Signal Processing Algorithms from MongoDB

Project description
Signal Processing Algorithms
A suite of algorithms implementing Energy Statistics, E-Divisive with Means and Generalized ESD Test for Outliers in python. See The Use of Change Point Detection to Identify Software Performance Regressions in a Continuous Integration System and Creating a Virtuous Cycle in Performance Testing at MongoDB for background on the development and use of this library.
Getting Started - Users
pip install signal-processing-algorithms
Getting Started - Developers
Getting the code:
$ git clone git@github.com:mongodb/signal-processing-algorithms.git
$ cd signal-processing-algorithms
Installation
$ pip install poetry
$ poetry install
Testing/linting:
$ poetry run pytest
Running the slow tests:
$ poetry run pytest --runslow
Some of the larger tests can take a significant amount of time (more than 2 hours).
Energy statistics
Energy Statistics is the statistical concept of Energy Distance and can be used to measure how similar/different two distributions are.
For statistical samples from two random variables X and Y: x1, x2, ..., xn and y1, y2, ..., yn
E-Statistic is defined as:
where,
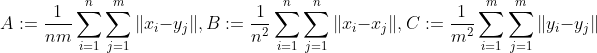
T-statistic is defined as:
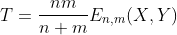
E-coefficient of inhomogeneity is defined as:
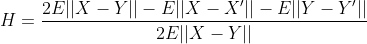
from signal_processing_algorithms.energy_statistics import energy_statistics
from some_module import series1, series2
# To get Energy Statistics of the distributions.
es = energy_statistics.get_energy_statistics(series1, series2)
# To get Energy Statistics and permutation test results of the distributions.
es_with_probabilities = energy_statistics.get_energy_statistics_and_probabilities(series1, series2, permutations=100)
Intro to E-Divisive
Detecting distributional changes in a series of numerical values can be surprisingly difficult. Simple systems based on thresholds or mean values can be yield false positives due to outliers in the data, and will fail to detect changes in the noise profile of the series you are analyzing.
One robust way of detecting many of the changes missed by other approaches is to use E-Divisive with Means, an energy statistic based approach that compares the expected distance (Euclidean norm) between samples of two portions of the series with the expected distance between samples within those portions.
That is to say, assuming that the two portions can each be modeled as i.i.d. samples drawn from distinct random variables (X for the first portion, Y for the second portion), you would expect the E-statistic to be non-zero if there is a difference between the two portions:
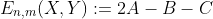
One can prove that 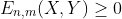
converges in distribution to a quadratic form of independent standard normal random variables. Under the alternative hypothesis T tends to infinity. This makes it possible to construct a consistent statistical test, the energy test for equal distributions
Thus for a series Z of length L,
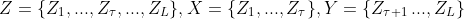
we find the most likely change point by solving the following for τ such that it has the maximum T statistic value.
Multiple Change Points
The algorithm for finding multiple change points is also simple.
Assuming you have some k known change points:
- Partition the series into segments between/around these change points.
- Find the maximum value of our divergence metric within each partition.
- Take the maximum of the maxima we have just found --> this is our k+1th change point.
- Return to step 1 and continue until reaching your stopping criterion.
Stopping Criterion
In this package we have implemented a permutation based test as a stopping criterion:
After step 3 of the multiple change point procedure above, randomly permute all of the data within each cluster, and find the most likely change point for this permuted data using the procedure laid out above.
After performing this operation z times, count the number of permuted change points z' that have higher divergence metrics than the change point you calculated with un-permuted data. The significance level of your change point is thus z'/(z+1).
We allow users to configure a permutation tester with pvalue
and permutations representing the significance cutoff for algorithm termination and permutations to perform for each
test, respectively.
Example
from signal_processing_algorithms.energy_statistics import energy_statistics
from some_module import series
change_points = energy_statistics.e_divisive(series, pvalue=0.01, permutations=100)
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file signal_processing_algorithms-2.1.6.tar.gz.
File metadata
- Download URL: signal_processing_algorithms-2.1.6.tar.gz
- Upload date:
- Size: 19.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.3.2 CPython/3.8.20 Linux/6.5.0-1025-azure
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6232d61f118002f9993ca2c6575acde7029d1328ac418297b4fc388dec5c30aa
|
|
| MD5 |
46f38f444a15196052b9cac34d49a342
|
|
| BLAKE2b-256 |
9e46d3ea4d07e316645ae30e2db63249c26416c6ec13bb614fa2ae0d60f7d7fe
|
File details
Details for the file signal_processing_algorithms-2.1.6-cp38-cp38-manylinux_2_17_x86_64.manylinux_2_5_x86_64.manylinux1_x86_64.manylinux2014_x86_64.whl.
File metadata
- Download URL: signal_processing_algorithms-2.1.6-cp38-cp38-manylinux_2_17_x86_64.manylinux_2_5_x86_64.manylinux1_x86_64.manylinux2014_x86_64.whl
- Upload date:
- Size: 23.9 kB
- Tags: CPython 3.8, manylinux: glibc 2.17+ x86-64, manylinux: glibc 2.5+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.3.2 CPython/3.8.20 Linux/6.5.0-1025-azure
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b707a85b32386031b581880446c245e45bb41db4b5abf57748b2c7e0cc0a267a
|
|
| MD5 |
96ff2e5546771005210e9d8b1b93891d
|
|
| BLAKE2b-256 |
1f9fc6fc4e88eb616ba0c7dc111a4f3a5da1a98defb949b8c9c148b80399f6fd
|







