- Millisecond query latency
Install
Fast by default - Base install uses only BM25/fuzzy search (no PyTorch):
# Minimal install (BM25 + fuzzy only, ~10MB)
pip install "schema-search[postgres]"
# With semantic/hybrid search support (~500MB with PyTorch)
pip install "schema-search[postgres,semantic]"
# With LLM chunking
pip install "schema-search[postgres,semantic,llm]"
# With MCP server
pip install "schema-search[postgres,semantic,mcp]"
# Other databases
pip install "schema-search[mysql,semantic]" # MySQL
pip install "schema-search[snowflake,semantic]" # Snowflake
pip install "schema-search[bigquery,semantic]" # BigQuery
pip install "schema-search[databricks,semantic]" # Databricks
Extras:
[semantic]: Enables semantic/hybrid search and CrossEncoder reranking (adds sentence-transformers)[llm]: Enables LLM-based schema chunking (adds openai)[mcp]: MCP server support (adds fastmcp)
Configuration
Edit config.yml:
logging:
level: "WARNING"
embedding:
location: "memory" # Options: "memory", "vectordb" (coming soon)
model: "multi-qa-MiniLM-L6-cos-v1"
metric: "cosine" # Options: "cosine", "euclidean", "manhattan", "dot"
batch_size: 32
show_progress: false
cache_dir: "/tmp/.schema_search_cache"
chunking:
strategy: "raw" # Options: "raw", "llm"
max_tokens: 256
overlap_tokens: 50
model: "gpt-4o-mini"
search:
# Search strategy: "semantic" (embeddings), "bm25" (BM25 lexical), "fuzzy" (fuzzy string matching), "hybrid" (semantic + bm25)
strategy: "bm25"
initial_top_k: 20
rerank_top_k: 5
semantic_weight: 0.67 # For hybrid search (bm25_weight = 1 - semantic_weight)
hops: 1 # Number of foreign key hops for graph expansion (0-2 recommended)
reranker:
# CrossEncoder model for reranking. Set to null to disable reranking
model: null # "Alibaba-NLP/gte-reranker-modernbert-base"
schema:
include_columns: true
include_indices: true
include_foreign_keys: true
include_constraints: true
MCP Server
Integrate with Claude Desktop or any MCP client.
Setup
Add to your MCP config (e.g., ~/.cursor/mcp.json or Claude Desktop config):
Using uv (Recommended):
{
"mcpServers": {
"schema-search": {
"command": "uvx",
"args": [
"schema-search[postgres,mcp]",
"postgresql://user:pass@localhost/db",
"optional/path/to/config.yml",
"optional llm_api_key",
"optional llm_base_url"
]
}
}
}
Using pip:
{
"mcpServers": {
"schema-search": {
// conda: /Users/<username>/opt/miniconda3/envs/<your env>/bin/schema-search",
"command": "path/to/schema-search",
"args": [
"postgresql://user:pass@localhost/db",
"optional/path/to/config.yml",
"optional llm_api_key",
"optional llm_base_url"
]
}
}
}
The LLM API key and base url are only required if you use LLM-generated schema summaries (config.chunking.strategy = 'llm').
CLI Usage
schema-search "postgresql://user:pass@localhost/db" "optional/path/to/config.yml"
Optional args: [config_path] [llm_api_key] [llm_base_url]
The server exposes schema_search(query, hops, limit) for natural language schema queries.
Python Use
from sqlalchemy import create_engine
from schema_search import SchemaSearch
# PostgreSQL
engine = create_engine("postgresql://user:pass@localhost/db")
# Databricks
# engine = create_engine(f"databricks://token:{token}@{host}:443/{catalog}?http_path={http_path}")
sc = SchemaSearch(
engine=engine,
config_path="optional/path/to/config.yml", # default: config.yml
llm_api_key="optional llm api key",
llm_base_url="optional llm base url"
)
sc.index(force=False) # default is False
results = sc.search("where are user refunds stored?")
for result in results['results']:
print(result['table']) # "refund_transactions"
print(result['schema']) # Full column info, types, constraints
print(result['related_tables']) # ["users", "payments", "transactions"]
# Override hops, limit, search strategy
results = sc.search("user_table", hops=1, limit=5, search_type="hybrid")
sc.index() automatically detects schema changes and refreshes cached metadata, so you rarely need to force a reindex manually.
Search Strategies
Schema Search supports four search strategies:
- bm25: Lexical search using BM25 ranking algorithm (no ML dependencies)
- fuzzy: String matching on table/column names using fuzzy matching (no ML dependencies)
- semantic: Embedding-based similarity search using sentence transformers (requires
[semantic]) - hybrid: Combines semantic and bm25 scores (default: 67% semantic, 33% bm25) (requires
[semantic])
Each strategy performs its own initial ranking, then optionally applies CrossEncoder reranking if reranker.model is configured (requires [semantic]). Set reranker.model to null to disable reranking.
Performance Comparison
We benchmarked on the Spider dataset (1,234 train queries across 18 databases) using the default config.yml.
Memory: The embedding model requires ~90 MB and the optional reranker adds ~155 MB. Actual process memory depends on your Python runtime.
Without Reranker (reranker.model: null)
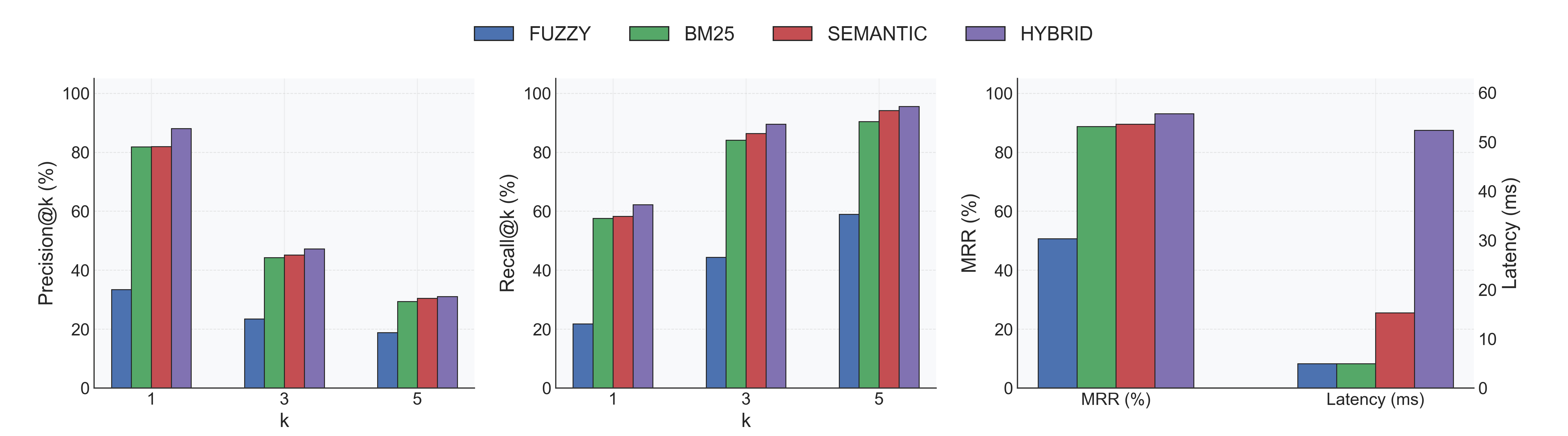
- Indexing: 0.22s ± 0.08s per database (18 total).
- Accuracy: Hybrid leads with Recall@1 62% / MRR 0.93; Semantic follows at Recall@1 58% / MRR 0.89.
- Latency: BM25 and Fuzzy return in ~5ms; Semantic spends ~15ms; Hybrid (semantic + fuzzy) averages 52ms.
- Fuzzy baseline: Recall@1 22%, highlighting the need for semantic signals on natural-language queries.
With Reranker (Alibaba-NLP/gte-reranker-modernbert-base)
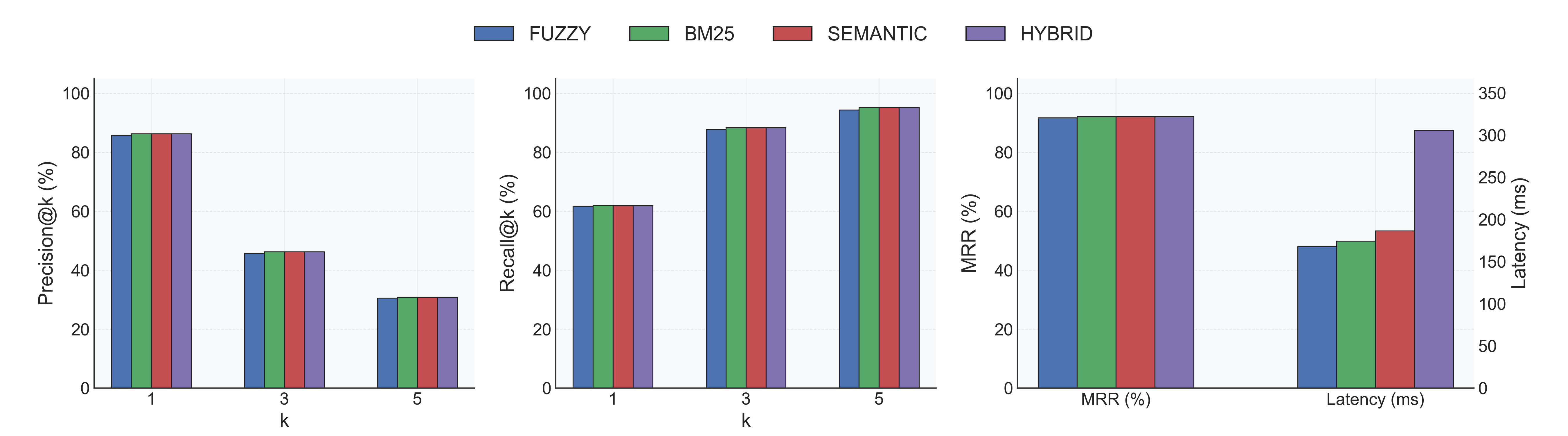
- Indexing: 0.25s ± 0.05s per database (same 18 DBs).
- Accuracy: All strategies converge around Recall@1 62% and MRR ≈ 0.92; Fuzzy jumps from 51% → 92% MRR.
- Latency trade-off: Extra CrossEncoder pass lifts per-query latency to ~0.18–0.29s depending on strategy.
- Recommendation: Enable the reranker when accuracy matters most; disable it for ultra-low-latency lookups.
You can override the search strategy, hops, and limit at query time:
# Use fuzzy search instead of default
results = sc.search("user_table", search_type="fuzzy")
# Use BM25 for keyword-based search
results = sc.search("transactions payments", search_type="bm25")
# Use hybrid for best of both worlds
results = sc.search("where are user refunds?", search_type="hybrid")
# Override hops and limit
results = sc.search("user refunds", hops=2, limit=10) # Expand 2 hops, return 10 tables
# Disable graph expansion
results = sc.search("user_table", hops=0) # Only direct matches, no foreign key traversal
LLM Chunking
Use LLM to generate semantic summaries instead of raw schema text (requires [llm] extra):
- Install:
pip install "schema-search[postgres,llm]" - Set
strategy: "llm"inconfig.yml - Pass API credentials:
sc = SchemaSearch(
engine,
llm_api_key="sk-...",
llm_base_url="https://api.openai.com/v1/" # optional
)
How It Works
- Extract schemas from database using SQLAlchemy inspector
- Chunk schemas into digestible pieces (markdown or LLM-generated summaries)
- Initial search using selected strategy (semantic/BM25/fuzzy)
- Expand via foreign keys to find related tables (configurable hops)
- Optional reranking with CrossEncoder to refine results
- Return top tables with full schema and relationships
Cache stored in /tmp/.schema_search_cache/ (configurable in config.yml)
License
MIT
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file schema_search-1.0.11.tar.gz.
File metadata
- Download URL: schema_search-1.0.11.tar.gz
- Upload date:
- Size: 33.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f4d057a276ca80d6777b7278094ff23b5bb983527c6e0982e94146c2dd4a3890
|
|
| MD5 |
25f88f600cfe4bd5a21490ffa0858f37
|
|
| BLAKE2b-256 |
dbcb635fc4a34cd6e6900eb6ef216fa9f731c9e53524e68df88c1caf988e778d
|
Provenance
The following attestation bundles were made for schema_search-1.0.11.tar.gz:
Publisher:
publish.yml on Neehan/schema-search
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
schema_search-1.0.11.tar.gz -
Subject digest:
f4d057a276ca80d6777b7278094ff23b5bb983527c6e0982e94146c2dd4a3890 - Sigstore transparency entry: 771703672
- Sigstore integration time:
-
Permalink:
Neehan/schema-search@69e3de1fddda64bdc575bcc85633d2fda41522d3 -
Branch / Tag:
refs/tags/v1.0.11 - Owner: https://github.com/Neehan
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@69e3de1fddda64bdc575bcc85633d2fda41522d3 -
Trigger Event:
release
-
Statement type:
File details
Details for the file schema_search-1.0.11-py3-none-any.whl.
File metadata
- Download URL: schema_search-1.0.11-py3-none-any.whl
- Upload date:
- Size: 41.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d07b7cc8037de552cb2d52cbad15d0d7b4d35322a5a894f737fe3c5bac525ae4
|
|
| MD5 |
3c5dc037f4fedcd8f3273efa1db55430
|
|
| BLAKE2b-256 |
3d26e8b04c4af52294c8745d541e83b7e28e1accef6bca3a755e51e29d9f28da
|
Provenance
The following attestation bundles were made for schema_search-1.0.11-py3-none-any.whl:
Publisher:
publish.yml on Neehan/schema-search
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
schema_search-1.0.11-py3-none-any.whl -
Subject digest:
d07b7cc8037de552cb2d52cbad15d0d7b4d35322a5a894f737fe3c5bac525ae4 - Sigstore transparency entry: 771703681
- Sigstore integration time:
-
Permalink:
Neehan/schema-search@69e3de1fddda64bdc575bcc85633d2fda41522d3 -
Branch / Tag:
refs/tags/v1.0.11 - Owner: https://github.com/Neehan
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@69e3de1fddda64bdc575bcc85633d2fda41522d3 -
Trigger Event:
release
-
Statement type:







