SENAITE SYNC



Project description

Data Synchronization tool for SENAITE LIMS
SENAITE.SYNC is a SENAITE add-on to synchronize data amongst SENAITE instances or migrate from a BIKA instance.
Installation
In order to get SENAITE.SYNC running properly both senaite.api and senaite.jsonapi are required in the source and destination instances. However, senaite.sync is only required in the destination instance (where the data is to be imported).
Ready-to-go Installation
With this installation modality, the sources from senaite.sync will be downloaded automatically from Python Package Index (Pypi). If you want the latest code from the source code repository, follow the installation instructions for development listed in the next section.
To install SENAITE.SYNC, if you are already using senaite.lims, you simply have to add senaite.sync into the eggs section of your buildout.cfg:
eggs = ... senaite.sync
senaite.lims already installs senaite.jsonapi and senaite.api for you. However, if you are only using senaite.core you should also add senaite.jsonapi and senaite.api as dependencies. Hence, the eggs section of your buildout.cfg should look like:
eggs = ... senaite.sync senaite.api senaite.jsonapi
For the changes to take effect you need to re-run buildout from your console:
bin/buildout
Note
The above example works for the buildout created by the unified installer. If you are using a custom buildout file for SENAITE, as suggested when installing senaite.health, you should then add the eggs to the eggs list in the [instance] section rather than adding it in the [buildout] section.
Then build it out with your custom config file:
bin/buildout -c <CUSTOM_BUILDOUT>.cfg
Also see this section of the Plone documentation for further details: https://docs.plone.org/4/en/manage/installing/installing_addons.html
Installation for Development
This is the recommended approach how to enable senaite.sync for your development environment. With this approach, you’ll be able to download the latest source code from senaite.sync’s repository and contribute as well.
Use git to fetch senaite.sync source code to your buildout environment:
cd src git clone git://github.com/senaite/senaite.sync.git senaite.sync
Create a new buildout file, <DEV_BUILDOUT>.cfg which extends your existing buildout.cfg – this way you can easily keep development stuff separate from your main buildout file, which you can also use on the production server.
<DEV_BUILDOUT>.cfg should look like:
[buildout]
index = https://pypi.python.org/simple
extends = buildout.cfg
develop +=
src/senaite.sync
[instance]
eggs +=
senaite.sync
If you are using senaite.core and not senaite.lims then <DEV_BUILDOUT>.cfg should look like:
[buildout]
index = https://pypi.python.org/simple
extends = buildout.cfg
develop +=
src/senaite.sync
src/senaite.api
src/senaite.jsonapi
[instance]
eggs +=
senaite.sync
senaite.api
senaite.jsonapi
If you already have a custom buildout file, replace buildout.cfg in extends = buildout.cfg by your custom buildout file. Note that with this approach you do not need to modify the existing buildout file.
Then build it out with this special config file:
bin/buildout -c <DEV_BUILDOUT>.cfg
and buildout will automatically download and install all required dependencies.
Documentation
The following sections give some information about the functional side of Senaite Sync. First we will explain what is the purpose of Sync, what it can be used for. Then, we will talk about its configration and in the end a few examples to make it more understandable.
What does Senaite Sync do?
Senaite Sync (SYNC from now on), can be used for 3 different purposes: Migration/ Back-up of Instances, Track of Instances (one-way synchronization) and Synchronization of multiple instances. In any case, installation and configuration are done similarly. While configuring SYNC, the user must have a clear idea about his/her needs and do the proper configuration. In order to make it easier, let’s define what each of these 3 cases mean clearly.
Migration & Back-Up
This is the most basic use of SYNC. As it is said in its name, it is just to migrate instances which can be thought as copying the DB. The advantage of SYNC Migration over just copying the DB files is, that copying DB files can help you only with having the same instance on the same version of Senaite and its Add-ons. However, SYNC is capable of retrieving data from an older versions of Senaite (even Bika Lims) and build the latest version of Senaite Add-ons respecting that data. It is very helpful to avoid running several upgrade steps to update the instance to the latest version. By running SYNC Updates periodically on the destination instance, changes after migration can be handled and this is can be thought as a quick back-up tool of the source instance.
Tracking Instances
This case is useful when you have more than one instances working independently and you want to gather all the data in one central instance to use for reporting or another purposes later. It is also possible that remote instances share some data but contain their own data as well. In both cases objects can be saved in the central instance with or without Prefixes and easily be distinguished which remote instance they belong to. SYNC Updates are available in this case too.
Synchronization of Multiple Instances
The last, the most useful and the most complex use of SYNC is this one. First of all, make sure you understand previous cases since for Synchronization, Migration and Tracking are required. Basic Synchronization is still easy to configure, but for special cases which we will talk about later, it can require attentive configuration on each instance. Synchronization amongst instances will keep them updated with each other’s changes and they can share any part/amount of data depending on users’ wish.
Configuration Options
As we previously said, configuration is totally about what you want SYNC to do. Let’s have a deep look at each of configuration fields and their meaning. Bear in mind that we are not configuring any Remote yet, this chapter contains information only about the meaning of the configuration options.
Required Configuration
There are some required fields that without them SYNC cannot be used at all. They are basically required fields for Migration. The Image below shows the basic SYNC view where the fields with red dots are mandatory to fill.
Domain Name
It is a unique, representative name for a Remote which should help you to distinguish the Remote among the others easily. E.g: Lab_1, Barna_Lab and etc.
Source URL
URL of the Remote Instance to connect in order to query objects. It should also contain the portal path of the remote instance. E.g: https://192.168.1.5:8080/senaitelims.
Username & Password
User credentials to log in to the remote instance and start an HTTP session.
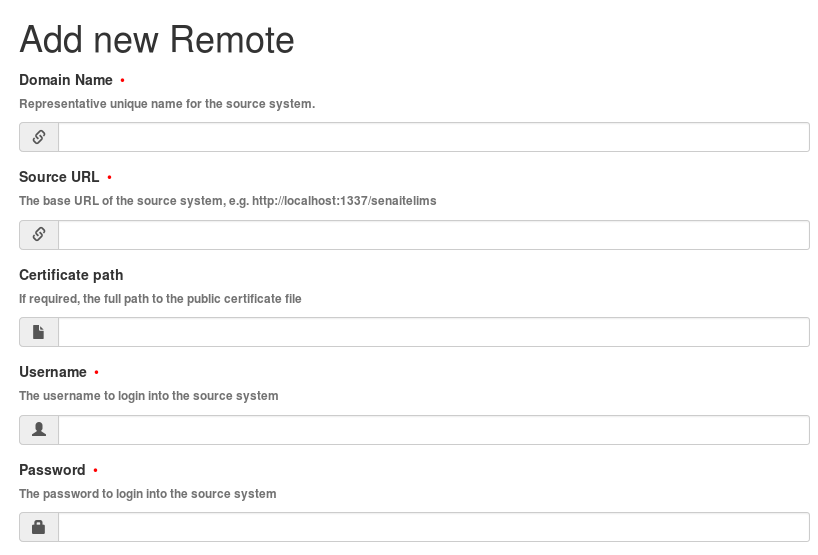
Basic SYNC view.
Optional Configuration
If attention is paid to the image presented above it can be seen that there is one field from the basic SYNC view that is not mandatory. This field is Certificate Path.
Certificate Path
This field should only be filled when synchronization is wanted to be made over HTTPS and the instances that are to be synchronized reside in a local network and are not accessible from the public internet. Why? Because when using HTTPS to connect to another host the identity of this host is validated via signed certificates. When the host is accessible from the public internet, these certificates are signed by authorized entities that are worldwide recognized. However, these authorized entities are not allowed to sign certificates for hosts that are not accessible from the public Internet.
The solution to this is to use self-signed certificates. This certificates are signed by the same host that issues them and not by an authorized entity. The problem that arises when using self-signed certificates is that, since they aren’t signed by an authorized entity, SYNC will not trust them by default.
This why this option exists, and it allows to explicitly tell SYNC to trust a particular certificate.
Advanced Configuration
The following configuration options can be used for Synchronization and special cases. Make sure you understand all of them properly before you start working with SYNC. The Image at the end of the section presents how this set of advanced options looks in SENAITE.
Import Configuration
Import Settings
If this option is enabled the Plone Configuration will be imported.
Import Registry
If this option is selected all the registry records containing the words bika or senaite will be imported. The registry is used by Plone to store some of its configuration data in the form of records, in the most general way.
Import Users
If this option is enabled, then all Plone users from the Remote will be created on the destination instance keeping their roles in the Remote. Remember that you might need them to link with Lab Contacts.
Prefixes Configuration
Remote’s Prefix
Prefixes are very important for Synchronization. When the user defines a Prefix for the Remote, it means, some objects will be created with that Prefix (see Prefixable Content Types) in the beginning of their ID’s.
Local Prefix
This can be thought as the reverse way of Remote’s Prefix. It must be filled only in case that the current instance has been added as a remote in the source system with a prefix. And the prefix used for this instance should be introduced here. It is obligatory for two-side Synchronization.
