Web app for Scrapyd cluster management, with support for Scrapy log analysis & visualization.

Project description
English | 简体中文
ScrapydWeb: Web app for Scrapyd cluster management, with support for Scrapy log analysis & visualization.








Scrapyd ScrapydWeb LogParser
Recommended Reading
How to efficiently manage your distributed web scraping projects
How to set up Scrapyd cluster on Heroku
Demo
Features
View contents
-
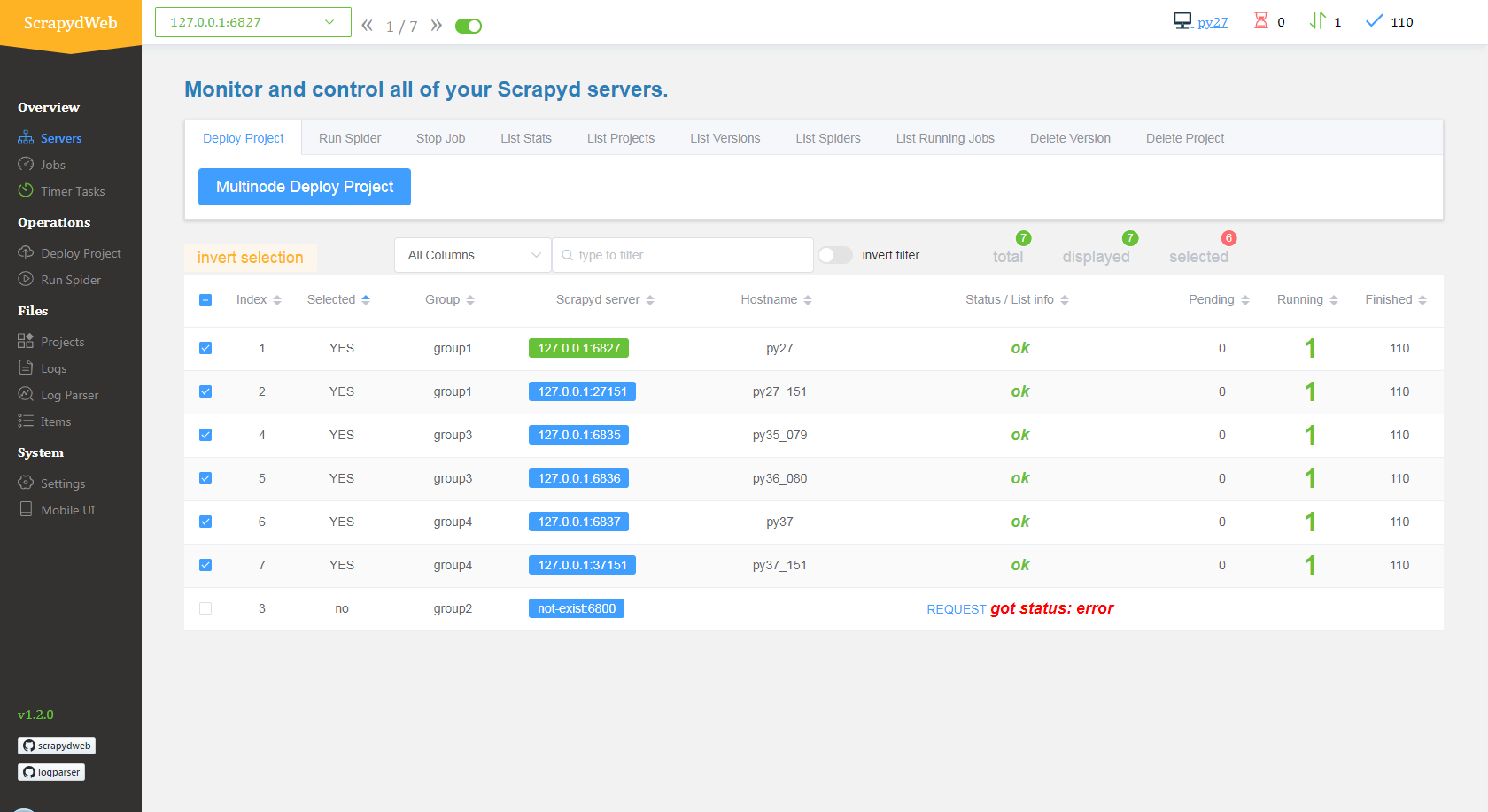
Scrapyd Cluster Management
- All Scrapyd JSON API Supported
- Group, filter and select any number of nodes
- Execute command on multinodes with just a few clicks
-
Scrapy Log Analysis
- Stats collection
- Progress visualization
- Logs categorization
-
Enhancements
- Auto packaging
- Integrated with LogParser
- Timer tasks
- :e-mail: Monitor & Alert
- Mobile UI
- Basic auth for web UI
Getting Started
View contents
Prerequisites
Make sure that Scrapyd has been installed and started on all of your hosts.
Note that for remote access, you have to manually set 'bind_address = 0.0.0.0' in the configuration file of Scrapyd and restart Scrapyd to make it visible externally.
Install
- Use pip:
pip install scrapydweb
Note that you may need to execute python -m pip install --upgrade pip first in order to get the latest version of scrapydweb, or download the tar.gz file from https://pypi.org/project/scrapydweb/#files and get it installed via pip install scrapydweb-x.x.x.tar.gz
- Use git:
pip install --upgrade git+https://github.com/my8100/scrapydweb.git
Or:
git clone https://github.com/my8100/scrapydweb.git
cd scrapydweb
python setup.py install
Start
- Start ScrapydWeb via command
scrapydweb. (a config file would be generated for customizing settings at the first startup.) - Visit http://127.0.0.1:5000 (It's recommended to use Google Chrome for a better experience.)
Browser Support
The latest version of Google Chrome, Firefox, and Safari.
Running the tests
View contents
$ git clone https://github.com/my8100/scrapydweb.git
$ cd scrapydweb
# To create isolated Python environments
$ pip install virtualenv
$ virtualenv venv/scrapydweb
# Or specify your Python interpreter: $ virtualenv -p /usr/local/bin/python3.7 venv/scrapydweb
$ source venv/scrapydweb/bin/activate
# Install dependent libraries
(scrapydweb) $ python setup.py install
(scrapydweb) $ pip install pytest
(scrapydweb) $ pip install coverage
# Make sure Scrapyd has been installed and started, then update the custom_settings item in tests/conftest.py
(scrapydweb) $ vi tests/conftest.py
(scrapydweb) $ curl http://127.0.0.1:6800
# '-x': stop on first failure
(scrapydweb) $ coverage run --source=scrapydweb -m pytest tests/test_a_factory.py -s -vv -x
(scrapydweb) $ coverage run --source=scrapydweb -m pytest tests -s -vv --disable-warnings
(scrapydweb) $ coverage report
# To create an HTML report, check out htmlcov/index.html
(scrapydweb) $ coverage html
Built With
Changelog
Detailed changes for each release are documented in the HISTORY.md.
Author
 my8100 |
|---|
Contributors
 Kaisla |
|---|
License
This project is licensed under the GNU General Public License v3.0 - see the LICENSE file for details.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file scrapydweb-1.6.0.tar.gz.
File metadata
- Download URL: scrapydweb-1.6.0.tar.gz
- Upload date:
- Size: 684.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.0.1 CPython/3.12.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9e100682c4250f4167ae2d67cae8b7ffb9d6cf0332ab51f14943d060703241bc
|
|
| MD5 |
d1a1919fb44030e6710b422785006697
|
|
| BLAKE2b-256 |
e2c56c14ff13f09d29267bd8574571707dd9bcd053530c561a1f9bb4189819a0
|
File details
Details for the file scrapydweb-1.6.0-py3-none-any.whl.
File metadata
- Download URL: scrapydweb-1.6.0-py3-none-any.whl
- Upload date:
- Size: 702.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.0.1 CPython/3.12.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
78752103da19d36bbdd0ab332ef4b66466a5c84641ce1464535112ead2abef11
|
|
| MD5 |
79adbba0caeb20b2bde85b9d80189d4f
|
|
| BLAKE2b-256 |
bd4684ae90d0562cad806fb4d108d7213594eb3f3b2ec2aafa7e7a8c228c8c75
|







