Diagnostic profiling of labeled embeddings for classification model complexity guidance.

Project description

separatix
separatix profiles labeled feature spaces before classifier training and
returns transparent, confidence-aware guidance about apparent classification
complexity.
The intended use case includes learned embeddings, but the package is not restricted to embeddings. It also works on raw feature matrices when you want a coarse diagnostic of whether the observed class geometry looks mostly linear, smoothly nonlinear, local or kernel-like, fragmented, bottlenecked, or too unreliable to trust.
separatix does not claim to pick the optimal classifier. It is a pretraining
diagnostic and auditing tool designed to make its reasoning visible.
Installation
pip install separatix
To install the latest development version directly from GitHub:
pip install "git+https://github.com/NiklasMelton/Separatix.git@develop"
Quick start
from separatix import diagnose
recommendation = diagnose(X, y, random_state=0)
print(recommendation)
For a structured audit:
from separatix import diagnose
report = diagnose(X, y, return_report=True, random_state=0)
print(report.recommendation_text)
print(report.decision_path)
print(report.scores)
print(report.to_json())
What It Accepts
- Dense NumPy arrays
- SciPy sparse matrices
- pandas DataFrames and Series when pandas is installed
- Binary and multiclass classification targets
- String or numeric labels treated as categorical class identifiers
Regression, multilabel classification, and multioutput classification are not supported.
What It Returns
By default, diagnose(...) returns a plain-text recommendation. With
return_report=True, it returns a DiagnosticReport that includes:
- the recommendation label
- plain-text recommendation text
- confidence level
- underlying metric groups
- probe-family evidence, including uncertainty-aware family comparisons
- normalized summary scores
- a visible decision path
- warnings and skipped diagnostics
- sampling and densification events
- preprocessing and runtime metadata
The report is JSON-serializable through report.to_dict() and report.to_json().
Recommendation Categories
linear_likely_sufficientsmooth_nonlinear_recommendedkernel_or_local_recommendedhigh_capacity_or_partitioning_recommendedfeature_or_label_bottleneck_likelyinsufficient_data_or_unreliable_geometryinconclusive
These categories are intentionally coarse. They describe the apparent geometry and difficulty of the labeled feature space, not a guaranteed best model choice.
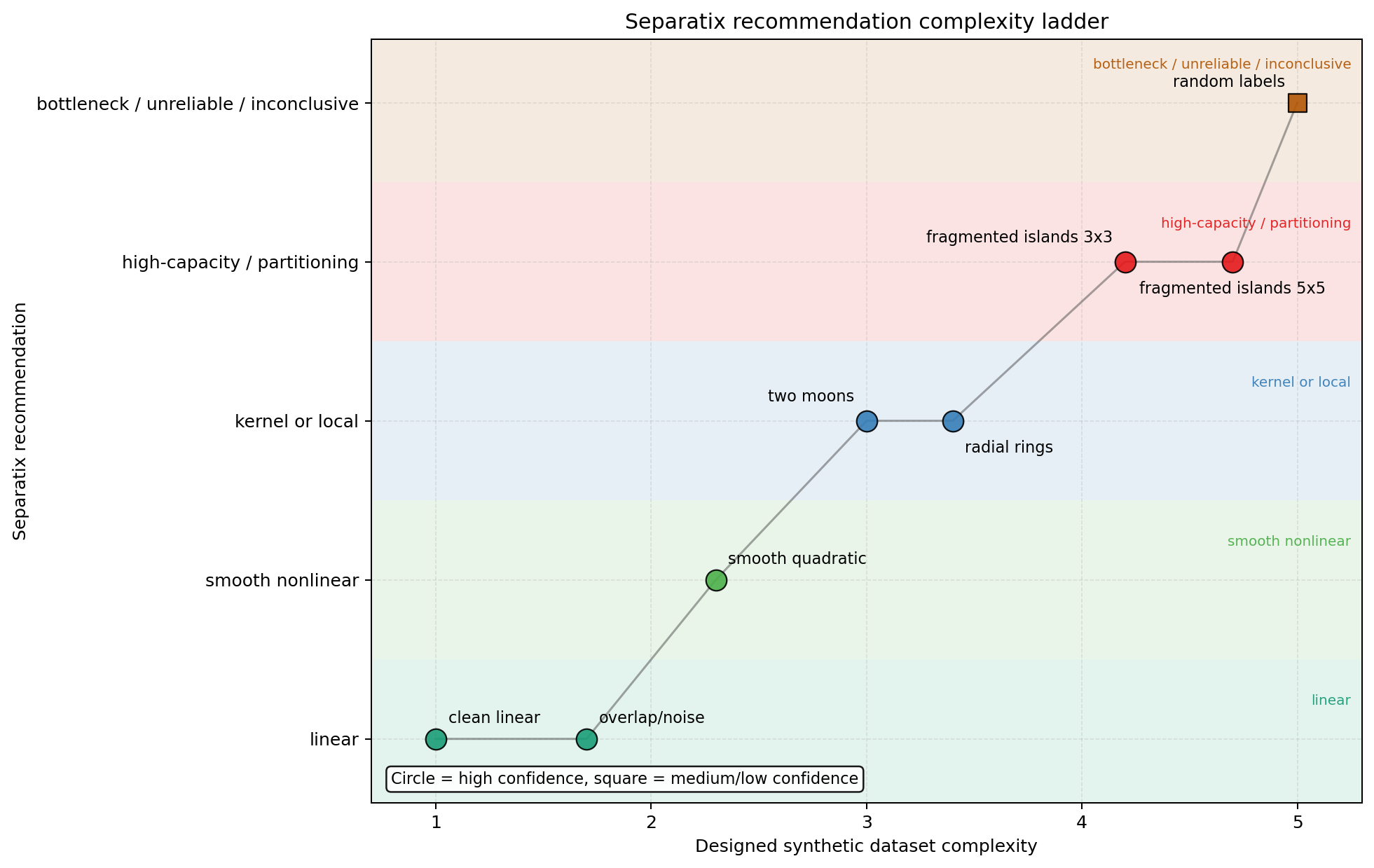
The synthetic recommendation ladder below shows how separatix responds as the
designed dataset geometry moves from simple linear structure toward smoother
nonlinearity, local or kernel-like structure, fragmented boundaries, and
finally weak-signal or random-label bottlenecks. The x-axis is the intended
dataset complexity, while the y-axis is the coarse recommendation level
reported by separatix.
Decision Pipeline
The recommendation is produced by a fixed, inspectable pipeline:
- Validate inputs and encode labels.
- Audit class counts, imbalance, sparsity, and basic dataset conditions.
- Compute geometry, neighborhood, boundary, fragmentation, and optional topology diagnostics.
- Run simple probe models and compare them to a dummy baseline.
- Build probe-family evidence with uncertainty estimates for
linear,smooth_nonlinear, andlocal_kernel. - Apply a 95% signal-vs-dummy gate before making any model-family recommendation.
- Use conservative escalation: keep the simpler family unless a more complex family has a clear uncertainty-adjusted advantage.
- Render both a plain-language summary and a structured report, including
raw_best_familyandrecommended_familywhen a report is requested.
The full rationale and decision rules are documented in docs/decision_pipeline.md.
Sparse Inputs And Memory Behavior
Sparse matrices are accepted directly. Diagnostics that need dense data use a
shared densification policy rather than a separate dense-only code path. When a
step would require densification, separatix can fail, skip, or warn and
subsample before densifying, depending on configuration. These events are
recorded in the report.
Examples
- examples/basic_breast_cancer.py
- examples/linear_hyperplane_visual.py
- examples/curvilinear_boundary_visual.py
- examples/high_dimensional_linear_hyperplane.py
- examples/high_dimensional_curvilinear_hyperplane.py
- examples/moons_vs_linear.py
- examples/circles_kernel_signal.py
- examples/recommendation_complexity_ladder.py
- examples/multiclass_wine.py
- examples/sparse_text_like_embeddings.py
Related Work
This package is not an implementation of a published dataset-complexity procedure, but the project is adjacent to and inspired by prior work on classification complexity and data geometry. In particular, would like to acknowledge:
- Ho and Basu, "Complexity Measures of Supervised Classification Problems" (PDF)
- Lorena, Garcia, Lehmann, Souto, and Ho, "How Complex Is Your Classification Problem? A Survey on Measuring Classification Complexity" (DOI, PDF)
We do not follow those procedures directly, but they are relevant background for why geometry-aware pretraining diagnostics are useful.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file separatix-0.1.0a2.tar.gz.
File metadata
- Download URL: separatix-0.1.0a2.tar.gz
- Upload date:
- Size: 28.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
68a386cdc2e4e2ac6d6a1311fd06747b6c3891d31995b084403bc1eb6cf55f56
|
|
| MD5 |
2de11aca36302d8b07e9484f55a4ab5c
|
|
| BLAKE2b-256 |
e514803f4e1ea8d8b06d14000045e37c832df1d645f27f49356f344504c8c97f
|
Provenance
The following attestation bundles were made for separatix-0.1.0a2.tar.gz:
Publisher:
pypi-publish.yml on NiklasMelton/Separatix
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
separatix-0.1.0a2.tar.gz -
Subject digest:
68a386cdc2e4e2ac6d6a1311fd06747b6c3891d31995b084403bc1eb6cf55f56 - Sigstore transparency entry: 1793470153
- Sigstore integration time:
-
Permalink:
NiklasMelton/Separatix@c159a8f1cf73f71a6b98c9f0f635451ee8bb766f -
Branch / Tag:
refs/tags/0.1.0a2 - Owner: https://github.com/NiklasMelton
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
pypi-publish.yml@c159a8f1cf73f71a6b98c9f0f635451ee8bb766f -
Trigger Event:
release
-
Statement type:
File details
Details for the file separatix-0.1.0a2-py3-none-any.whl.
File metadata
- Download URL: separatix-0.1.0a2-py3-none-any.whl
- Upload date:
- Size: 36.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ba57a665b69cbe8e8a59b574e8d0a4f3dcf37f38f940f5704567928811e4f3c9
|
|
| MD5 |
a9bd9551409d5e84a132e314dd149288
|
|
| BLAKE2b-256 |
3f4cee9dd1e5a369ee1431c5c445c4612c06cbb89f4f1ff270ff07f374f0cfaa
|
Provenance
The following attestation bundles were made for separatix-0.1.0a2-py3-none-any.whl:
Publisher:
pypi-publish.yml on NiklasMelton/Separatix
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
separatix-0.1.0a2-py3-none-any.whl -
Subject digest:
ba57a665b69cbe8e8a59b574e8d0a4f3dcf37f38f940f5704567928811e4f3c9 - Sigstore transparency entry: 1793470854
- Sigstore integration time:
-
Permalink:
NiklasMelton/Separatix@c159a8f1cf73f71a6b98c9f0f635451ee8bb766f -
Branch / Tag:
refs/tags/0.1.0a2 - Owner: https://github.com/NiklasMelton
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
pypi-publish.yml@c159a8f1cf73f71a6b98c9f0f635451ee8bb766f -
Trigger Event:
release
-
Statement type:







