Automation framework for the scientific method in R&D
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
Usage |
|
Release |
|
Development |
|
Miscellaneous |
|












TL;DR
What is SIERRA? See What is SIERRA?
Why should you use SIERRA? See Why SIERRA?
To install SIERRA (requires python 3.9+):
pip3 install sierra-research
SIERRA requires a recent OSX (tested with 13+) or Linux (tested with ubuntu 20.04+) and python >= 3.9. For more details, including the requirements for project code, see the SIERRA requirements.
To get started using SIERRA, see getting started.
Want to cite SIERRA? See Citing.
Have an issue using SIERRA? See Troubleshooting.
What is SIERRA?
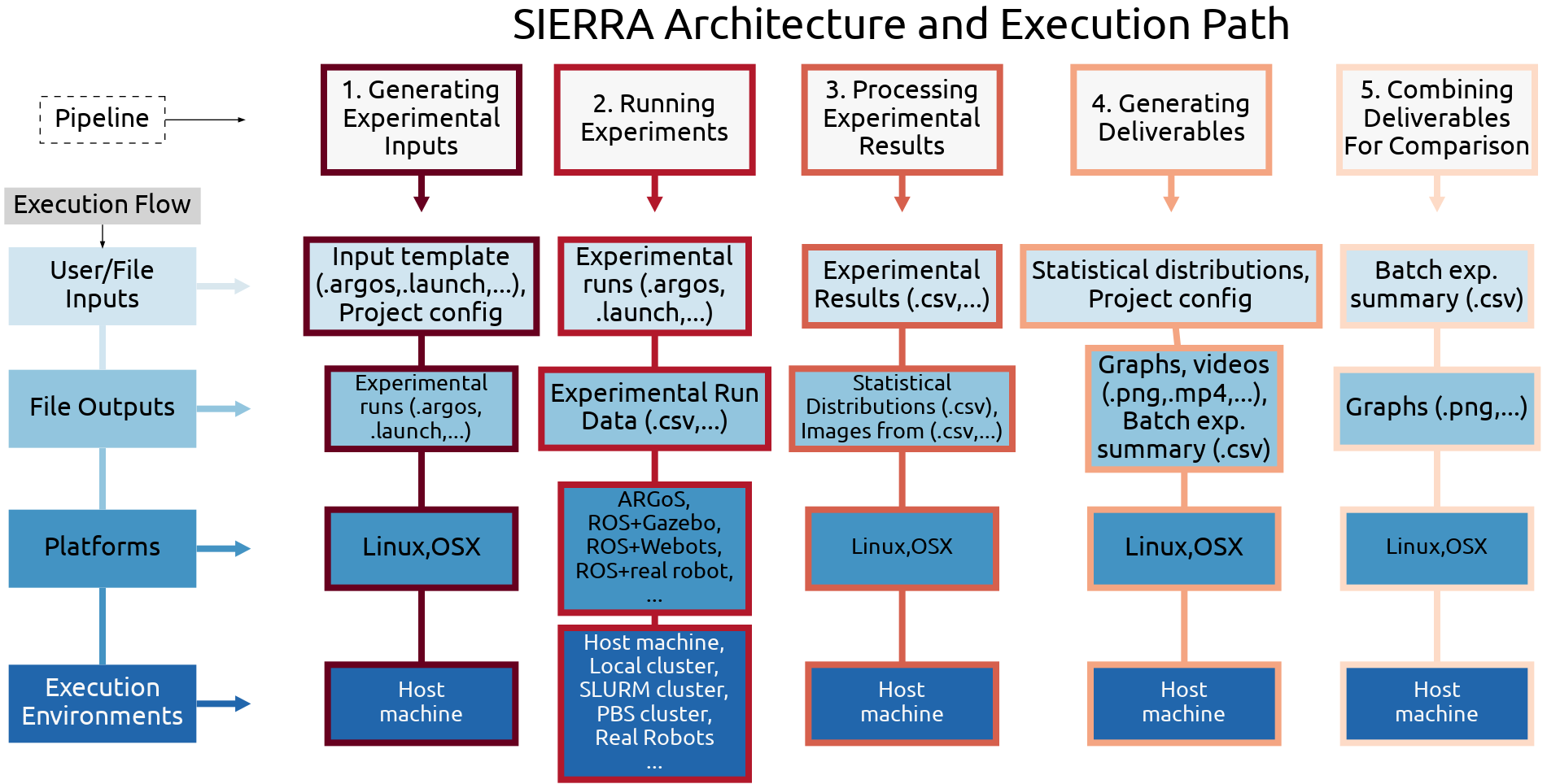
SIERRA architecture, organized by pipeline stage, left to right. High-level inputs/outputs and active plugins and shown for each stage. “…” indicates areas of further extensibility and customization via new plugins. “Host machine” indicates the machine SIERRA was invoked on. The active plugins in each stage and what they cumulatively enable are highlighted in red.
SIERRA is a command line tool and plugin framework for:
Automating R&D, providing faculties for seamless experiment generation, execution, and results processing.
Accelerating R&D cycles by allowing researchers/developers to focus on the “science” aspects: developing new things and designing experiments to test them, rather than the engineering aspects (writing scripts, configuring environments, etc.).
Improving the reproducibility of scientific research, particularly in AI.
Why SIERRA?
It changes the paradigm of the engineering tasks researchers must perform from manual and procedural to declarative and automated. That is, from:
"I need to perform these steps to run the experiment, process the data and generate the graphs I want."
to:
"Here is the environment and simulator/platforms(s) I want to use, the deliverables I want to generate, and the data I want to appear on them for my research query--GO!"
Essentially, SIERRA handles the “engineering” parts of research on the backend, acting as a compiler of sorts, turning research queries into executable objects, running the “compiled” experiments, and processing results into visualizations or other deliverables.
It has deep support for arbitrary parameter sweeps: numeric, categorical, or any combination thereof.
It supports a wide range of execution engines/environments, and experiment input/output formats via plugins. SIERRA supports mix-and-match between all plugin types, subject to restrictions within the plugins themselves. This is and makes it very easy to run experiments on different hardware, targeting different simulators, in different execution environments, generating different outputs, etc., all with little to no configuration changes by the user.
SIERRA maximizes reusability of code and configuration; it is designed so that no copy-pasting is ever needed, improving code quality with no additional effort from users.
SIERRA has a rich model framework allowing you to run arbitrary models, generate data, and plot it on the same figure as empirical results–automatically.
Why use SIERRA over something like prefect, dagster, or airflow ? Briefly, because SIERRA provides a common pipeline which is tested and can accommodate most use cases; SIERRA is not as feature complete as these other frameworks, though. For most use cases (but not all), that delta doesn’t matter. In addition, with the other frameworks, you have to create your own pipelines from scratch.
Not sure if SIERRA makes sense for you? Check out some of the use cases for which SIERRA was designed. If aspects of any sound familiar, then there is a strong chance SIERRA could help you! See the SIERRA docs to get started.
Citing
If you use SIERRA and have found it helpful, please cite the following paper:
@inproceedings{Harwell2022a-SIERRA,
author = {Harwell, John and Lowmanstone, London and Gini, Maria},
title = {SIERRA: A Modular Framework for Research Automation},
year = {2022},
isbn = {9781450392136},
publisher = {International Foundation for Autonomous Agents and Multiagent Systems},
booktitle = {Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems},
pages = {1905–1907}
}
You can also cite the specific version of SIERRA used with the DOI at the top of this page, to help facilitate reproducibility.
Troubleshooting
If you have problems using SIERRA, please open an issue or post in the Github forum and I’ll be happy to help you work through it.
Contributing
I welcome all types of contributions, no matter how large or how small, and if you have an idea, I’m happy to talk about it at any point :-). See the contributing guide for the general procedure.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file sierra_research-1.5.8.tar.gz.
File metadata
- Download URL: sierra_research-1.5.8.tar.gz
- Upload date:
- Size: 1.2 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4f96ecff6a5e07a9c9e0fda87ad4288946197ba869cded578795d977bde2b5d5
|
|
| MD5 |
71092b0d8b8cfdcadadcf619adb155b5
|
|
| BLAKE2b-256 |
0b843c9d64e6fb78497c53c474f064d6e22e1592d712301c4ef32f92e99c484b
|
Provenance
The following attestation bundles were made for sierra_research-1.5.8.tar.gz:
Publisher:
publish.yml on jharwell/sierra
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
sierra_research-1.5.8.tar.gz -
Subject digest:
4f96ecff6a5e07a9c9e0fda87ad4288946197ba869cded578795d977bde2b5d5 - Sigstore transparency entry: 831752714
- Sigstore integration time:
-
Permalink:
jharwell/sierra@1917dbaca9094559e32807d02c5676c924953107 -
Branch / Tag:
refs/tags/1.5.8 - Owner: https://github.com/jharwell
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@1917dbaca9094559e32807d02c5676c924953107 -
Trigger Event:
release
-
Statement type:
File details
Details for the file sierra_research-1.5.8-py3-none-any.whl.
File metadata
- Download URL: sierra_research-1.5.8-py3-none-any.whl
- Upload date:
- Size: 290.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
363e221e8f8ed600bf5db655b798f6e86af748ec1f416adc5361da724f6d5075
|
|
| MD5 |
a8e2ab981655736a727e94772371bdbf
|
|
| BLAKE2b-256 |
49a5fa7491263ad67e31d177105383a7a06421b0306f31cece011bdf27770b4a
|
Provenance
The following attestation bundles were made for sierra_research-1.5.8-py3-none-any.whl:
Publisher:
publish.yml on jharwell/sierra
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
sierra_research-1.5.8-py3-none-any.whl -
Subject digest:
363e221e8f8ed600bf5db655b798f6e86af748ec1f416adc5361da724f6d5075 - Sigstore transparency entry: 831752722
- Sigstore integration time:
-
Permalink:
jharwell/sierra@1917dbaca9094559e32807d02c5676c924953107 -
Branch / Tag:
refs/tags/1.5.8 - Owner: https://github.com/jharwell
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@1917dbaca9094559e32807d02c5676c924953107 -
Trigger Event:
release
-
Statement type:







