Chinese text processing, representation, and visualization.

Project description
SimpleChinese




Chinese text processing, representation, and visualization.
Free software: MIT license
Documentation: https://simplechinese.readthedocs.io.
Features
Read the data from a csv file.
df = pd.read_csv("test.csv")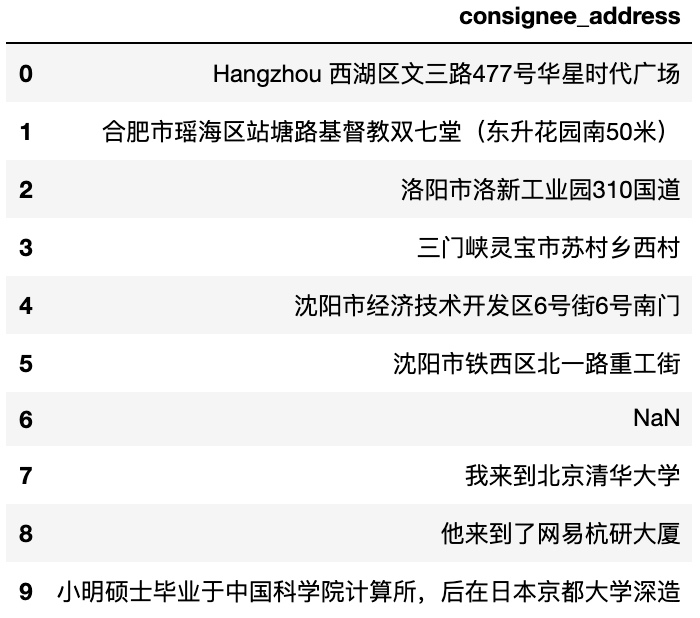
Clean the data.
sc.clean(df)
The clean function does the following:
fillna(): Fill the N/As in a pandas.DataFrame with an empty string.
toLower(): Transform alphabets to their lowercases.
remove_punctuations(): Remove all the punctuations in a string or a pandas.DataFrame.
remove_space(): Remove all the spaces in a string or a pandas.DataFrame.
Extract words from the data
sc.extract_words(sc.clean(df))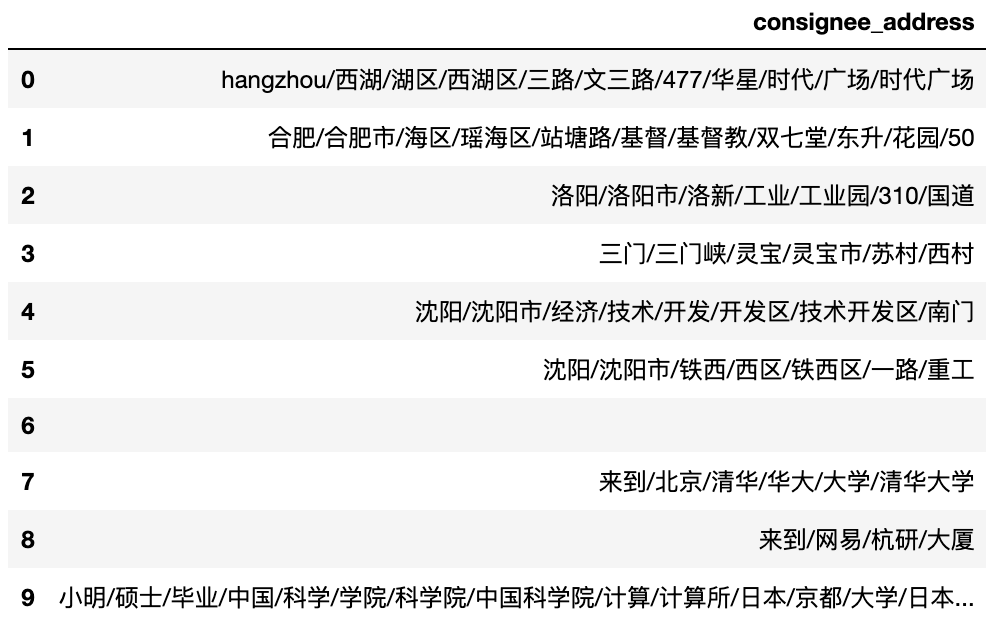
Vectorization
sc.pca(sc.tfidf(sc.clean(df).iloc[:,0]))
Word cloud
sc.wordcloud(sc.clean(df).iloc[:,0], font_path="yahei.ttc")
Credits
This package was created with Cookiecutter and the audreyr/cookiecutter-pypackage project template.
History
0.1.0 (2020-07-10)
First release on PyPI.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file simplechinese-0.1.0.tar.gz.
File metadata
- Download URL: simplechinese-0.1.0.tar.gz
- Upload date:
- Size: 13.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/45.1.0.post20200127 requests-toolbelt/0.9.1 tqdm/4.42.0 CPython/3.7.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6ed60d5cdc66e8d151167a13fd0e7aace19edebc48d7183bfddfb548b1cc3aca
|
|
| MD5 |
7bd57294213a726234447896878238c2
|
|
| BLAKE2b-256 |
f0ef7b0580d485a556a5c6549e22abfa5f053305dcc137d613b326fdfa13e41a
|







