Clustering of data in Seeq

Project description
Contents

seeq-clustering is an add-on for Seeq Workbench, which allows for density based clustering of n-dimensional data. Clustering can be supervised (visual) or unsupervised (density based).
User Guide
seeq-clustering User Guide
Seeq clustering determines cluster structure in data (either by finding regions of high density, or by manual definition) and returns each cluster as a Seeq condition. This can be useful for determining regularly visited regions in parameter space for a set of signals. Why this is important is best understood by analogy. If you want to know how your car's gas mileage is performing over time, a naive way to monitor it is by recording, at the end of every month, your total number of miles driven and total gas used that month. This will give you a measure of how your gas mileage performs over time but is it a good measure of how your car is performing? Gas mileage depends on a variety of factors - outdoor air temperature, number of people in the car, speed etc - so a better measure of how your car is performing is by setting some set of parameters (e.g. 70 degrees, driving between 25 and 30mph with only 1 person in the car) and calculating your gas mileage only when your car is operating in that mode. By examing this gas mileage during known conditions over time, you have a much better measure of how your car is performing.
This is precisely the aim of the clustering addon. In a real process it is more complicated than a car, and it is near impossible to know what set of conditions you should use to specify your monitoring periods (e.g. the 70 degrees, 1 person, from the car example). Clustering helps you with this. It gives you candidate parameter sets - regions in your data where spends a lot of time - so that you can compare how your process is performing in a known, and consistent, parameter space.
When you open the tool, you will be met with two options:

- Visual (Supervised) - allows you to manually define a cluster boundary in 2-dimensional data
- Density (Unsupervised) - density based clustering to find clusters in n-dimensional data
You may have to refresh the worksheet once the addon tool says "SUCCESS". If only the conditions are displayed and not the original signals, please simply refresh the page.
Visual (Supervised)
Visual clustering is only applicable to 2-dimensional data. You simply define a region manually, and seeq-clustering will look for datapoints in that region. See an explanation for how it works


Density (Unsupervised)
See explanation of density based parameters for detailed explanations of each input option for cluster definition.


Whichever mode (Visual or Density) you choose, the form of the clusters returned in Seeq will look similar. Happy clustering!
Explanation of Density Based Parameters
Minimum Cluster Size (MCS) - the minimum number of datapoints which much be including in a cluster for it to be classified as a viable cluster. A larger number will produce fewer clusters, each of which then contains more data. See examples
- There are two ways to specify MCS. Either by specifying a value (e.g. "I want my clusters to contain no fewer that 200 points") or by a percent of the total number of data points (e.g. "I want my clusters to contain no less that 5% of the data"). note percent of datapoints is calculated based on Display Range.
- You may (indeed, likely) not know what the total number of datapoints is in your data, so it is recommended to supply both a
Percent of data (%)and aMin Cluster Points. - If both
Percent of data (%)andMin Cluster Pointsare supplied, the default behavior will be to use the larger of the two values for the MCS, i.e.
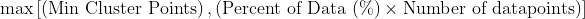
You can override the behavior by checking the Ignore Percent of data? checkbox. Doing so will force mcs = Min Cluster Points
Density Based Examples
To demonstrate how min cluster size impacts the results on the clustering. We will show here two cases (both with Ignore Percent of data? checked)
Min Cluster Points = 200
Min Cluster Points = 100

Errors:
ValueError('unable to determine any cluster structure, try reducing mcs, or data size')No cluster structure was observed. The most likely problem is that the min cluster size (MCS) specified is too large or the dataset is too small. Try reducing MCS or increasing the dataset size (i.e. Display Range) slightly.
How it works (Visual)
When you define a region manually in visual based clustering, the algorithm defines a cluster region as follows:
- Selects the data in the Display Range within that region
- Finds the center of the selected data
- Chooses random directions from the center, traverses along that direction until some threshold (usually 90%) of the selected data is "behind" (along that direction), places a boundary point there.
- It also uses the directionality of the walk to specify a "cone" of points which it classifies as "along the walk direction"
- Does this for many random walk directions to specify a set of contour points, like that shown here:

This allows for a new test point (say, during calculation of Seeq condition) to be compared against the contour points to determine if that new test point is in the cluster or not. Owing to the nature of the random walk, this method is probabilistic and will not capture every member point 100% of the time. This membership definition is only used for visual clustering.
Pseudo code for deterimining cluster membership:
isinCluster(test_point, contour_points)
Find the direction to the test_point from origin of cluster, r'
Find the closest direction in the set of contour_points, r
and corresponding length L
calculate the length along r' to the test_point, L'
if L'<L return true, else return false
Installation
The backend of seeq-clustering requires Python 3.7 or later. seeq-clustering is compatible with Seeq >=R53.
Dependencies
You will need to install the seeq module with the appropriate version that
matches your Seeq server. For more information on the seeq module see seeq at pypi
User Installation Requirements (Seeq Data Lab)
If you want to install seeq-clustering as a Seeq Add-on Tool, you will need:
- Seeq Data Lab (>= R50.5.0, >=R51.1.0, or >=R52.1.0)
seeqmodule whose version matches the Seeq server version- Access (and permissions) to machine running Seeq server
- Knowledge or where external calculation scripts are located on that machine (see User Installation below)
- Enable Add-on Tools in the Seeq server
User Installation
These installation instructions are for Seeq >= 54, for R53 installation, see here. The latest source code of the project can be found here. The code is published as a courtesy to the user, and it does not imply any obligation for support from the publisher. After ensuring that Add-on tools are enabled in the Seeq server, follow the outlined steps below exactly.
- Create a new Seeq Data Lab (SDL) project and open the Terminal window
- Install clustering
pip install seeq-clustering
or manually download the last .whl file from GitHub. Upload this to file to your SDL project, and install it:
pip install <whl_file_name>
- Install the add-on tool
python -m seeq.addons.clustering
and follow the instructions when prompted. ("Username or Access Key" is what you use to log in to Seeq. "Password" is your password for logging into Seeq.)
There are additional Options for the addon installation. These include --users and --groups. These can be used to change permissions for the addon tool. For example to give permission to users me and you one would install the addon with as:
python -m seeq.addons.clustering --users me you
-
Manually download the two files (
Basic.pyandconfig_ext_calc.py) from the external-calc folder. Ignore the filesClustering.pyand_Clustering_config.py. Those are used for earlier Seeq version installations. -
Navigate to the external calculation folder on the machine where Seeq server is running, (typically
'C:/Seeq/plugins/external-calculation/python/user/'or similar) and create a new folder calledClusteringCalc. -
Move the two downloaded files (
Basic.pyandconfig_ext_calc.py) into your newly created/ClusteringCalc/folder. -
In command line on the maching running Seeq (not seeq data lab terminal), navigate to the location of the files you just added (using the example from above):
cd C:/Seeq/plugins/external-calculation/python/user/ClusteringCalc -
Configure the location (on machine running Seeq Server) where clustering models will be stored. To do this, run
python config_ext_calc.py clusteringModelsPath
If you are unable to run python config_ext_calc.py (e.g. if you do not have python installed on the Seeq server host machine), see manual instructions
The default is to store the models in the same location as dir as Clustering.py, i.e. D:/Seeq/plugins/external-calculation/python/user/ in this example. If you wish to store your models elsewhere, and you have the required permissions Assuming you have permissions to access the path, this can be done by running python config_ext_calc.py clusteringModelsPath <yourpathhere>
-
Follow the instructions in external-calc readme (typically located
~/D:/ProgramData/Seeq/data/plugins/external-calculation/python/readme.html) to installhdbscan. Here is an exceprt from the readme, explaining how to do this:Installation of additional libraries can be done by executing the following steps:
Stop Seeq if already started
You may stop seeq by using the Seeq Workbench.
Install the new Python module(s)
Go to the place where Seeq Server is installed (usually C:\Program Files\Seeq Server) and run
seeqprompt.batThis will open a new cmd window and will setup the Python environment for the next commands.
To install your own Python libraries, run in this window (seeqprompt window) the following command:
python -m pip install -U hdbscan -t plugins\lib\python3 ### if you need to install additional packages, e.g. seeq, replace hdbscan with <packagename>where hdbscan is the name of the module we wish to install.
Check and repair permissions
If you run seeq as a service you will need to go to c:\ProgramData\Seeq\data\plugins\lib, select python3 folder, press right mouse, go to Properties , select Security tab, press Advanced, mark checkbox "Replace all child object permissions ..." press Apply, then Yes and then OK.
Start Seeq
Once you've finished these steps the newly installed module may be used in your external-calculation Python scripts.
If you run into an error in installation of hdbscan see note
To confirm that the external calculation has been installed correctly, in Seeq Workbench ensure that create a new formula and search for cluster. You should see the following:

If you run into errors, please open an issue
R53 Installation
These are the installation instructions for R53.
The latest source code of the project can be found here. The code is published as a courtesy to the user, and it does not imply any obligation for support from the publisher. After ensuring that Add-on tools are enabled in the Seeq server, follow the outlined steps below exactly.
- Create a new Seeq Data Lab project and open the Terminal window
- Install clustering
pip install seeq-clustering
or manually download the last .whl file from GitHub. Upload this to file to your SDL project, and install it:
pip install <whl_file_name>
-
Manually download the two files (
Clustering.pyand_Clustering_config.py) from the external-calc folder -
Navigate to the external calculation folder on the machine where Seeq server is running, (typically
'C:/Seeq/plugins/external-calculation/python/user/'or similar). Move the two files you just downloaded (Clustering.pyand_Clustering_config.py) to this folder. -
In command line on the computer or server running Seeq (not seeq data lab terminal), navigate to the external calculation python folder (using the example from above):
cd D:/Seeq/plugins/external-calculation/python/user/ -
Configure the location (on machine running Seeq Server) where clustering models will be stored. Run
python _Clustering_config.py clusteringModelsPathThe default is to store the models in the same location as dir as Clustering.py, i.e.D:/Seeq/plugins/external-calculation/python/user/in this example. If you wish to store your models elsewhere, and you have the required permissions Assuming you have permissions to access the path, this can be done by runningpython _Clustering_config.py clusteringModelsPath <yourpathhere>
If you are unable to run python _Clustering_config.py (e.g. if you do not have python installed on the Seeq server host machine), see manual instructions
-
Follow the instructions in external-calc readme (typically located
~/D:/ProgramData/Seeq/data/plugins/external-calculation/python/readme.html) to installhdbscan. Here is an exceprt from the readme, explaining how to do this:Installation of additional libraries can be done by executing the following steps:
Stop Seeq if already started
You may stop seeq by using the Seeq Workbench.
Install the new Python module(s)
Go to the place where Seeq Server is installed (usually C:\Program Files\Seeq Server) and run
seeqprompt.batThis will open a new cmd window and will setup the Python environment for the next commands.
To install your own Python libraries, run in this window (seeqprompt window) the following command:
python -m pip install hdbscan -t plugins\lib\python3 ### if you need to install additional packages, e.g. seeq, replace hdbscan with <packagename>where hdbscan is the name of the module we wish to install.
Check and repair permissions
If you run seeq as a service you will need to go to c:\ProgramData\Seeq\data\plugins\lib, select python3 folder, press right mouse, go to Properties , select Security tab, press Advanced, mark checkbox "Replace all child object permissions ..." press Apply, then Yes and then OK.
Start Seeq
Once you've finished these steps the newly installed module may be used in your external-calculation Python scripts.
If you run into an error in installation of hdbscan see note
- In any Seeq workbook, retrieve the key of the newly created Clustering.py external calc call. Wait a few moments for it to update, you should see the external-calc script show up (your key will be called
Clustering.py:NUMERIC:<your_unique_checksum>):

-
Update your app to point to your unique checksum. Run
python -m seeq.addons.clustering.config --script_name <yourkeyhere>where<yourkeyhere>is that which you retrieved previously (from a Seeq workbook), e.g., the complete key:Clustering.py:NUMERIC:q2tYWyXR+cw7 -
Install the add-on tool
python -m seeq.addons.clustering
and follow the instructions when prompted.
There are additional Options for the addon installation. These include --users and --groups. These can be used to change permissions for the addon tool. For example to give permission to users me and you one would install the addon with as:
python -m seeq.addons.clustering --users me you
Troubleshooting Install
Manual external-calc Clustering Config
To manually update the cluster model path, open either Basic.py (>R54) Clustering.py (R53) in a text editor. The top two lines should be (or something similar):
#DO NOT CHANGE THE FOLLOWING LINE OR THIS LINE
wkdir = ''
Manually enter the path where you wish to save the clustering models by updating the wkdir variable (yes, this means ignoring the warning in the first line and YES change line 2. To replicate default behavior, updated wkdir to be the same absolute path as the directory which holds Basic.py, e.g.:
wkdir = 'D:/Seeq/plugins/external-calculation/python/user/ClusteringCalc/'
Ensure that you use / in favor of \.
Errors in hdbscan ext-calc install
If you encounter the error
error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/
----------------------------------------
ERROR: Failed building wheel for hdbscan
Failed to build hdbscan
ERROR: Could not build wheels for hdbscan which use PEP 517 and cannot be installed directly
simply follow the link provided in the error (https://visualstudio.microsoft.com/visual-cpp-build-tools/) and download and install Microsoft C++ Build Tools. NOTE it is highly recommended that you ensure Seeq server is stopped before installing Microsoft C++ Build Tools. Follow the download instructions and install the defaults for Microsoft C++ Build Tools:


You will likely then have to close your command prompt, and rerun seeqprompt.bat before attempting to install hdbscan again (see steps)
Troubleshooting
- Error
SPyRuntimeError: Error pushing "[39575A91-37A5-4461-AC8C-7821B54B4237] {Condition} Cluster 0 01/20/2022, 06:13:12": Failed to write item in batch request: Invalid script reference. Expected: fileName.{py|xlsx|xlam|xlsm}[:functionName]:resultDataType:checkSum at 'externalCalculation', line=1, column=1
This occurs from a change to how external calculations function that occurred after Seeq R54. This can be overridden by (i.e., you can force the R54 usage style):
python -m seeq.addons.clustering._external_calc_override --override True
If, for some reason you wish to undo this change:
python -m seeq.addons.clustering._external_calc_override --override False
Development
We welcome new contributors of all experience levels. The Development Guide has detailed information about contributing code, documentation, tests, etc.
Important links
- Official source code repo: https://github.com/seeq12/seeq-clustering
- Issue tracker: https://github.com/seeq12/seeq-clustering/issues
Source code
You can get started by cloning the repository with the command:
git clone git@github.com:seeq12/seeq-clustering.git
Support
Code related issues (e.g. bugs, feature requests) can be created in the issue tracker
Maintainer: Eric Parsonnet
Citation
Please cite this work as:
seeq-clustering
Seeq Corporation, 2021
https://github.com/seeq12/seeq-clustering


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file seeq-clustering-0.2.2.tar.gz.
File metadata
- Download URL: seeq-clustering-0.2.2.tar.gz
- Upload date:
- Size: 41.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.7.1 importlib_metadata/4.8.3 pkginfo/1.8.2 requests/2.23.0 requests-toolbelt/0.9.1 tqdm/4.19.7 CPython/3.6.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e7c7a77033fe53111971e8b4c24fffbdfe91907f786655ff58f8d1f93dfeee26
|
|
| MD5 |
c4a5ef062190b32adc3db26dcf02a5d8
|
|
| BLAKE2b-256 |
9be2192b621fc39a516844440f60c75323f94b07a7e30e03a5eec7a28ab10168
|
File details
Details for the file seeq_clustering-0.2.2-py3-none-any.whl.
File metadata
- Download URL: seeq_clustering-0.2.2-py3-none-any.whl
- Upload date:
- Size: 41.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.7.1 importlib_metadata/4.8.3 pkginfo/1.8.2 requests/2.23.0 requests-toolbelt/0.9.1 tqdm/4.19.7 CPython/3.6.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
34638d9ee2524acfe0e50623bb2e7fd2e1bf6b0b4daaa14faedcf55dcf93bf05
|
|
| MD5 |
f7595da91817e791348ab368828fe3a3
|
|
| BLAKE2b-256 |
f6603ecf008470d80df78a9c3d2b400dd795a0cfedf6cd874f669625965ad51b
|







