Download sites with public proxies - threading

Project description
$pip install site2hdd
from site2hdd import download_url_list,get_proxies,download_webpage
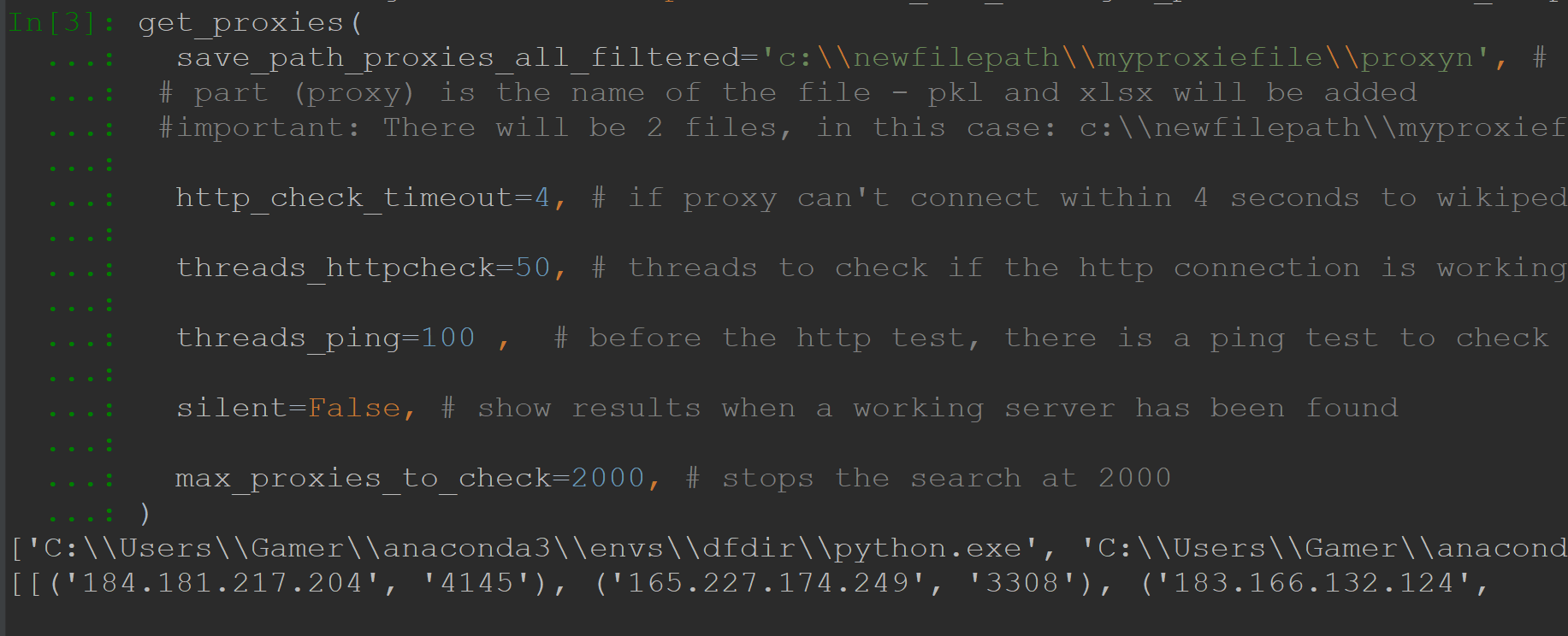
xlsxfile,pklfile = get_proxies(
save_path_proxies_all_filtered='c:\\newfilepath\\myproxiefile\\proxy', # path doesn't have to exist, it will be created, last
# part (proxy) is the name of the file - pkl and xlsx will be added
# important: There will be 2 files, in this case: c:\\newfilepath\\myproxiefile\\proxy.pkl and c:\\newfilepath\\myproxiefile\\proxy.xlsx
http_check_timeout=4, # if proxy can't connect within 4 seconds to wikipedia, it is invalid
threads_httpcheck=50, # threads to check if the http connection is working
threads_ping=100 , # before the http test, there is a ping test to check if the server exists
silent=False, # show results when a working server has been found
max_proxies_to_check=2000, # stops the search at 2000
)
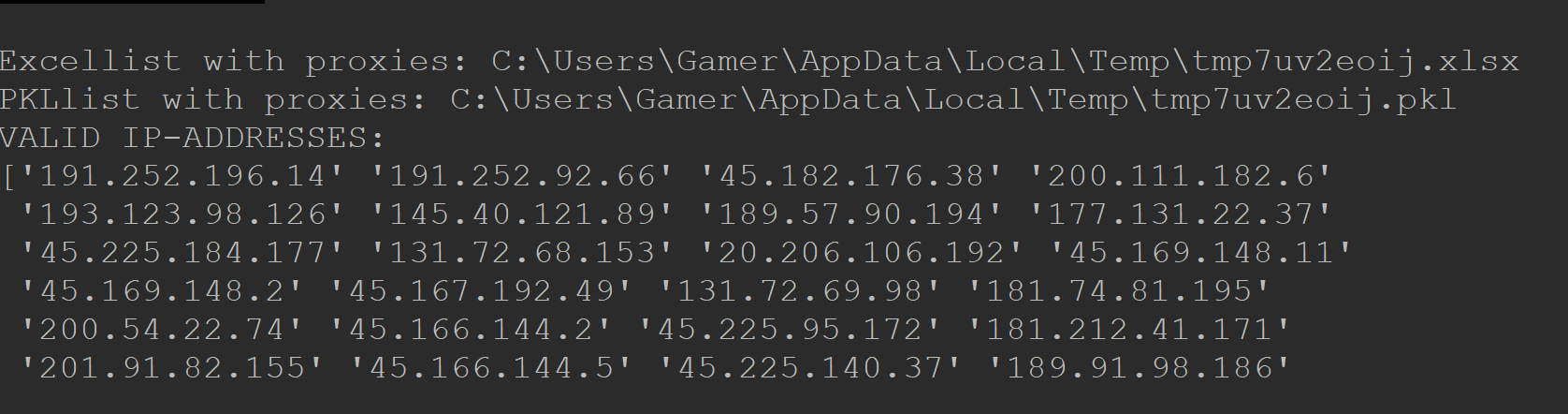
