Spark ETL Utility Framework

Project description
SeedSpark
Why Spark
Apache Spark is a unified analytics engine for large-scale data processing. It achieves high performance for both batch and streaming data, using a Directed Acyclic Graph (DAG) scheduler, a query optimizer, and a physical execution engine
Spark’s design philosophy centers around four key characteristics:
- Speed: Leveraging in-memory data processing, Spark executes tasks up to 100 times faster in memory and 10 times faster on disk than traditional big data processing systems (e.g., Hadoop MapReduce).
- Ease of Use: Through high-level APIs and built-in modules, Spark simplifies the process of complex data transformations and analyses, making it accessible to both developers and data analysts.
- Modularity and Extensibility: Spark's modular nature allows it to be used for a range of data processing tasks from batch processing to real-time streams and machine learning. Extensibility with numerous data sources and libraries further enhances its utility.
- Unified Analytics: Spark's unified framework reduces the complexity involved in processing data that might otherwise require multiple engines or different technologies.
Spark’s architecture is designed to optimize efficiency. The use of RDDs (Resilient Distributed Datasets) and subsequent abstractions like DataFrames and Datasets simplifies data manipulation while providing fault tolerance. By retaining intermediate results in memory rather than on disk, Spark minimizes costly I/O operations that are a common bottleneck in big data processing
The DAG execution engine enhances this by allowing for more complex operational pipelines and optimizing workflows dynamically. This approach minimizes redundant data shuffling across the cluster, leading to significant performance improvements
Run on GitPod
Start Dev Env in Gitpod:

Force build:
Installation
Install Python 3.10 or above
pyenv install 3.11 \
&& pyenv global 3.11
Install Scala and Spark
make install-scala &&\
make install-spark
Optional: If you want yo u can verify the installation commands
$ make --just-print install-spark
It will output following:
echo "Installing Hadoop..."
source "$HOME/.sdkman/bin/sdkman-init.sh" && sdk install hadoop 3.3.5
# Set Global version
source "$HOME/.sdkman/bin/sdkman-init.sh" && sdk default hadoop 3.3.5
echo "Installing Spark..."
