SecretScraper is a web scraper tool that can scrape the content through target websites and extract secret information via regular expression.

Project description
SecretScraper


Overview
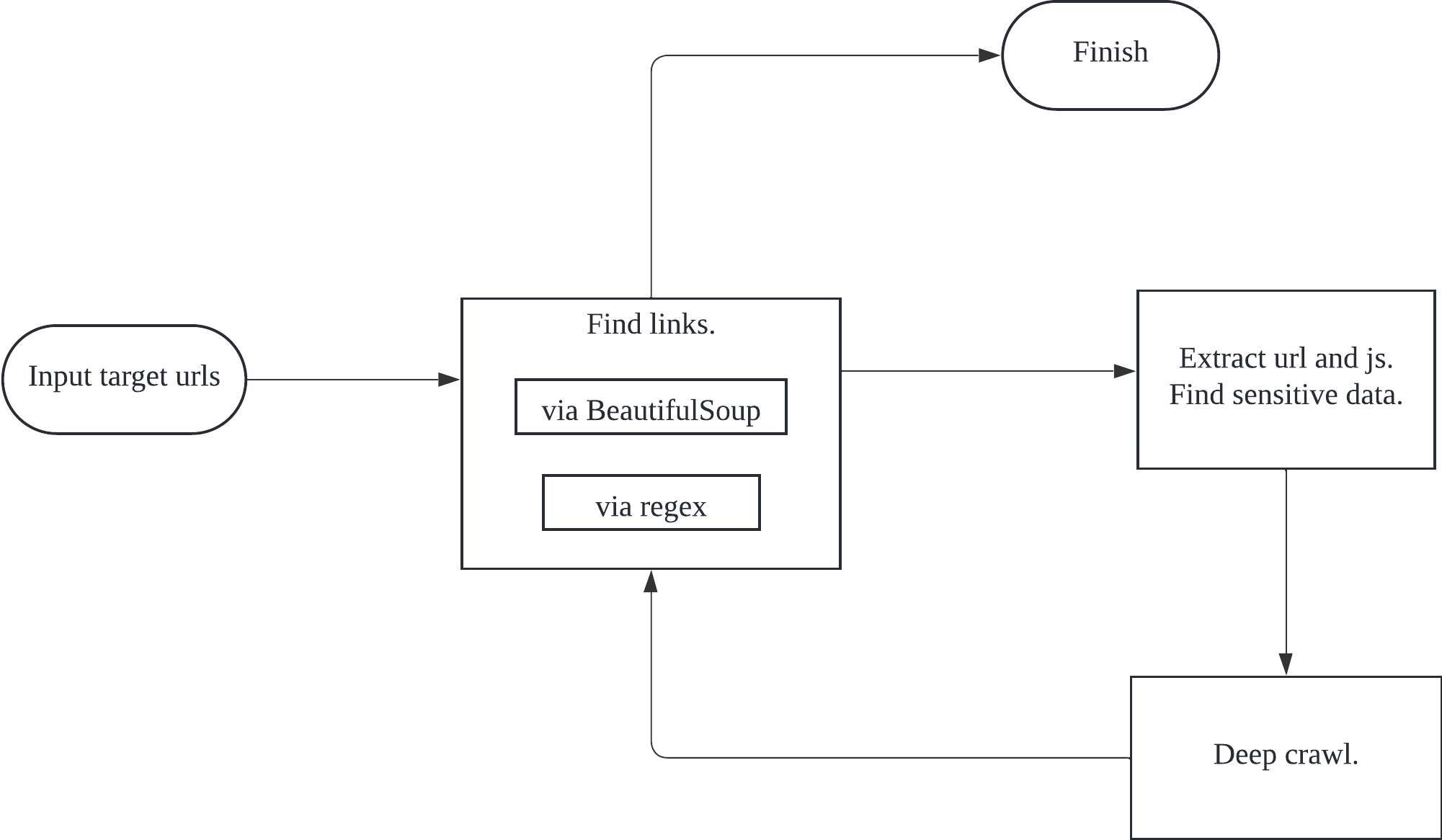
SecretScraper is a highly configurable web scrape tool that crawl links from target websites and scrape sensitive data via regular expression.
Feature
- Web crawler: extract links via both DOM hierarchy and regex
- Support domain white list and black list
- Support multiple targets, input target URLs from a file
- Support local file scan
- Scalable customization: header, proxy, timeout, cookie, scrape depth, follow redirect, etc.
- Built-in regex to search for sensitive information
- Flexible configuration in yaml format
Prerequisite
- Platform: Test on MaxOS, Ubuntu and Windows.
- Python Version >= 3.9
Usage
Install
pip install secretscraper
Basic Usage
Start with single target:
secretscraper -u https://scrapeme.live/shop/
Start with multiple targets:
secretscraper -f urls
# urls
http://scrapeme.live/1
http://scrapeme.live/2
http://scrapeme.live/3
http://scrapeme.live/4
http://scrapeme.live/1
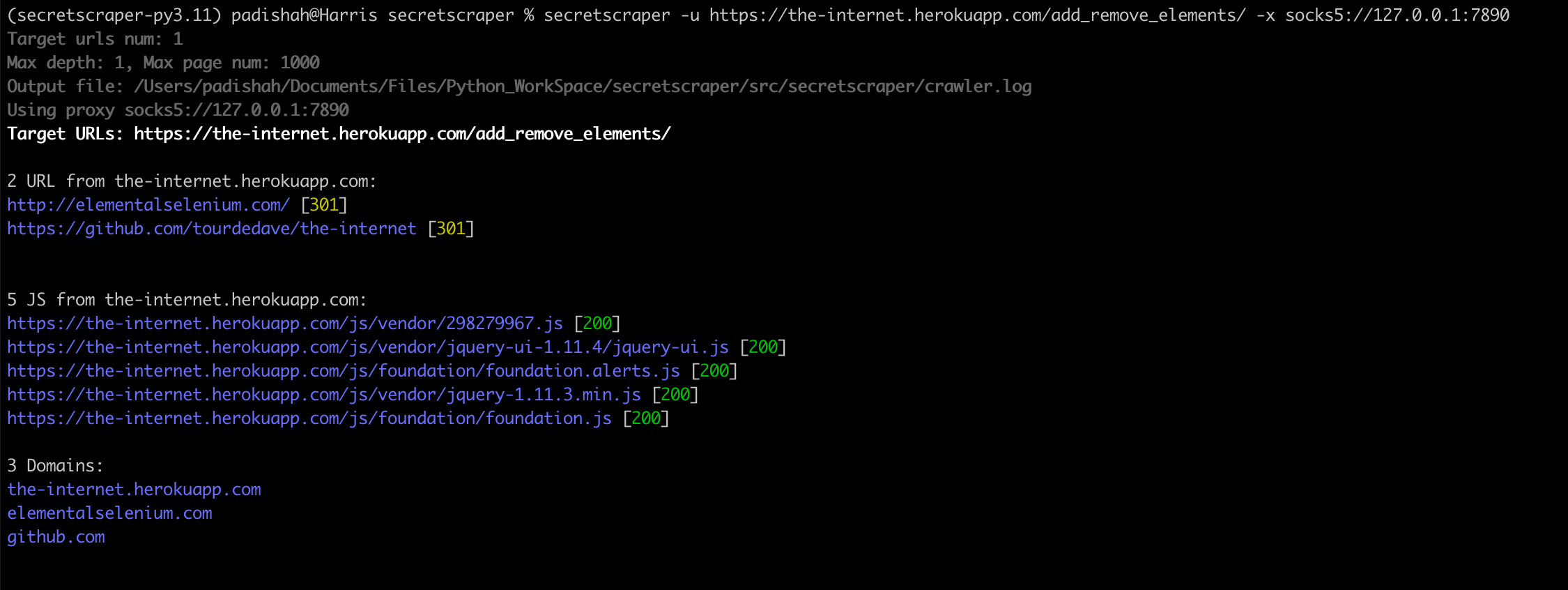
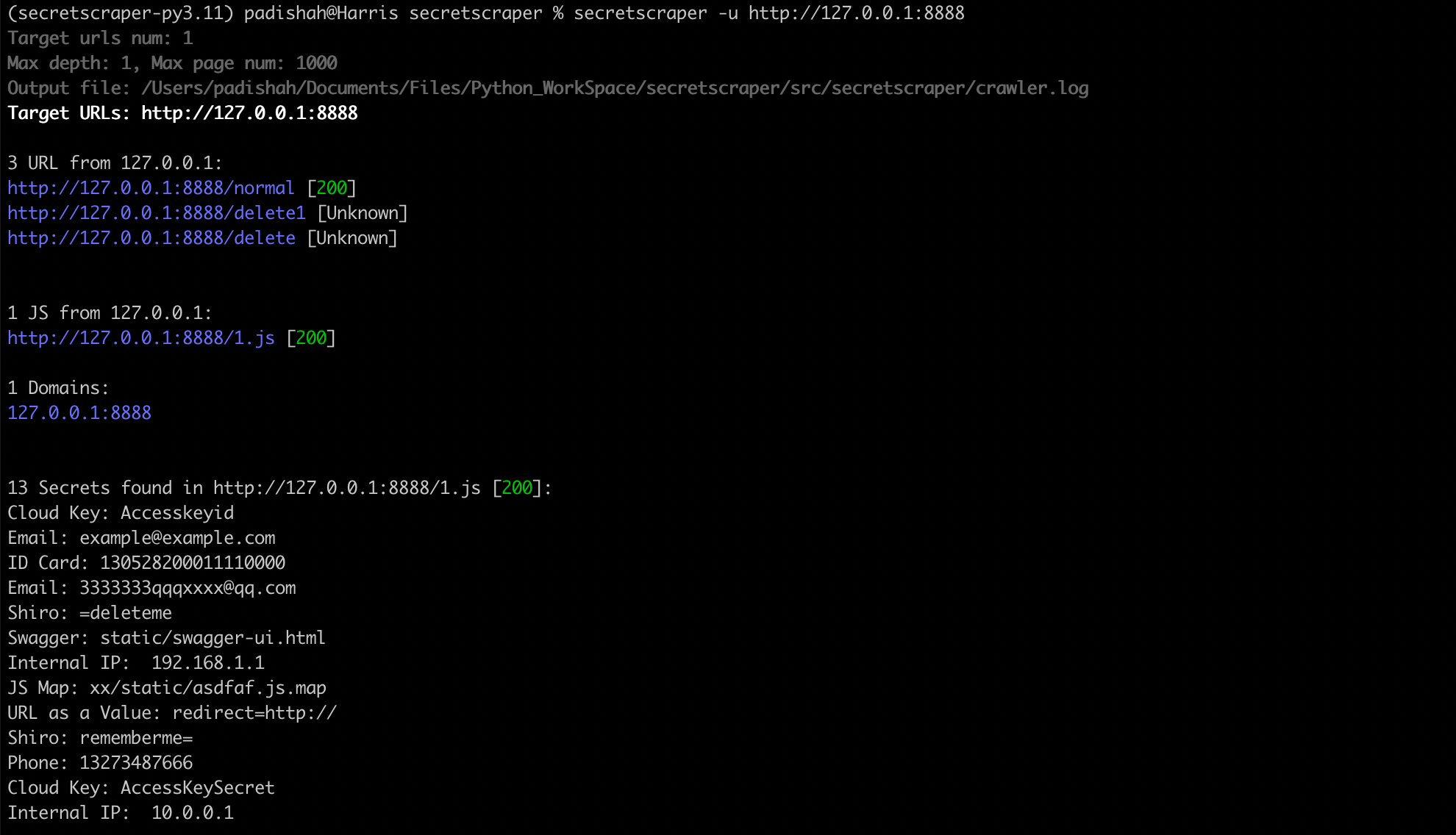
Sample output:
All supported options:
> secretscraper --help
Usage: secretscraper [OPTIONS]
Main commands
Options:
-V, --version Show version and exit.