Downloading lists of free proxy servers
Checking if the ip exists
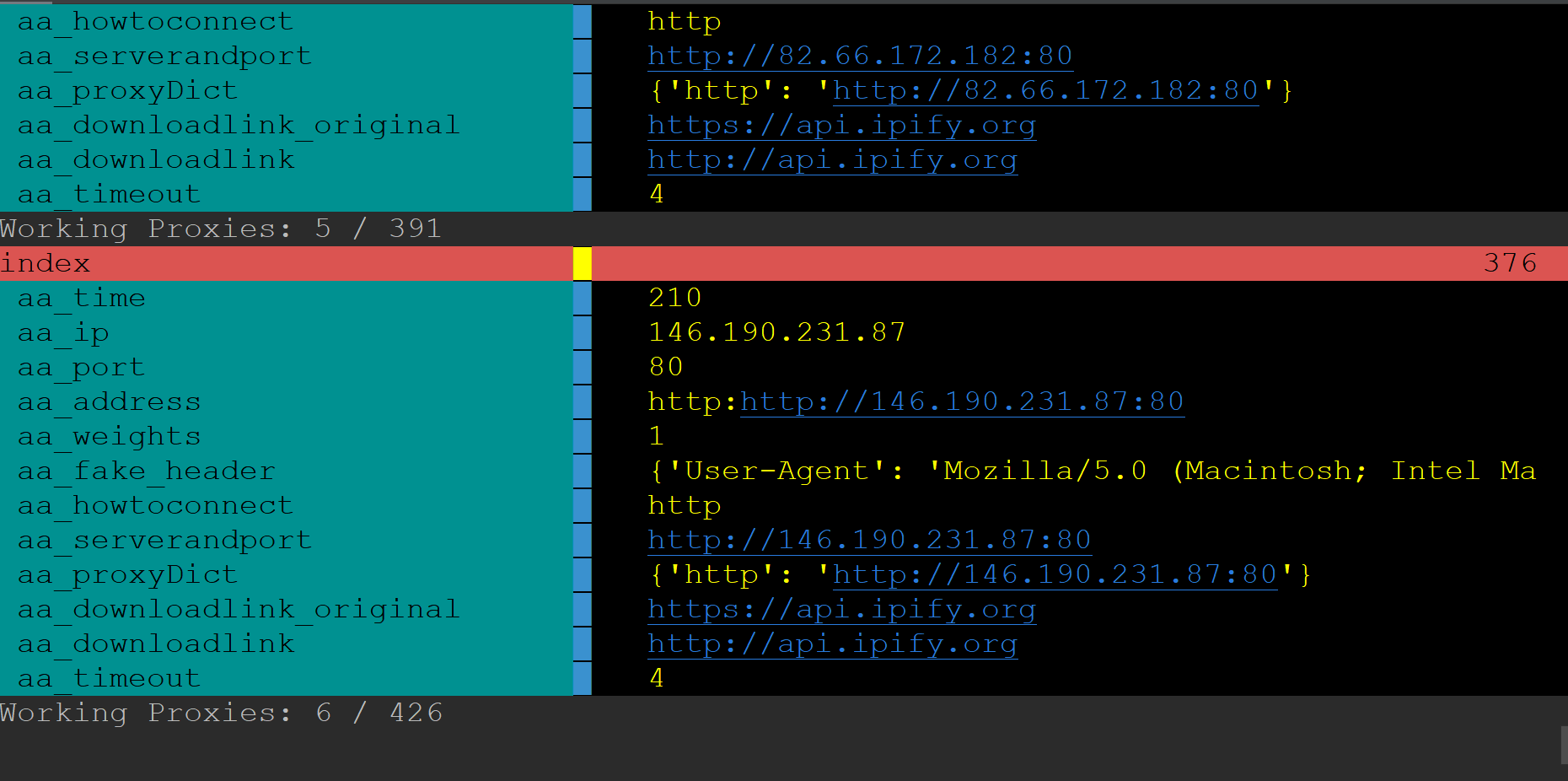
Checking if http works and own IP is hidden
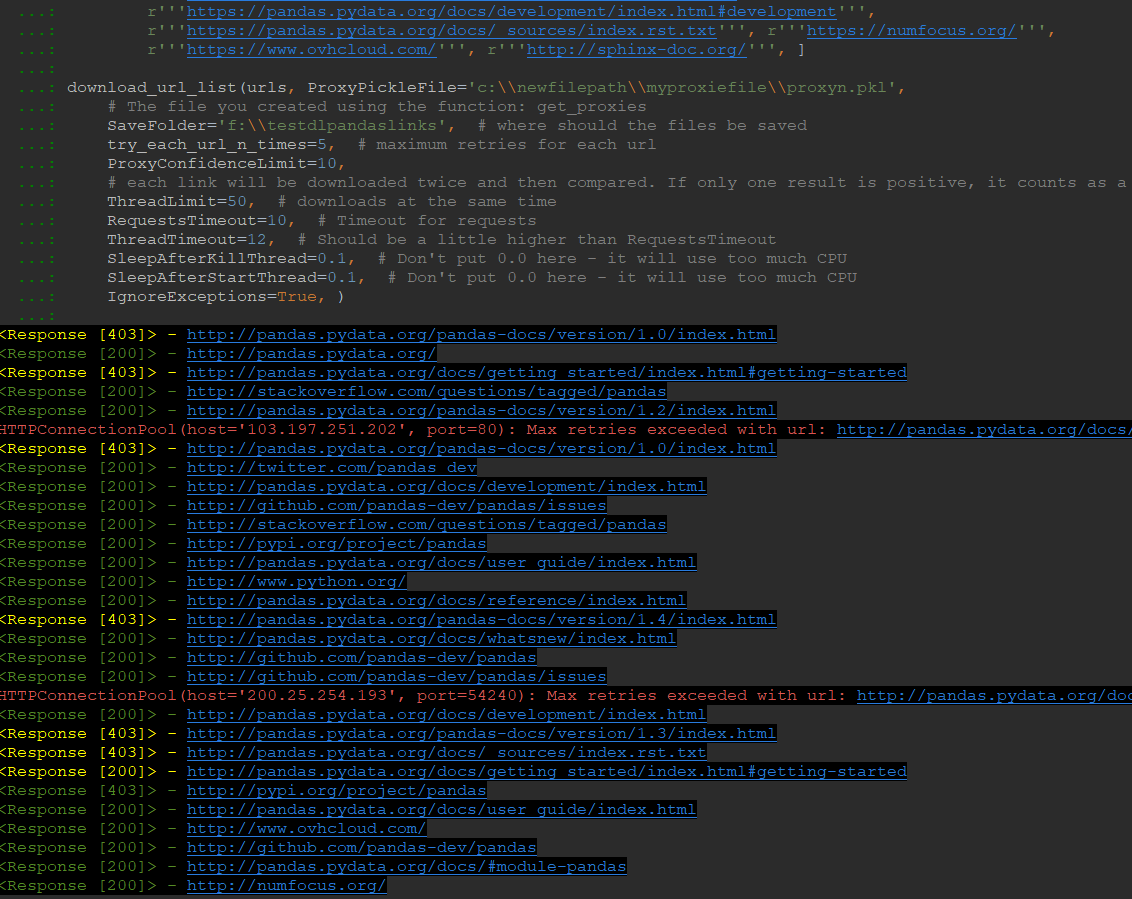
urls = [r'''https://pandas.pydata.org/docs/#''', r'''https://pandas.pydata.org/docs/getting_started/index.html''',
r'''https://pandas.pydata.org/docs/user_guide/index.html''',
r'''https://pandas.pydata.org/docs/reference/index.html''',
r'''https://pandas.pydata.org/docs/development/index.html''',
r'''https://pandas.pydata.org/docs/whatsnew/index.html''', r'''https://pandas.pydata.org/docs/dev/index.html''',
r'''https://pandas.pydata.org/docs/index.html''',
r'''https://pandas.pydata.org/pandas-docs/version/1.4/index.html''',
r'''https://pandas.pydata.org/pandas-docs/version/1.3/index.html''',
r'''https://pandas.pydata.org/pandas-docs/version/1.2/index.html''',
r'''https://pandas.pydata.org/pandas-docs/version/1.1/index.html''',
r'''https://pandas.pydata.org/pandas-docs/version/1.0/index.html''',
r'''https://github.com/pandas-dev/pandas''', r'''https://twitter.com/pandas_dev''',
r'''https://pandas.pydata.org/docs/#pandas-documentation''', r'''https://pandas.pydata.org/docs/pandas.zip''',
r'''https://pandas.pydata.org/''', r'''https://pypi.org/project/pandas''',
r'''https://github.com/pandas-dev/pandas/issues''', r'''https://stackoverflow.com/questions/tagged/pandas''',
r'''https://groups.google.com/g/pydata''', r'''https://pandas.pydata.org/docs/#module-pandas''',
r'''https://www.python.org/''',
r'''https://pandas.pydata.org/docs/getting_started/index.html#getting-started''',
r'''https://pandas.pydata.org/docs/user_guide/index.html#user-guide''',
r'''https://pandas.pydata.org/docs/reference/index.html#api''',
r'''https://pandas.pydata.org/docs/development/index.html#development''',
r'''https://pandas.pydata.org/docs/_sources/index.rst.txt''', r'''https://numfocus.org/''',
r'''https://www.ovhcloud.com/''', r'''http://sphinx-doc.org/''', ]
download_url_list(urls, ProxyPickleFile='c:\\newfilepath\\myproxiefile\\proxyn.pkl',
# The file you created using the function: get_proxies
SaveFolder='f:\\testdlpandaslinks', # where should the files be saved
try_each_url_n_times=5, # maximum retries for each url
ProxyConfidenceLimit=10,
# each link will be downloaded twice and then compared. If only one result is positive, it counts as a not successful download. But if the ProxyConfidenceLimit is higher, then it will be accepted
ThreadLimit=50, # downloads at the same time
RequestsTimeout=10, # Timeout for requests
ThreadTimeout=12, # Should be a little higher than RequestsTimeout
SleepAfterKillThread=0.1, # Don't put 0.0 here - it will use too much CPU
SleepAfterStartThread=0.1, # Don't put 0.0 here - it will use too much CPU
IgnoreExceptions=True, )
Downloading a url list
Never close the app when this is the last message that was printed: "Batch done - writing files to HDD ..."