Content Types Configuration
Full Sync Content Types
This field is kind of a filter for the content types that the user wants to copy/full-synchronize. If it is empty, all content types will be retrieved from the source instance without any filter. But if it is filled as Client, Patient, then only Clients and Patients will be imported in full-sync mood. Bear in mind that dependencies will be imported according to the configuration as well.
Content Types to be Skipped
If filled, entered Content Types will be be imported unless they are required for other objects that are being imported. It can be useful when you want to upgrade your instance and you have some old Calculations which you don’t use and you don’t want to copy and deal with.
Prefixable Content Types
These are the objects which will contain Remote’s Prefix in their IDs. Must be filled if Remote Prefix is not empty. Use case: Let’s say you have an Instance where you want to monitor Analyses from different labs. Then you can one remote for each of the labs on that instance, define prefixes and add Analyses and Analysis Requests to be imported with prefixes. In the end, you will have Analysis Requests and prefixes of the lab they belong to in their ID’s.
Read-Only Content Types
Any content type defined in this field, will be imported to the destination instance. However no one (including Lab Managers and Administrators) will be able to make any change on these objects in the destination instance.
Update-Only Content Types
This field makes sense when two-side Sync is being used. It means, all the objects that originally created on the current instance will be updated according to the changes on the source instance. It takes into account the Local Prefix and it is how the system knows which objects are from this current instance. For example, let’s say we are configuring instance A and there is another instance B which has already imported Samples from instance A in prefixable mode (so all the samples copied from A to B has a prefix A_). When we add Sample to Update-only Content Types, all the Samples with prefix A_ will get updated according to B instance. However, other Samples which have been created on B itself will not be imported to A.
Auto-Sync
You can enable/disable auto Synchronization for each Remote from this field. If not enabled, then updates can be obtained from SYNC view manually.
To enable Auto-Sync, a part from selecting the required checkbox, a clock server should be added to the instance. To do so, a new .cfg file must be extended from the main buildout.cfg file of the instance. The .cfg file must contain the following lines:
[instance]
zope-conf-additional +=
<clock-server>
method /<site_name>/do_auto_sync
period <period_in_seconds>
user <username>
password <password>
host <site_url>
</clock-server>
As an example:
[instance]
zope-conf-additional +=
<clock-server>
method /Plone/do_auto_sync
period 86400
user labman
password labman
host localhost:8080
</clock-server>
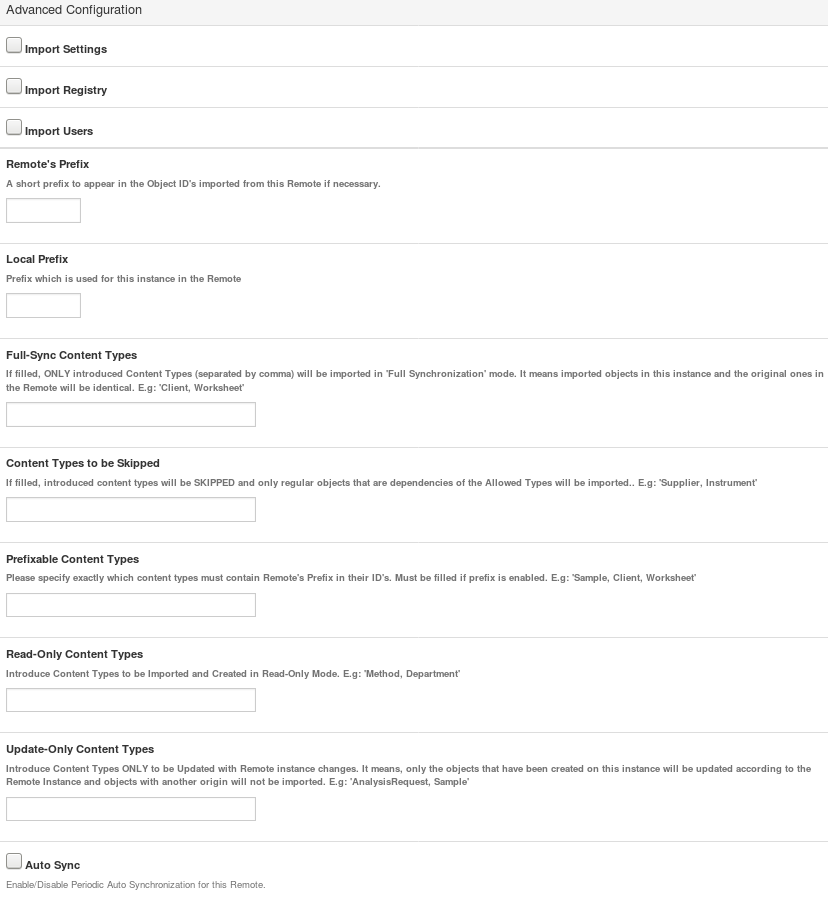
Advanced configuration options.
How does it work?
The whole process can be examined in 3 steps; Fetch, Import and Update. Let’s have a look at them.
Fetch
Fetching data happens right after when you are done with configuration and click Fetch and Save button. During this step, basic information about will-be-imported objects (depending on your configuration), is obtained and saved in order to be used later steps. If you have a DB with ~50 K objects, this step would take an hour approximately. Be patient and keen an eye on logs to see the progress, if you are interested. Once Fetch is finished, you are ready to run the Import process.
Import
Import Process is the step where objects will be created and updated according to the Remote. Thus, it will always take much longer than Fetch Step. To run the Import step, you can click on Import button of corresponding Remote from SYNC View. For a DB with ~50 K objects, Import might take up to 4-5 hours. Be patient and make sure you never have long HTTP/S connection problems.
Update
Update Process is the last step of the SYNC which can be run any time to get changes and keep the destination up-to-date with the source instance. This step doesn’t take too long if you keep the interval short. Bear in mind that if you have some objects that have been modified in the source and destination instances independently from each other, this process will skip and not affect them.
Configure and Synchronize
If you are confident enough that you understand how SYNC works and what you need, then you can start to work with it. In this section we will provide information and instructions on how to work with SYNC Add-on. We will also provide some real examples. Let’s get started!
We assume you have SYNC Add-on installed on your Senaite instance. In this case, and if you have logged into the system as an Administrator or a Manager, you must see SYNC after clicking on the menu icon located in the top right corner. See the image below to visually locate the SYNC link. Click on that and go to SYNC View. If this is your first time adding and you don’t have any remote added previously, you will see only an empty page with Add New Remote button. Click and go to Add New Remote View. This is the page where we can configure the Remote and Start the Synchronization. In order to make it easy-to-understand, we will give examples for each case we talked about in the first section.
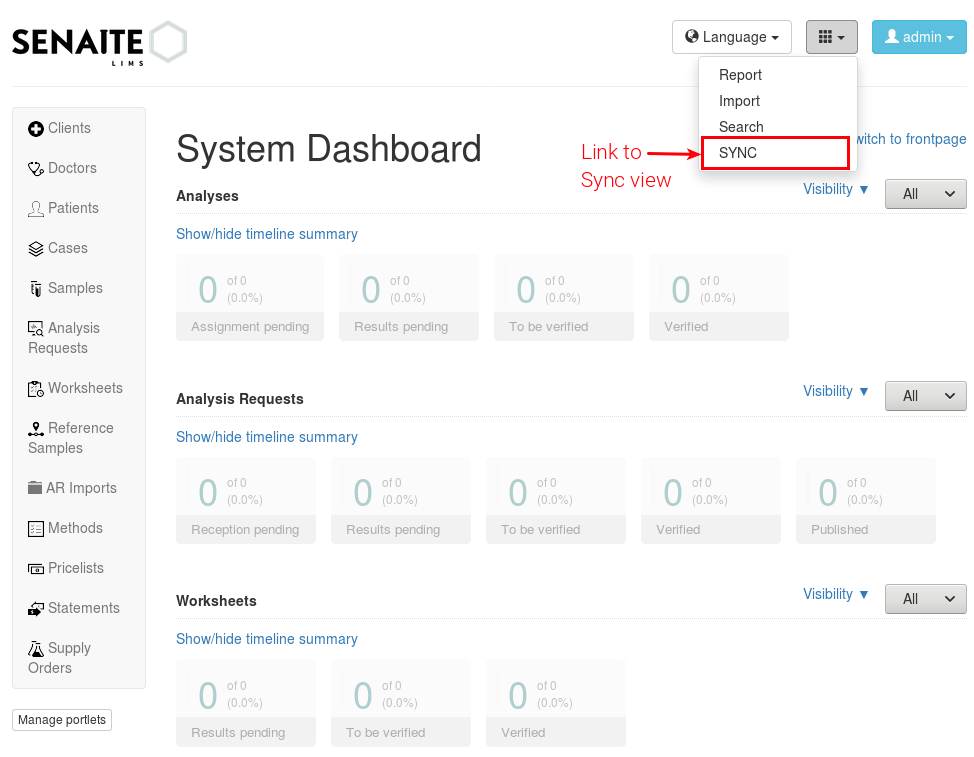
Where to find the link to SYNC.
Configuration for Migration
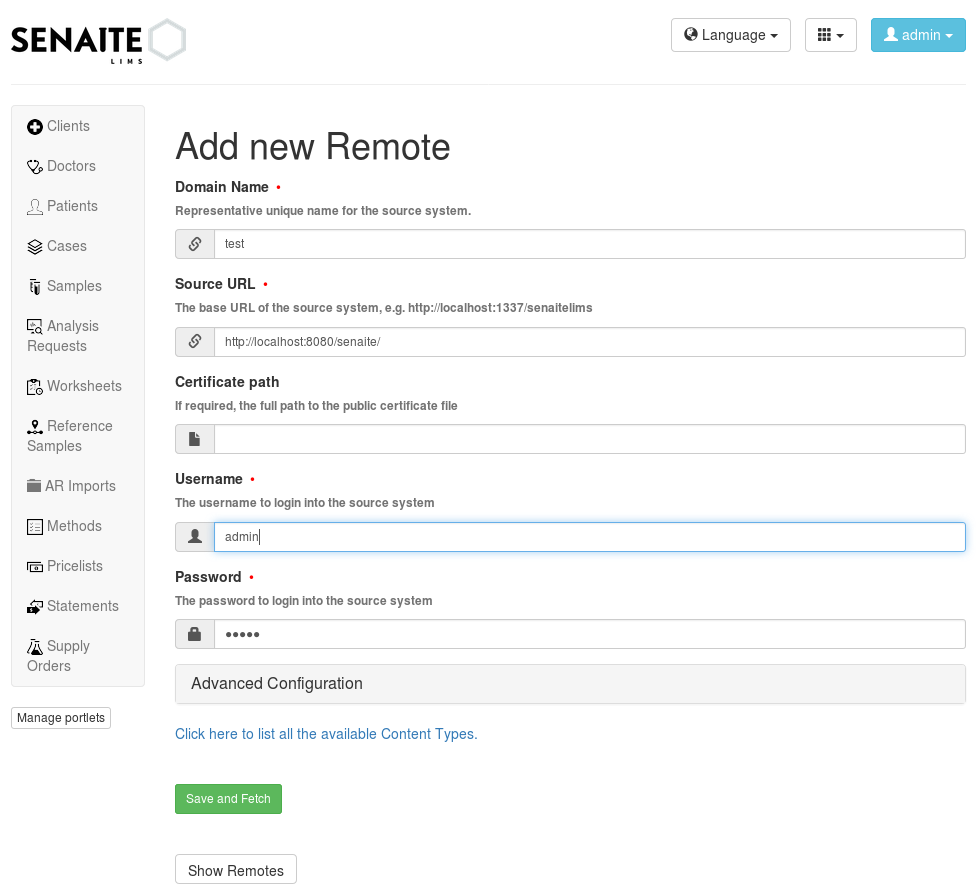
Example configuration for migration.
If your aim is just to migrate and update your source instance as a new one, you only need to fill required fields from the Add View. Since there is no Advanced configuration, SYNC will just connect to the Remote, get all the data and Fetch it as it is in the Remote. The image above presents an example of configuration for migration. If you fill all the fields properly and click on Save and Fetch button, data will be fetched and in the end you will see an informing message like the one presented in the image below. It means you are ready to run Import Step now. Click on Show Remotes button at the bottom of the page and go to Remote Listing View. You will see that now there is some information regarding your Remote Configuration. The last image of this section illustrates what each section of the Remote Table means with a real example.
We will give more information about other parts later but for now you can Run import step by clicking on Import button. After a while, migration will finish and you can enjoy your migrated instance on your new Server!
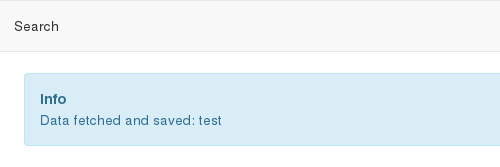
Successfuly fetched test domain message.
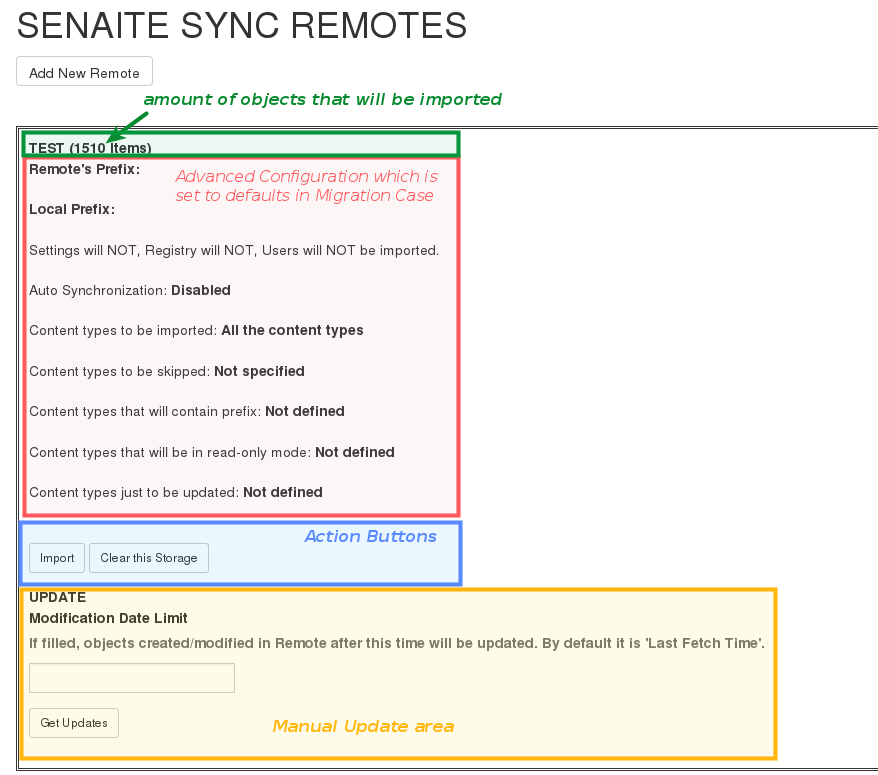
Fetched data for the test domain.
Back-up Instance Configuration (One Way Sync)
In previous example we talked about the case when you want to migrate an instance and then stop using that and start to work with the new, migrated instance. However, it is possible that you have a very important instance with a very important DB, so to feel safer you want to have its back-up version. In order to do so, you obviously have to run the migration for the first time.
Now the important point here is about back-up period. It can be done periodically by SYNC it self, or you can take the back-ups from time to time by yourself. If you want to do copy Updates to your back-up instance manually, you can do it from Manual Update section of the Remote’s table. Just go to that page, run the import step manually by clicking on Get Updates button and that’s it!
If you don’t want to deal with Manual Updates, while configuring the Remote, you can enable Auto Sync option from Advanced Configuration Options and SYNC will do it for you periodically. As you might guess, by this way it is also an example of One Way Synchronization.
Bidirectional Full Synchronization (BFS)
Until now we have seen how to configure your destination instance to migrate or synchronize unidirectionally. So basically, in your source instance you didn’t do anything with SYNC. But when it comes to Bidirectional Sync, it is necessary to deal with SYNC on both instances. In BFS case, your configuration will take place in two steps.
Let’s assume you have 2 instances; Lab A and Lab B. First you have to add Lab B as a Remote on Lab A instance. If you enable Auto-Sync, it means Lab A will always have changes of Lab B. So first step is done! Now imagine you add Lab A as a Remote on Lab B with Auto-Sync option enabled. Now, all the changes from Lab A will be imported to Lab B. Considering that both labs will run SYNC periodically, they will always be up-to-date with each other. Again remember that in the case objects are modified on both instances at the same time period, changes will be skipped.
Full Sync for Multiple Instances
By applying the same logic we used for BFS, we can synchronize even more than 2 instances. In that case, you just have to carefully decide which instances must be Remote for which instances. It could also be done by adding all instances to each other, but it would just confuse you. Instead, you can apply the following logic:
Let’s say you have 4 instances (A, B, C, D) and you want all of them to be Fully Synced. First choose an instance with the highest run-time and think of it as the Master instance. Let’s say A is the Master in our case. Now, you have to add B, C and D as remotes to A and enable Auto-Sync. So, we are sure that A will always have the changes from rest of the instance. Now, go to B and add only A as a remote. What happens now is, A will gather all the changes and since B will get the changes from A, B will have all the changes as well. Apply the last step to C and D instances and that’s it!
If you have too many instances to be Synced, then you might want to have more than one master. It would not cause any problem at all. Just make sure that you add all your remotes on them and on non-master (slave) instances you add at least one of the Masters.
Advanced Sync
So far we saw how to Migrate and do Full Sync which don’t require Advanced Configuration except for Auto-Sync option. Now we will try to go deep to Advanced Configuration and see more complex examples. Before starting with next examples please make sure that you understand what each of Advanced Configuration fields mean.
Example 1
Let’s think of the case where we have 5 Labs (A, B, C, D and M) and we want to collaborate them in this way:
A, B, C and D are labs where samples and analyses are registered and sometimes reported.