source "$HOME/.sdkman/bin/sdkman-init.sh" && sdk install spark 3.5.0
# Set Global version
source "$HOME/.sdkman/bin/sdkman-init.sh" && sdk default spark 3.5.0
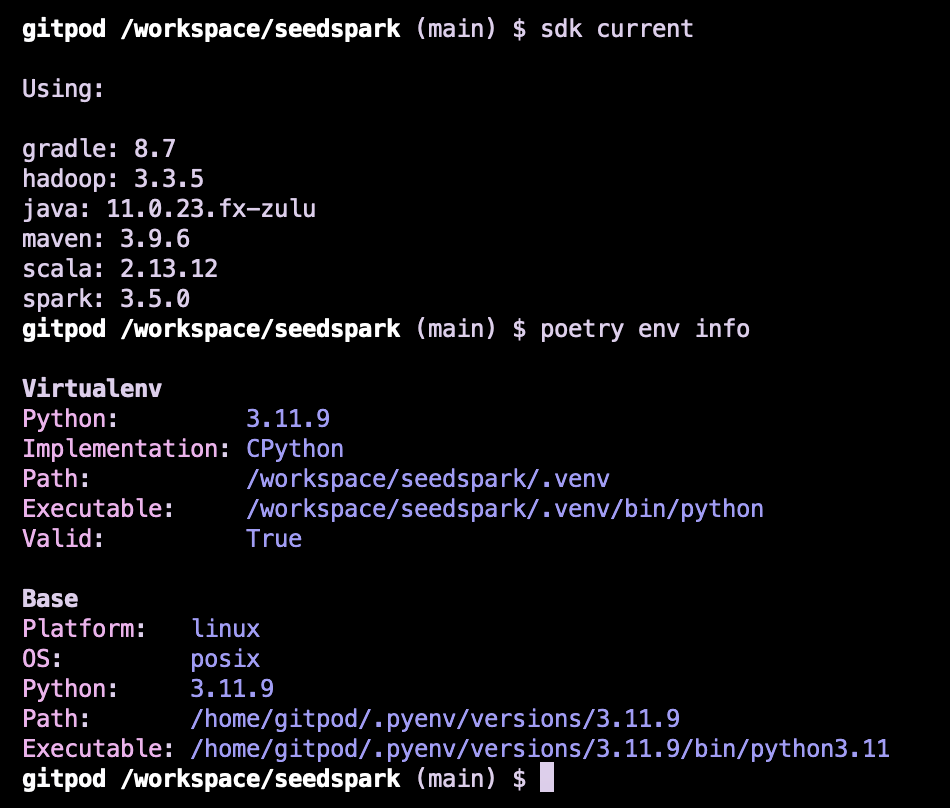
Verify Installation
poetry env info
poetry version
sdk version
Run SDK Current to verify current packages
sdk current
should show:
Using:
java: 11.0.22-zulu
scala: 2.13.12
spark: 3.5.0
Then verify spark-shell version
spark-shell --version
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.5.0
/_/
Using Scala version 2.12.18, OpenJDK 64-Bit Server VM, 11.0.22
Verify top level packages
poetry show -T
PySpark version should match above spark version
pyspark 3.5.0 Apache Spark Python API
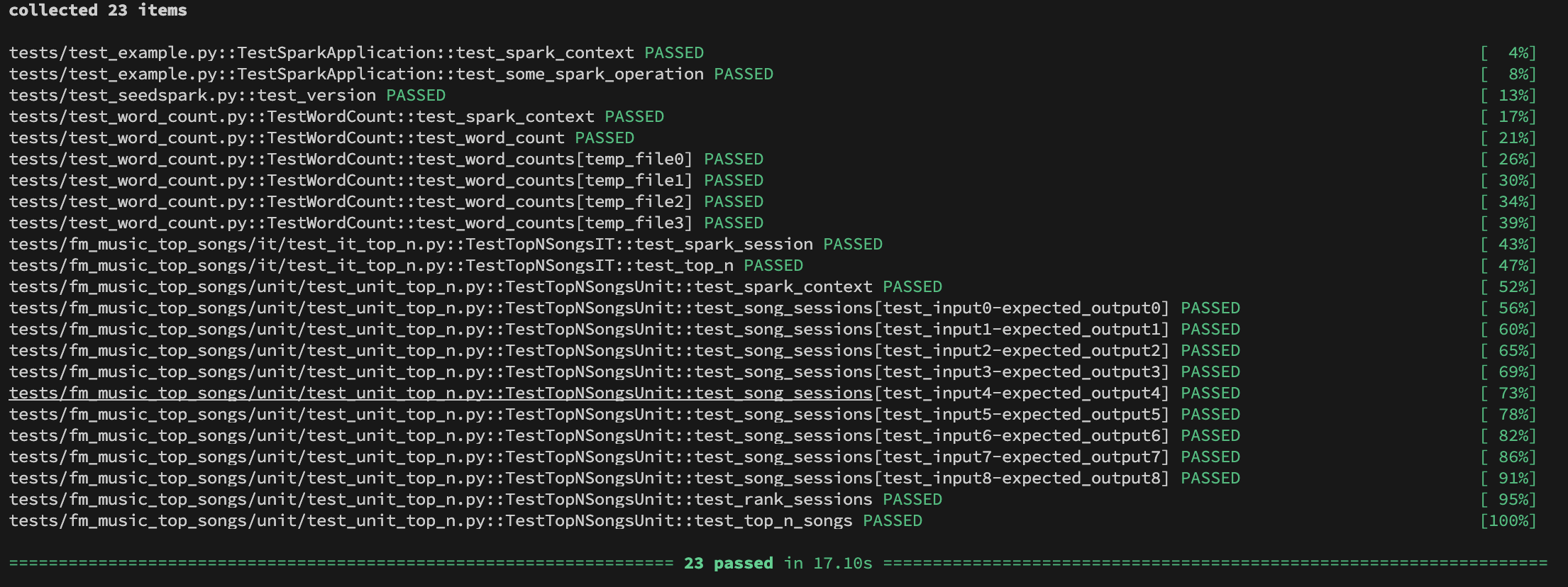
Run Pytest
# Install packages
poetry install --with=testing --no-interaction
# Run Pytest
poetry run coverage run -m pytest -vv tests --reruns 5 --reruns-delay 20
Then Check the code file seedspark/examples/music_sessions_top_n.py
Update or Replace with actual path of music_sessions_data.tsv
Then run following:
# OPTIONAL - Skip this if already downloaded the dataset OR Download dataset
cd datasets/
pip install pandas requests tqdm; python lastfm_dataset_1k.py
# Update or Replace with actual path of new music_sessions_data.tsv
cd ..
# Execute Spark APP
poetry run python seedspark/examples/music_sessions_top_n.py
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file seedspark-0.5.1.tar.gz.
File metadata
- Download URL: seedspark-0.5.1.tar.gz
- Upload date:
- Size: 18.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.8.2 CPython/3.12.2 Darwin/23.4.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a6f4127866a32d191adb57800651a90c9885997c7ea8bfd7acecbb0f64723f87
|
|
| MD5 |
9ebdadba1404f1ca40c73995b9a48ee8
|
|
| BLAKE2b-256 |
67b2e5c82b313b44acd99d14017e592ff2dcd4d49ea1b353f8be1458f5991b15
|
File details
Details for the file seedspark-0.5.1-py3-none-any.whl.
File metadata
- Download URL: seedspark-0.5.1-py3-none-any.whl
- Upload date:
- Size: 21.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.8.2 CPython/3.12.2 Darwin/23.4.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5ffa9ee8496b7dd15df2e780c854b722b981067fbcb08f4bfda7ae2d1a0b9f3e
|
|
| MD5 |
2570e5197aa211175d20871cd1689da1
|
|
| BLAKE2b-256 |
088f4f876739bbdad22f52d97268bdd2b0f4112a36787591ea3bc7d5926f3352
|







