A package to parse SEC filings

Project description
SEC Parsers
Parses non-standardized SEC 10-K filings into well structured detailed xml. Use cases include LLMs, NLP, and textual analysis. This is a WIP. Not every file will parse correctly.
Current supported file types: 10-K, 10-Q

Installation
pip install sec-parsers
Quickstart
from sec_parsers import Filing, download_sec_filing
html = download_sec_filing('https://www.sec.gov/Archives/edgar/data/1318605/000162828024002390/tsla-20231231.htm')
filing = Filing(html)
filing.parse() # parses filing
filing.visualize() # opens filing in webbrowser with highlighted section headers
filing.find_nodes_by_title(title) # finds node by title, e.g. 'item 1a'
filing.find_nodes_by_text(text) # finds nodes which contains your text
filing.get_tree(node) # if no argument specified returns xml tree, if node specified, returns that nodes tree
filing.get_title_tree() # returns xml tree using titles instead of tags. More descriptive than get_tree.
filing.save_xml(file_name)
filing.save_csv(file_name)
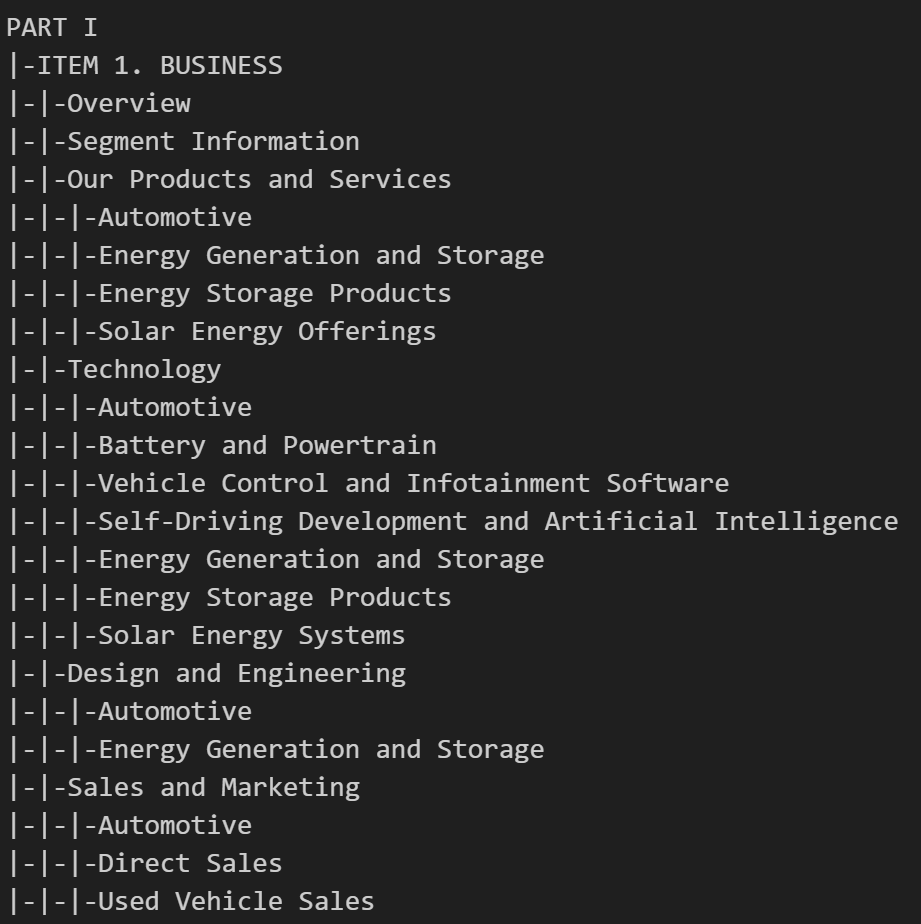
For more information look at the quickstart, or view a parsed Tesla 10-K here. SEC Parsers also supports exporting to csv, see here.
Links:
- GitHub
- Archive of Parsed XMLs / CSVs - Last updated 7/10/24.
Problem:
SEC filings are human readable, but messy html makes it hard for machines to detect and read information by section. This is especially important for NLP / RAG using LLMs.
How SEC Parsers works:
- Detects headers in filings using:
- element tags, e.g.
<b>Item 1</b> - element css, e.g.
<p style="font-weight: bold;">Item 1.</p> - text style, e.g. emphasis style "Purchase of Significant Equipment"
- relative location of above elements to each other
- Calculates hierarchy of headers, and converts to a tree structure
Roadmap:
- Parser that converts >95% of filings into nicely formatted xml trees. Currently at 90%.
- Apply data science on xml to cluster headers, e.g. seasonality, seasonal variation etc, to make xml easier to work with.
- LLMs on section text to create node metadata (e.g. is anything said in this section, or 2000 chars to say we are not required to fill out this section)
- Backwards compatability for text files. (extends historical reach back into early 1900s)
Possible future features
- better hierarchy calculation
- more filings supported
- better rag integration
- converting html tables to nice xml tables
- hosting cleaned xml files online
- better color scheme (color scheme for headers, ignored_elements - e.g. page numbers, text)
- better descriptions of functions
- faster - not a priority, but kinda fun to program. Code cleanup + removing redundancies may help a lot.
Features
- Parse 10K
- Export to XML, CSV
- XBRL metadata
Feature request:
- save_dta - save xml to dta. similar to csv function
- better selection by titles. e.g. selecting by item1, will also return item 1a,... not sure how to set this up in a nice way
- More XBRL stuff
Statistics
- 100% parsed html rate
- 99.3% conversion to xml rate.
- On average ~1s to parse file (range .1s-3s).
Issues
- handle if PART I appears multiple times as header, e.g. logic here item 1 continued. Develop logic to handle this. Probably in cleanup?
TODO
- Currently I've only focused on parts parsing. Signature node has been added, but tree is likely to be crazy. Focusing on reducing parts parsing tree crazyness first
- we fixed one table issue, now need to account for too much tables https://www.sec.gov/Archives/edgar/data/18255/000001825518000024/cato10k2017-jrs.htm
- Code cleanup. Right now I'm tweaking code to increase parse rate, eventually need to incorporate lessons learned, and rewrite.
Other people's SEC stuff
- edgartools - good interface for interacting with SEC's EDGAR system
- sec-parser - oops, we have similar names. They were first, my bad. They parse 10-Qs well.
- sec-api. Paid API to search / download SEC filings. Basically, SEC's EDGAR but setup in a much nicer format. I haven't used it since it costs money.
- Bill McDonald's 10-X Archive
- Eclect - "Save time reading SEC filings with the help of machine learning.". Paid.
- Textblocks.app - Paid API to extract and analyze structured data from SEC filings. The approach seems to be similar to mine.
- Yu Zhu - article with an approach to parse 10K filings using regex
- Wharton Research Data Services - heard they have SEC stuff, looking into it
- Gist - using regex and beautifulsoup to parse 10Ks
- Victor Dahan - Sentiment Analysis of 10-K Files
- edgarWebR - edgarWebR provides an interface to access the SEC’s EDGAR system for company financial filings.
- NLP in the stock market - Leveraging sentiment analysis on 10-k fillings as an edge
- Computer Vision using OpenCV
- LLMs (I believe unstructured.io does something like this)
- Transformers
Other people's papers related to SEC stuff

Project details
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
sec_parsers-0.528.tar.gz
(17.7 kB
view hashes)
Built Distribution
Close
Hashes for sec_parsers-0.528-py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | e6fa62be35e48ee6b90356aca18cb2e68983ce046cebacabcf9a49039324c4de |
|
| MD5 | df9f56c89e676c52a1d189e90cb3ad57 |
|
| BLAKE2b-256 | 36823bbf30222e1a4a6c3a7e379dd98e2e7f0c4e037be611874ba6a03697d828 |