A, B, C and D do the same work and share information with M and amongst each other for most of the objects (Department, Method and etc.), except for samples and analyses.
M is the central lab, where samples that have been registered on those labs are analyzed and reported.
If a Sample or an Analysis is updated on M, the information must be sent to the origin lab (and only to origin lab).
f there is an update in origin lab, M should get updated as well.
In this case M can be thought as the Master lab and A, B, C and D as collaborators. It also means we will need 2 types of configuration: one for M and one for the collaborators. Let’s see what the configuration should look like for M:
For each collaborator, a remote should be added on M.
Each Remote should have its unique Prefix .
Since Samples, Analyses and Analysis Requests are not shared data amongst collaborators, they must contain prefixes in order to be distinguishable.
Auto-Sync must be enabled.
And configuration on collaborators:
Only one Remote- for the Master - should be added.
Local Prefix which indicates collaborator’s prefix on Master must be introduced.
Since we do not want to import Samples, Analyses and Analysis Requests, they must be defined as Update-only Types.
Example 2
Let’s think of a more complex use of SYNC. For this example, assume all the criteria from the previous one are given and there is one more requirement:
Some objects such as Methods, Analysis Services and Calculations should be defined and handled only in the central instance. However, the collaborators must have access to them.
In this case, while configuring M, for all collaborator remotes we should define these content types to be skipped. And in the collaborator instances, we will define them inside Read-only Content Types. By this way, collaborators will be able to view and use them, but never to edit nor delete them. In the end, Remote A on Master instance must look as shown in the first image of the two presented below and Remote of Master on collaborator instances as shown on the second one.
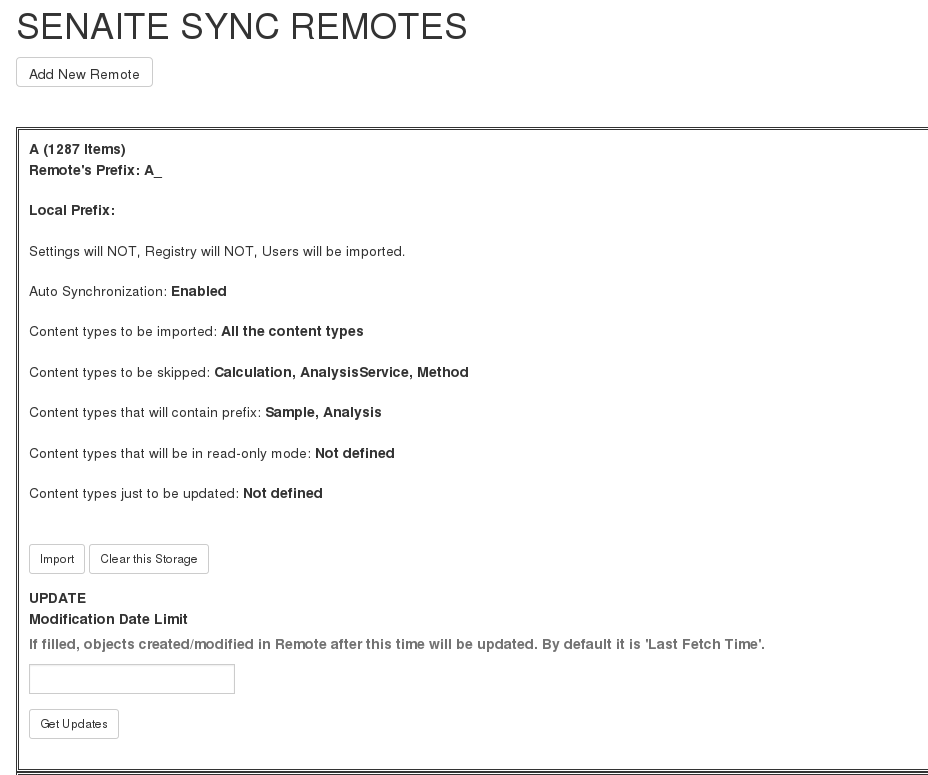
Remote A configuration on the Master instance.
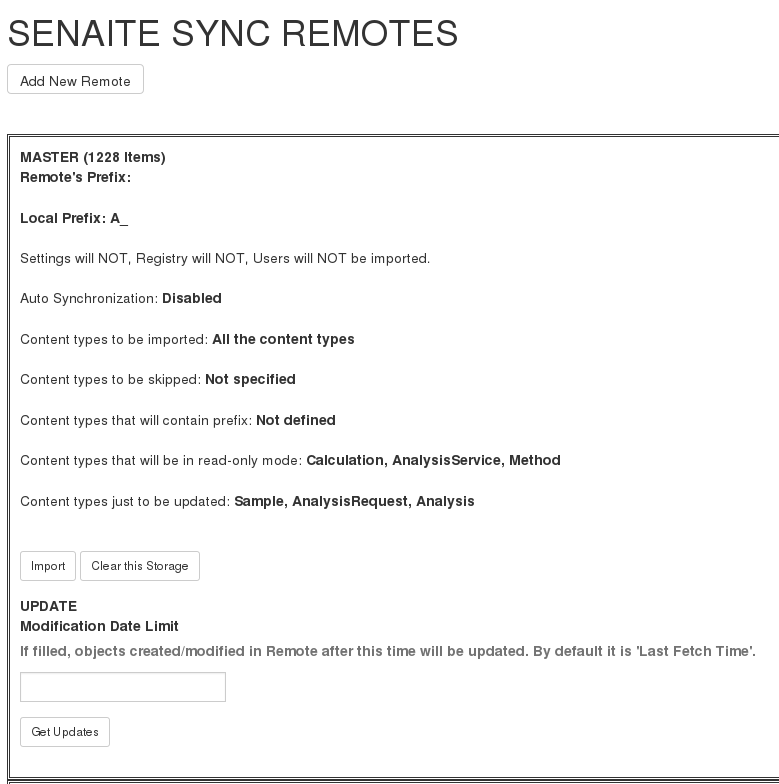
Remote Master instance configuration on collaborator instances.
Contribute
We want contributing to SENAITE.SYNC to be fun, enjoyable, and educational for anyone, and everyone. This project adheres to the Contributor Covenant. By participating, you are expected to uphold this code. Please report unacceptable behavior.
Contributions go far beyond pull requests and commits. Although we love giving you the opportunity to put your stamp on SENAITE.SYNC, we also are thrilled to receive a variety of other contributions. Please, read Contributing to senaite.sync document.
Feedback and support
License
SENAITE.SYNC Copyright (C) 2018 Senaite Foundation
This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License version 2 as published by the Free Software Foundation.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
SENAITE.SYNC uses third party libraries that are distributed under their own terms (see LICENSE-3RD-PARTY.rst)
Changelog
1.0.1 (unreleased)
Added
Changed
Removed
Fixed
#62 Use full url for images in README so that they are shown on PyPi’s project page
Security
1.0.0 (2018-07-16)
Added
#58 Include detailed installation instructions in the README
#58 Include functional documentation in the README
#56 Allow to specify the certificate to be used when connecting to the source instance
#46 Advanced Configuration: Local Prefix and Update only Content Types
#44 Advanced Configuration: ‘Read-Only’ Portal Types
#42 New Advanced Configuration Options
#34 Complement step for migration
#33 Recover step for failed objects in data import
#32 Log the estimated date of end
#32 Log the percentage of completion
#19 Configurable import
#16 Content type filtering
#14 Upgrade step machinery
#12 Settings import
#8 Periodic auto sync
#5 Import review history og objects
#4 Update object’s workflow states
#3 Registry import
Changed
#49 Make interface more user friendly
#53 Update API base url
#43 Querying last modified objects directly from ‘uid_catalog’
Fixed
#57 Handle errors in API resonse when fetching data
#50 Long term infinite loops in Update Step
#48 Auto Synchronization
#45 Error while Fetching Missing Parents
#39 Complement Step does not update all objects
#35 Bug- Complement Step yields all the items
#35 Complement Step yields all the items
#29 User creation when user email is empty
#28 Created users not being added to user groups
#27 Worksheet’s analysis workflow state not being updated properly
#26 Clicking checkboxes’ labels didn’t affect their respective checkboxes
#25 Import error when folderish content type in source has been removed in destination
#24 Sync view wasn’t properly rendered when not using senaite.lims add-on
#22 Creation flag wasn’t being unset for objects under Bika Setup
#21 Attachments were not imported
#6 ProxyField setter fails when proxy object has not been set yet
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file senaite.sync-1.0.1.zip.
File metadata
- Download URL: senaite.sync-1.0.1.zip
- Upload date:
- Size: 86.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.9.1 pkginfo/1.4.1 requests/2.18.4 setuptools/36.2.7 requests-toolbelt/0.8.0 tqdm/4.19.5 CPython/2.7.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
afc5899f6b72bf186d1feab6bd81434ce2782346b3b99e2780f7fdfdb232b2fc
|
|
| MD5 |
b67dd9a7db9350d5bb3c8886d1972b83
|
|
| BLAKE2b-256 |
08bb94ce6b625a3c6fe2d728a68e3558944bd500ddd8bd6c353378dd00a70cf7
|