# downloads only links from one domain! All others are ignored!
starturls=[r'''https://pydata.org/upcoming-events/''', # if it can't find links on the starting page, pass a list of links from the site.
r'''https://pydata.org/past-events/''',
r'''https://pydata.org/organize-a-conference/''',
r'''https://pydata.org/start-a-meetup/''',
r'''https://pydata.org/volunteer/''',
r'''https://pydata.org/code-of-conduct/''',
r'''https://pydata.org/diversity-inclusion/''',
r'''https://pydata.org/wp-content/uploads/2022/03/PyData-2022-Sponsorship-Prospectus-v4-1.pdf''',
r'''https://pydata.org/sponsor-pydata/#''',
r'''https://pydata.org/faqs/''',
r'''https://pydata.org/''',
r'''https://pydata.org/about/''',
r'''https://pydata.org/sponsor-pydata/''',
r'''https://pydata.org/wp-content/uploads/2022/03/PyData-2022-Sponsorship-Prospectus-v4.pdf''',]
download_webpage(
ProxyPickleFile='c:\\newfilepath\\myproxiefile\\proxyn.pkl',
DomainName="pydata.org",
DomainLink="https://pydata.org/",
SaveFolder=r"f:\pandashomepagetest",
ProxyConfidenceLimit=10,
UrlsAtOnce=100,
ThreadLimit=50,
RequestsTimeout=10,
ThreadTimeout=12,
SleepAfterKillThread=0.1,
SleepAfterStartThread=0.1,
IgnoreExceptions=True,
proxy_http_check_timeout=4,
proxy_threads_httpcheck=65,
proxy_threads_ping=100,
proxy_silent=False,
proxy_max_proxies_to_check=1000,
starturls=starturls,
)
Downloading a whole page
# Command line also works, but you can't use starturls, and the proxy.pkl has to exist already!
# Best usage is to continue a download that hasn't been finished yet.
# Existing files won't be downloaded again!
import subprocess
import sys
subprocess.run(
[
sys.executable,
r"C:\Users\USERNAME\anaconda3\envs\ENVNAME\Lib\site-packages\site2hdd\__init__.py",
r"C:\Users\USERNAME\anaconda3\envs\ENVNAME\pandaspyd.ini",
]
)
# This is how ini files should look like
r"""
[GENERAL]
ProxyPickleFile = c:\newfilepath\myproxiefile\proxyn.pkl
ProxyConfidenceLimit = 10
UrlsAtOnce = 100
; ThreadLimit - 50% of UrlsAtOnce is a good number
ThreadLimit = 50
RequestsTimeout = 10
; ThreadTimeout - Should be a little higher than RequestsTimeout
ThreadTimeout = 12
; SleepAfterKillThread - Don't put 0.0 here
SleepAfterKillThread = 0.1
; SleepAfterStartThread - Don't put 0.0 here
SleepAfterStartThread = 0.1
IgnoreExceptions = True
SaveFolder = f:\pythonsite
DomainName = python.org
DomainLink = https://www.python.org/
"""
Downloading a whole page using the command line


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
site2hdd-0.15.tar.gz
(12.8 kB
view details)
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
site2hdd-0.15-py3-none-any.whl
(13.3 kB
view details)
File details
Details for the file site2hdd-0.15.tar.gz.
File metadata
- Download URL: site2hdd-0.15.tar.gz
- Upload date:
- Size: 12.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6e9eef1d5d165d875c903ecae92a620efaac1aa2446885192efc7fa79449ce0f
|
|
| MD5 |
f28e1fd630b8e7813ce003b19638d88d
|
|
| BLAKE2b-256 |
5bec36c3de9601f033798cda75aa3dee7dd2dc6a6846c44dd673ccf74018db9d
|
File details
Details for the file site2hdd-0.15-py3-none-any.whl.
File metadata
- Download URL: site2hdd-0.15-py3-none-any.whl
- Upload date:
- Size: 13.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5d0e93aff04e9d37214fcdddebdd27f0ddc87e1699f3bb61c7738b2acc444e4e
|
|
| MD5 |
3cedeb87ccda626665c833438681aa00
|
|
| BLAKE2b-256 |
aeacf49389badd7aad059a766c4271fbac993c46ce416c97e0436b3e8f9df479
|







