A package to parse SEC filings

Project description
SEC Parsers



Parses non-standardized SEC filings into structured xml. Use cases include LLMs, NLP, and textual analysis. Average parse-time for a 100 page document is 0.4 seconds. Package is a WIP, and is updated frequently.
Supported filing types are 10-K, 10-Q, 8-K, S-1, 20-F. More will be added soon, or you can write your own! How to write a Custom Parser in 5 minutes
sec-parsers is maintained by John Friedman, and is under the MIT License. If you use sec-parsers for a project, please let me know! Feedback
URGENT: Advice on how to name functions used by users is needed. I don't want to deprecate function names in the future. Link
Notice download_sec_filing is being deprecated.
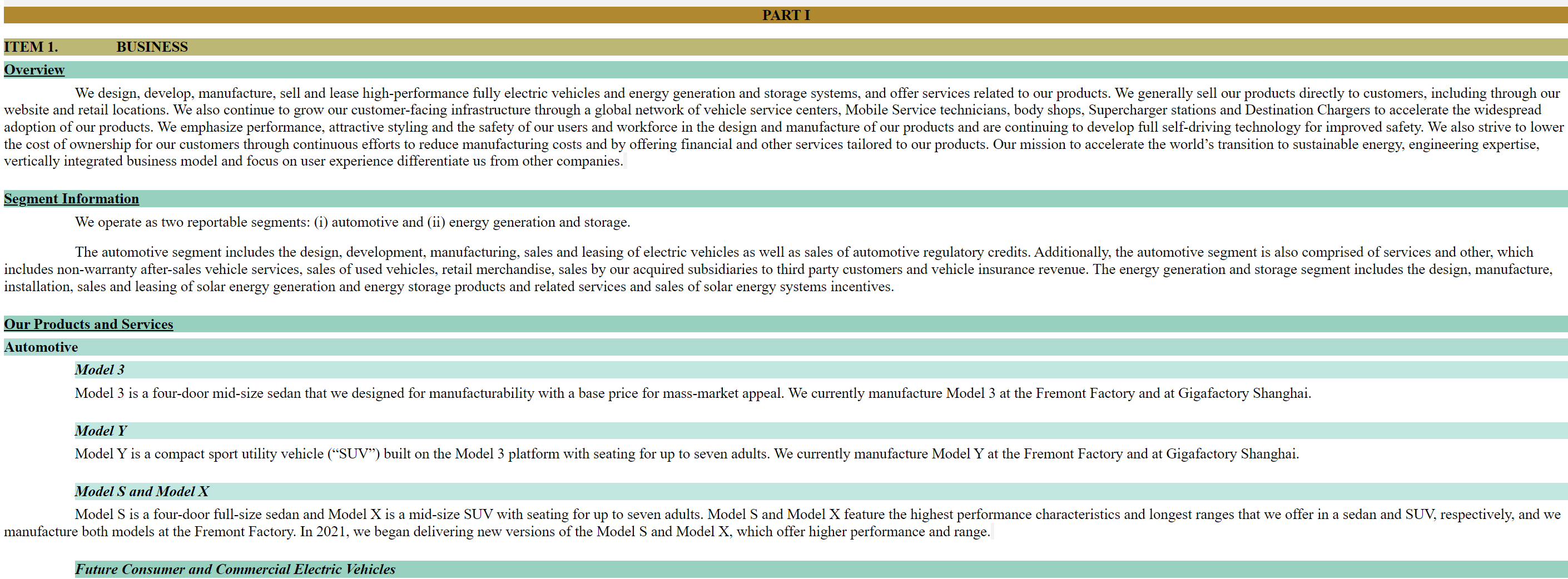
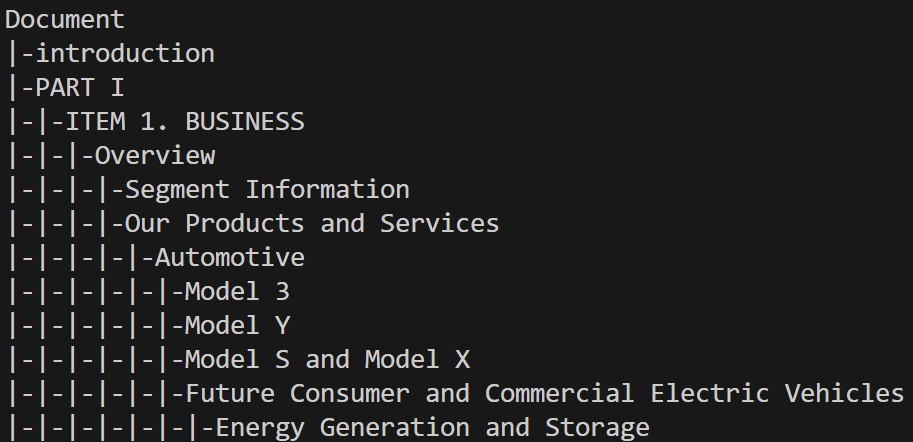
Installation
pip install sec-parsers # base package
pip install sec-parsers['all'] # installs all extras
pip install sec-parsers['downloaders'] # installs downloaders extras
pip install sec-parsers['visualizers'] # installs visualizers extras
Quickstart
Load package
from sec_parsers import Filing
Downloading html file (new)
from sec_downloaders import SEC_Downloader
downloader = SEC_Downloader()
downloader.set_headers("John Doe", "johndoe@example.com")
download = downloader.download(url)
filing = Filing(download)
Downloading html file (old)
from sec_parsers download_sec_filing
html = download_sec_filing('https://www.sec.gov/Archives/edgar/data/1318605/000162828024002390/tsla-20231231.htm')
filing = Filing(html)
Parsing
filing.parse() # parses filing
filing.visualize() # opens filing in webbrowser with highlighted section headers
filing.find_sections_from_title(title) # finds section by title, e.g. 'item 1a'
filing.find_sections_from_text(text) # finds sections which contains your text
filing.get_tree(node) # if no argument specified returns xml tree, if node specified, returns that nodes tree
filing.get_title_tree() # returns xml tree using titles instead of tags. More descriptive than get_tree.
filing.get_subsections_from_section() # get children of a section
filing.get_nested_subsections_from_section() # get descendants of a section
filing.set_filing_type(type) # e.g. 'S-1'. Use when automatic detection fails
filing.save_xml(file_name,encoding='utf-8')
filing.save_csv(file_name,encoding='ascii')
Additional Resources:
- quickstart
- How to write a Custom Parser in 5 minutes
- Archive of Parsed XMLs / CSVs - Last updated 7/24/24.
- example parsed filing
- example parsed filing exported to csv.
Features:
- lots of filing types
- export to xml, csv, with option to convert to ASCII
- visualization
Feature Requests:
- company metadata (sharif) - will add to downloader
- filing metadata (sharif) - waiting for SEC Downloaders first release
- Export to dta (Denis)
- DEF 14A, DEFM14A (Denis)
- Export to markdown (Astarag)
- Better parsing_string handling. Opened an issue. (sharif)
SEC Downloader
Not released yet, different repo.
- Download by company name, ticker, etc
- Download all 10-Ks, etc
- Rate limit handling
- asynchronous downloads
Statistics
- Speed: On average, 10-K filings parse in 0.25 seconds. There were 7,118 10-K annual reports filed in 2023, so to parse all 10-Ks from 2023 should take about half an hour.
- Improving speed is currently not a priority. If you need more speed, let me know. I think I can increase parsing speed to ~ .01 seconds per 10-K.
Other packages useful for SEC filings
Updates
Towards Version 1:
- Most/All SEC text filings supported
- Few errors
- xml
Might be done along the way:
- Faster parsing, probably using streaming approach, and combining modules together.
- Introduction section parsing
- Signatures section parsing
- Better visualization interface (e.g. like pdfviewer for sections)
Beyond Version 1:
To improve the package beyond V1 it looks like I need compute and storage. Not sure how to get that. Working on it.
Metadata
- Clustering similar section titles using ML (e.g. seasonality headers)
- Adding tags to individual sections using small LLMs (e.g. tag for mentions supply chains, energy, etc)
Other
- Table parsing
- Image OCR
- Parsing non-html filings
Current Priority list:
- look at code duplication w.r.t to style detectors, e.g. all caps and emphasis. may want to combine into one detector
- yep this is a priority. have to handle e.g. Introduction and Segment Overview as same rule. Bit difficult. Will think over.
- better function names - need to decide terminology soon.
- consider adding table of contents, forward looking information, etc
- forward looking information, DOCUMENTS INCORPORATED BY REFERENCE, TABLE OF CONTENTS - go with a bunch,
- fix layering issue - e.g. top div hides sections
- make trees nicer
- add more filing types
- fix all caps and emphasis issue
- clean text
- Better historical conversion: handle if PART I appears multiple times as header, e.g. logic here item 1 continued.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file sec_parsers-0.549.tar.gz.
File metadata
- Download URL: sec_parsers-0.549.tar.gz
- Upload date:
- Size: 19.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.0 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bfd4a610a45aec57b5757552c4a2421990ecfe0e89873efd08718545512c2e2b
|
|
| MD5 |
bb86af3719d2d0db31cca4fb32cd0158
|
|
| BLAKE2b-256 |
2306f4639263631b08f692e53c0e8e52b730b52bea02fb204d425b76176df057
|
File details
Details for the file sec_parsers-0.549-py3-none-any.whl.
File metadata
- Download URL: sec_parsers-0.549-py3-none-any.whl
- Upload date:
- Size: 21.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.0 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1989e9e4d894bb6a65876e123941d53423e2ed9301eae9766fdfe26cd3bf965b
|
|
| MD5 |
04c245baf74e0f9f2368f30077a039dd
|
|
| BLAKE2b-256 |
e87032e07c28c127f76ad44a3398128cb6968b6aa80a9f57a955478c14cb847c
|