--debug Enable debug.
-a, --ua TEXT Set User-Agent
-c, --cookie TEXT Set cookie
-d, --allow-domains TEXT Domain white list, wildcard(*) is supported,
separated by commas, e.g. *.example.com,
example*
-D, --disallow-domains TEXT Domain black list, wildcard(*) is supported,
separated by commas, e.g. *.example.com,
example*
-f, --url-file FILE Target urls file, separated by line break
-i, --config FILE Set config file, defaults to settings.yml
-m, --mode [1|2] Set crawl mode, 1(normal) for max_depth=1,
2(thorough) for max_depth=2, default 1
--max-page INTEGER Max page number to crawl, default 100000
--max-depth INTEGER Max depth to crawl, default 1
-o, --outfile FILE Output result to specified file
-s, --status TEXT Filter response status to display, seperated by
commas, e.g. 200,300-400
-x, --proxy TEXT Set proxy, e.g. http://127.0.0.1:8080,
socks5://127.0.0.1:7890
-H, --hide-regex Hide regex search result
-F, --follow-redirects Follow redirects
-u, --url TEXT Target url
--detail Show detailed result
-l, --local PATH Local file or directory, scan local
file/directory recursively
--help Show this message and exit.
Advanced Usage
Thorough Crawl
The max depth is set to 1, which means only the start urls will be crawled. To change that, you can specify
via --max-depth <number>. Or in a simpler way, use -m 2 to run the crawler in thorough mode which is equivalent
to --max-depth 2. By default the normal mode -m 1 is adopted with max depth set to 1.
secretscraper -u https://scrapeme.live/shop/ -m 2
Write Results to File
secretscraper -u https://scrapeme.live/shop/ -o result.log
Hide Regex Result
Use -H option to hide regex-matching results. Only found links will be displayed.
secretscraper -u https://scrapeme.live/shop/ -H
Extract secrets from local file
secretscraper -l <dir or file>
Customize Configuration
The built-in config is shown as below. You can assign custom configuration via -i settings.yml.
verbose: false
debug: false
loglevel: warning
logpath: log
proxy: "" # http://127.0.0.1:7890
max_depth: 1 # 0 for no limit
max_page_num: 1000 # 0 for no limit
timeout: 5
follow_redirects: false
workers_num: 1000
headers:
Accept: "*/*"
Cookie: ""
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0
urlFind:
- '["''‘“`]\s{0,6}(https{0,1}:[-a-zA-Z0-9()@:%_\+.~#?&//={}]{2,100}?)\s{0,6}["''‘“`]'
- =\s{0,6}(https{0,1}:[-a-zA-Z0-9()@:%_\+.~#?&//={}]{2,100})
- '["''‘“`]\s{0,6}([#,.]{0,2}/[-a-zA-Z0-9()@:%_\+.~#?&//={}]{2,100}?)\s{0,6}["''‘“`]'
- '"([-a-zA-Z0-9()@:%_\+.~#?&//={}]+?[/]{1}[-a-zA-Z0-9()@:%_\+.~#?&//={}]+?)"'
- href\s{0,6}=\s{0,6}["'‘“`]{0,1}\s{0,6}([-a-zA-Z0-9()@:%_\+.~#?&//={}]{2,100})|action\s{0,6}=\s{0,6}["'‘“`]{0,1}\s{0,6}([-a-zA-Z0-9()@:%_\+.~#?&//={}]{2,100})
jsFind:
- (https{0,1}:[-a-zA-Z0-9()@:%_\+.~#?&//=]{2,100}?[-a-zA-Z0-9()@:%_\+.~#?&//=]{3}[.]js)
- '["''‘“`]\s{0,6}(/{0,1}[-a-zA-Z0-9()@:%_\+.~#?&//=]{2,100}?[-a-zA-Z0-9()@:%_\+.~#?&//=]{3}[.]js)'
- =\s{0,6}[",',’,”]{0,1}\s{0,6}(/{0,1}[-a-zA-Z0-9()@:%_\+.~#?&//=]{2,100}?[-a-zA-Z0-9()@:%_\+.~#?&//=]{3}[.]js)
dangerousPath:
- logout
- update
- remove
- insert
- delete
rules:
- name: Swagger
regex: \b[\w/]+?((swagger-ui.html)|(\"swagger\":)|(Swagger UI)|(swaggerUi)|(swaggerVersion))\b
loaded: true
- name: ID Card
regex: \b((\d{8}(0\d|10|11|12)([0-2]\d|30|31)\d{3}\$)|(\d{6}(18|19|20)\d{2}(0[1-9]|10|11|12)([0-2]\d|30|31)\d{3}(\d|X|x)))\b
loaded: true
- name: Phone
regex: \b((?:(?:\+|00)86)?1(?:(?:3[\d])|(?:4[5-79])|(?:5[0-35-9])|(?:6[5-7])|(?:7[0-8])|(?:8[\d])|(?:9[189]))\d{8})\b
loaded: true
- name: JS Map
regex: \b([\w/]+?\.js\.map)
loaded: true
- name: URL as a Value
regex: (\b\w+?=(https?)(://|%3a%2f%2f))
loaded: true
- name: Email
regex: \b(([a-z0-9][_|\.])*[a-z0-9]+@([a-z0-9][-|_|\.])*[a-z0-9]+\.([a-z]{2,}))\b
loaded: true
- name: Internal IP
regex: '[^0-9]((127\.0\.0\.1)|(10\.\d{1,3}\.\d{1,3}\.\d{1,3})|(172\.((1[6-9])|(2\d)|(3[01]))\.\d{1,3}\.\d{1,3})|(192\.168\.\d{1,3}\.\d{1,3}))'
loaded: true
- name: Cloud Key
regex: \b((accesskeyid)|(accesskeysecret)|\b(LTAI[a-z0-9]{12,20}))\b
loaded: true
- name: Shiro
regex: (=deleteMe|rememberMe=)
loaded: true
- name: Suspicious API Key
regex: "[\"'][0-9a-zA-Z]{32}['\"]"
loaded: true
TODO
- Support headless browser
- Add regex doc reference
- Fuzz path that are 404
- Separate subdomains in the result
- Optimize url collector [//]: # (- [ ] Employ jsbeautifier)
- Generate configuration file
- Detect dangerous paths and avoid requesting them
- Support url-finder output format, add
--detailoption - Support windows
- Scan local file
- Extract links via regex
Change Log
2024.4.29 Version 1.3.9
- Add
--validateoption - Optimize url collector
- Optimize built-in regex
2024.4.29 Version 1.3.8
- Optimize log output
- Optimize the performance of
--debugoption
2024.4.29 Version 1.3.7
- Test on multiple python versions
- Support python 3.9~3.11
2024.4.29 Version 1.3.6
- Repackage
2024.4.28 Version 1.3.5
- New Features
- Support windows
- Optimize crawler
- Prettify output, add
--detailoption - Generate default configuration to settings.yml
- Avoid requesting dangerous paths
2024.4.28 Version 1.3.2
- New Features
- Extract links via regex
2024.4.26 Version 1.3.1
- New Features
- Support scan local files
2024.4.15
- Add status to url result
- All crawler test passed
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Hashes for secretscraper-1.3.9.3-py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | 8c7c198c9dfda90c0fdbcdcaaa92b620bd93f14e6b718001dc33931e69602775 |
|
| MD5 | 32c56851ce71f1ca05025c0186e83900 |
|
| BLAKE2b-256 | 8df4b3dc80b0309d01234d02214ec899c5e4cf83b694b084758b7f31309adbc3 |







