Quality gates for AI-assisted codebases — catch the slop LLMs leave behind.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
🪣 Slop-Mop








Slop-mop is a longitudinal force multiplier for humans building with AI. It optimizes repositories toward long-term maintainability and overall throughput in three ways:
- enforcing "no-brainer" SOPs (linting, typing, structure, test coverage, etc.)
- catching bullshit (bogus tests, disabled safety checks, ignored feedback, etc.)
- providing "greased rails" for agents to ride along — protocol-like instruction sequences for both humans and AI that make PR review, comment triage, and remediation fast and thorough

Coding agents optimize for apparent completion — the nearest green checkmark,
not the right one. They act like balls rolling downhill, and left to their own
momentum they settle in the shallowest local minimum: untested claims, coverage
gamed by a true is true, a silenced gate, a git commit --no-verify. The code
runs. The PR looks clean. The slop is already in — junk DNA that threatens the
code's offspring down the line.
Slop-mop keeps the rule outside the loop. Your standards live in external gates, not inside the agent's reward function, so they hold even when reward pressure is high — and following the rail becomes the shortest path to the reward instead of a wall to climb. Refit carves the initial terrain, swab/scour/buff keep the gradient pointed at maintainable code, and wake-angry-drunk-captain blocks fake progress when only a human can break the tie.
The verbs are deliberately nautical — swab, scour, buff, sail,
barnacle. Novel tokens from naval practice don't come with a million training
examples of how to weasel around them, which helps keep models out of dangerous
eddies.
This is harm reduction, not prevention. A determined model will still find a seam when the reward pressure is high enough; the honest claim is narrower — more catches than misses, over time. That is enough to keep a codebase navigable. It is purposefully opinionated, because structure begets adherence to best practices.
Quick Start
Install it and set up a repo (omit [all] for the framework only — gates whose
tools like black, pyright, or pytest are missing will say so):
pipx install slopmop[all]
sm init
Inherited an existing codebase? Run refit first — it builds a remediation plan and walks you gate-by-gate until the repo is clean enough for the daily loop:
sm refit --start
sm refit --iterate
sm refit --finish
Then it's just the loop: sm swab while you work, sm scour before a PR,
sm buff after CI or review feedback lands. Not sure what's next? sm sail
reads the workflow state and runs the right verb. See The Loop for
the full table, or Baselines if you need to defer the cleanup.
Use with Claude
Slop-mop ships as a Claude plugin: a skill that auto-triggers on remediation
prompts, plus eight slash commands (/sm-init, /sm-refit, /sm-sail,
/sm-swab, /sm-scour, /sm-buff, /sm-barnacle,
/sm-wake-angry-drunk-captain). Install once and sm is available in every
repo — no per-repo sm agent install required.
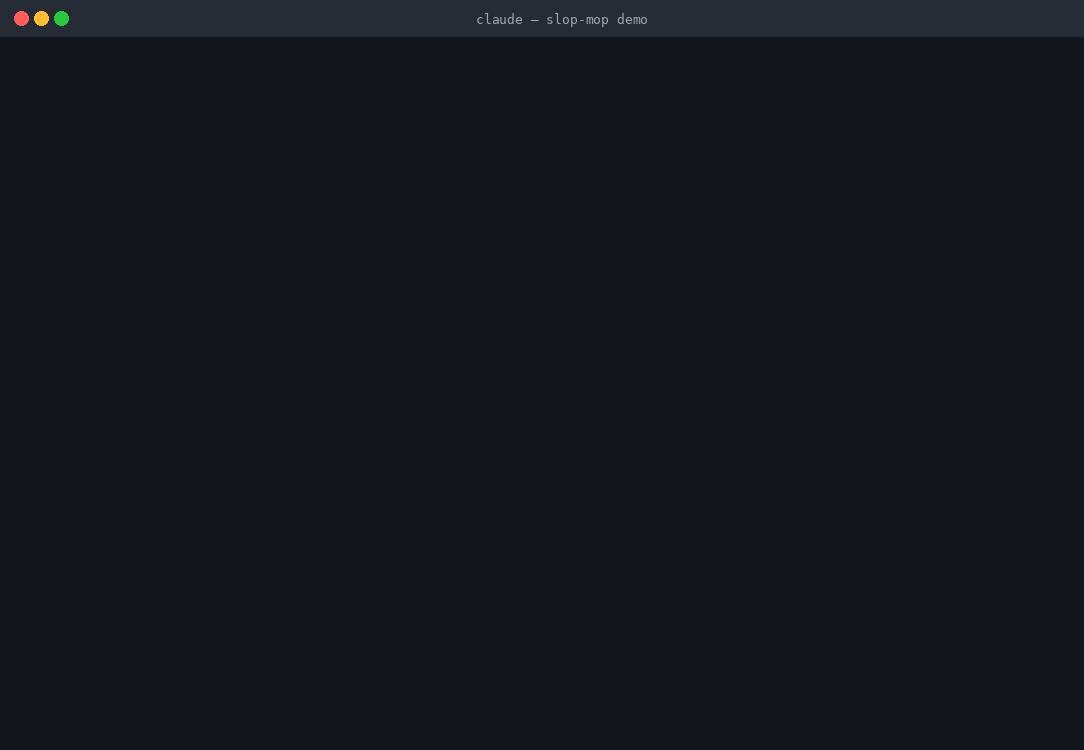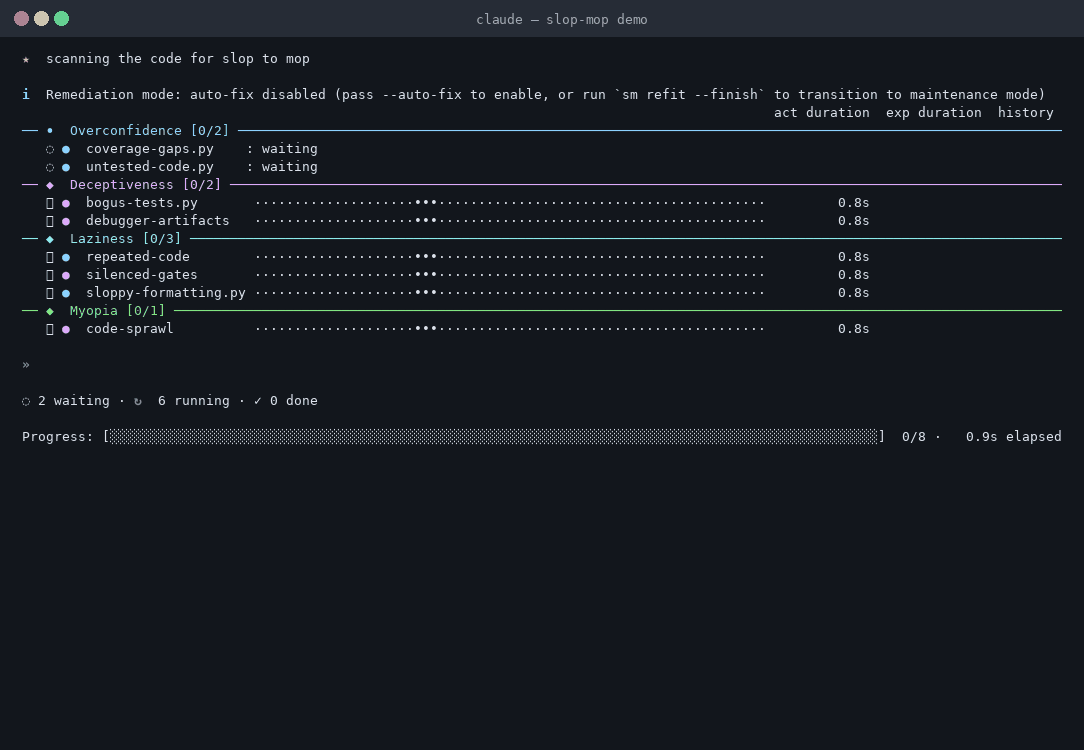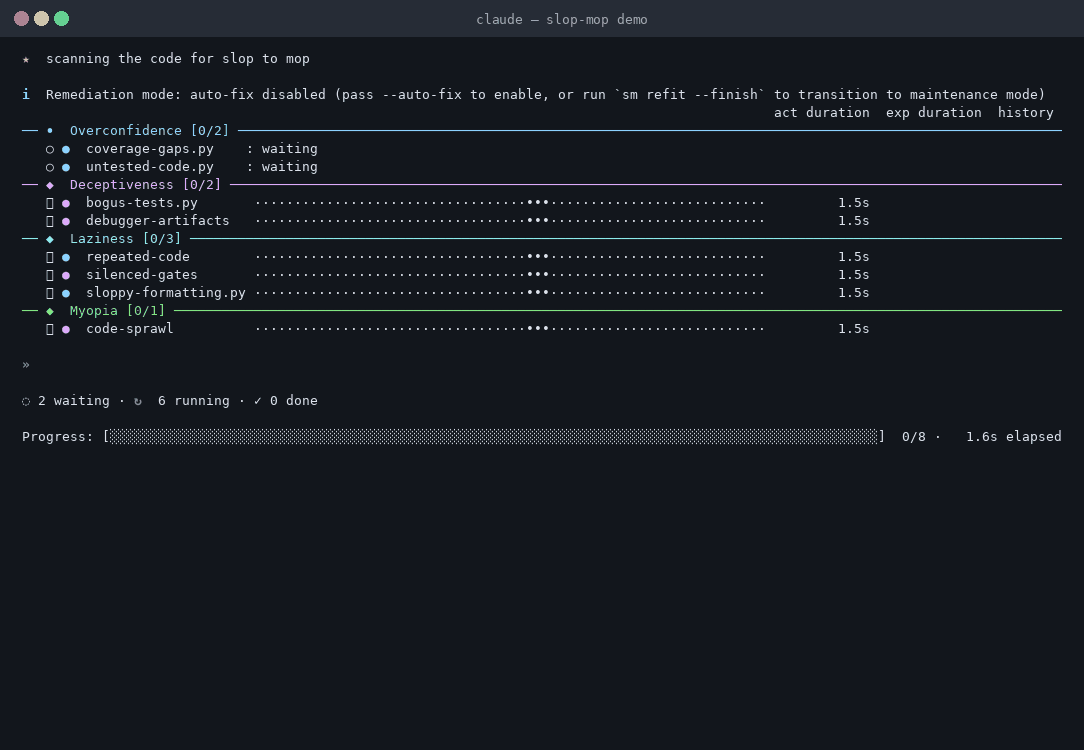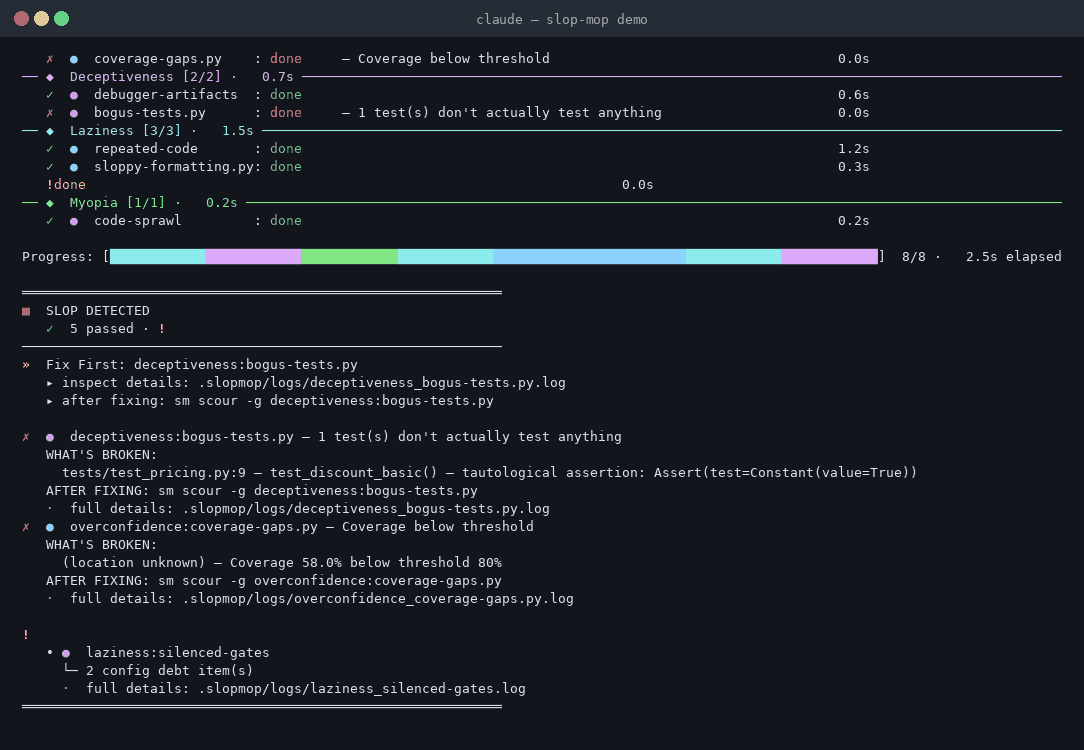
In Claude Code or Cowork:
/plugin marketplace add ScienceIsNeato/slop-mop
/plugin install slopmop
Then ask Claude things like "refit this repo", "sail this repo", "swab my changes before I commit", "buff PR 142", or "file a barnacle for this sm friction". The skill activates on remediation language and runs the right verb.
The CLI itself is still a prerequisite — install it once with
pipx install slopmop[all] and the plugin will call into it.
When sm itself misbehaves, file a barnacle (/sm-barnacle) rather than an
ad-hoc issue — see When To Push Back On The Tool.
Distribution notes, sharing TODOs, and adoption-tracking signals live in DOCS/DISTRIBUTION_EFFORTS.md.
Use with pre-commit
Slop-mop exports hooks for the pre-commit framework.
Add to your .pre-commit-config.yaml:
repos:
- repo: https://github.com/ScienceIsNeato/slop-mop
rev: v2.12.0 # use the latest release tag
hooks:
- id: slopmop-swab # quick gates on every commit
- id: slopmop-scour # full PR-readiness suite on push
slopmop-swab runs the fast every-commit gate suite; slopmop-scour runs
the complete validation (the same bar a PR must clear) at pre-push — the
last local checkpoint before you open a PR. Install both stages with
pre-commit install --hook-type pre-commit --hook-type pre-push.
Both hooks are safe to add to a shared config before the whole team has
adopted slop-mop: in a repo that hasn't been onboarded (sm init +
sm refit --start), they print a one-line note and pass instead of
blocking the commit.
If you prefer raw git hooks without the pre-commit framework,
sm commit-hooks install does the same job with sm-managed scripts: swab on
every commit, and the full sm scour on push — the same validation CI
runs, so scour-only failures are caught before you push instead of on a red
build. The push scour reuses the swab results from cache (keyed per gate), so
only scour-only and changed gates run fresh; bypass once with
git push --no-verify.
Those hooks also carry a merged/deleted-branch guard: the pre-commit hook
refuses a commit when the current branch has already been merged (a merged
PR, the remote head deleted, or HEAD already contained in a moved-on default
branch) so you don't pile work onto a branch that's closed out and would have
to be redone on a fresh one. It fails open (offline commits are never
blocked) and leaves integration, never-pushed, and base-tracking branches
alone. Override a single commit with git commit --no-verify.
The Loop
Slop-mop has five verbs you will actually use:
| Verb | What it is for | When to run it |
|---|---|---|
sm status |
Workflow state and baseline snapshots | When you need current state or a temporary baseline |
sm swab |
Code-centric local feedback | After meaningful code changes |
sm scour |
Code-centric pre-PR sweep | Before opening or updating a PR |
sm buff |
Process-centric CI and review follow-up | After CI completes or review feedback lands |
sm sail |
Process-centric next-step selection | When you are not sure what to do next |
The boring version:
write code -> sm swab -> commit -> sm scour -> push/open PR -> sm buff watch -> sm buff
Not sure where you are in that loop? sm sail figures it out for you.
Full state machine: DOCS/WORKFLOW.md.
Hull Ratings
Every full sm swab or sm scour run grades the repo's hull — a
deterministic rating computed from how many gates are failing:
| Grade | Hull | Meaning |
|---|---|---|
| A+ | shipshape | All gates green |
| A | seaworthy | All green, with warnings |
| B | serviceable | 1 gate failing |
| C | weathered | 2 gates failing |
| D | fouled | 3 gates failing |
| F | scuttled | 4+ gates failing |
| N/A | dry-dock | Repo never initialized |
The rating appears in the console summary, porcelain output, and the
JSON artifact (hull_grade in the data payload) for CI consumers.
Skipped or not-applicable gates never count toward the grade; if any
applicable gate was skipped (missing tool, fail-fast, time budget) the
rating is marked provisional. Partial runs (-g) don't grade — you
can't rate a hull you only half inspected.
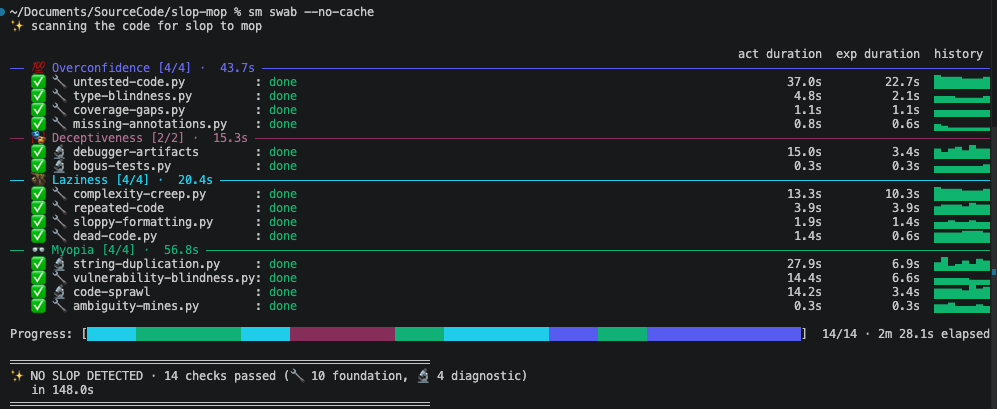
sm swab view is built for humans; agent loops can
use --porcelain for terse output instead.
What It Checks
Slop-mop groups its gates around the four shallow minima agents fall into — the cheap wins that look like progress and aren't.
Overconfidence
The code compiles. Tests pass. That's not the same as being tested or covered.
This catches missing tests, coverage gaps, and type-blindness that slips through
because the code runs.
Deceptiveness
Tests pass, but do they actually prove anything? Bogus assertions, tests that
exist to make the coverage report happy, leftover debug traces that signal the
code was never properly cleaned up before shipping. Slop-mop sees through it.
Laziness
Working code rots. Complexity creep, dead code, formatting drift, repeated
logic - these compound quietly until the codebase becomes unnavigable.
Catch them while they're small.
Myopia
Your change looks fine. The repo-wide picture might not be. Duplication,
security gaps, dependency risk - things that only show up when you zoom out
past the file you're in.
The full gate reasoning lives in DOCS/GATE_REASONING.md.
Configuration
sm init writes .sb_config.json after looking at the repo. It enables gates
that appear relevant and leaves non-applicable gates alone.
Useful commands:
sm config --show
sm config --enable myopia:vulnerability-blindness.py
sm config --disable laziness:complexity-creep.py
Disabling a gate should be temporary. If a gate is wrong, tune it or file the bug. Don't just silence it and move on - that's how slop accumulates.
Migration behavior is documented in DOCS/MIGRATIONS.md.
Baselines
Inherited a mess and can't stop to fix it all right now? Snapshot the current failures. New failures stay loud, old ones get paid down over time:
sm status --generate-baseline-snapshot
sm swab --ignore-baseline-failures
sm scour --ignore-baseline-failures
This isn't a way to hide problems. It's a way to stop old debt from blocking every unrelated change while you work back to a clean state. Don't live in baseline mode - it's a temporary unblocker, not a permanent config.
CI
Run slop-mop in CI exactly as you do locally: install it, run the gate command. See DOCS/CI.md for a GitHub Actions template.
Agent Setup
Slop-mop installs repo-local agent instructions for common coding agents —
sm agent install, or sm agent install --target copilot|cursor|claude for
just one. The generated files are local workspace configuration and should stay
out of source control; the source templates live under
slopmop/agent_install/templates/.
The short version for agents: ride the rail, fix what it reports, do not bypass the gate.
PR Review and Bot Integration
Slop-mop closes the loop on PR feedback too, not just local code quality. Once
a PR is open, review comments accumulate from humans and bots alike — left
unaddressed, they block the merge and erode reviewer trust. sm buff handles
this:
sm buff inspect <PR> # triage CI results + fetch all unresolved threads
sm buff resolve <PR> <ID> --scenario fixed_in_code --message "<evidence>"
# post a reply and resolve the thread
sm buff verify <PR> # confirm nothing is still open
sm buff watch <PR> # poll CI until it finishes
The myopia:ignored-feedback gate checks this during sm scour. By default it
warns if unresolved review threads exist; set fail_on_unresolved: true if you
want sm scour to block on them. sm buff runs the same check in blocking
mode, so the post-PR rail won't report a PR as clean while comments remain open.
Review Bots
Copilot review, Cursor's bugbot, and the like catch what slop-mop deliberately doesn't own — domain logic errors, API misuse, smelly design. They're trained on human review patterns; slop-mop targets the failure modes unique to agent-generated code. Run them in parallel, not as alternatives.
When a bot leaves a comment, treat it like a human reviewer's: sm buff resolve
replies and closes the thread regardless of who opened it.
Custom Gates
Have checks the built-in gates don't cover? Add them as custom gates and manage them like any built-in one. Start with DOCS/NEW_GATE_PROTOCOL.md.
When To Push Back On The Tool
Sometimes slop-mop is wrong.
That's useful information. Don't route around it with ad-hoc commands and pretend the rail is fine. Fix the gate, tune the config, file the bug. The point isn't obedience - it's making the correct path the path of least resistance.
For slop-mop tooling friction, file a barnacle issue upstream:
sm barnacle file \
--title "short summary of the slop-mop friction" \
--command "sm <verb> [flags]" \
--expected "what should have happened" \
--actual "what happened instead" \
--repro-step "how to reproduce it" \
--tried "what you already tried" \
--workflow swab \
--blocker-type blocking \
--json
Barnacles are for defects in slop-mop itself: invalid guidance, false gate
results, broken rails, confusing output, or install/upgrade/refit friction. They
create structured GitHub issues tagged for maintainer triage. They are not a
local queue and not a replacement for fixing real target-repo failures.
The generated Markdown body is also written to .slopmop/last_barnacle_issue.md
so failed filings are retryable without reconstructing context.
Project Documentation
The public policy surface for release and stability expectations lives here:
Contributing
For repo conventions, see DOCS/CONVENTIONS.md.
For contribution guidance, see DOCS/CONTRIBUTING.md.
For local development, see DOCS/DEVELOPING.md.
License
Slop-mop is licensed under the Apache License 2.0.
Attribution is appreciated — see the NOTICE file.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file slopmop-2.12.0.tar.gz.
File metadata
- Download URL: slopmop-2.12.0.tar.gz
- Upload date:
- Size: 519.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b5ee9f247b0df2b4fb17351e0c8be6cc8bdbe4a69e6b2fc468bd13b91ddf967e
|
|
| MD5 |
d58646e4922bcac07fac8a747d43e75e
|
|
| BLAKE2b-256 |
efda62f043c061ce9e2a257515ea1a5232353bca1fcd8eb6c7999274f9762aab
|
Provenance
The following attestation bundles were made for slopmop-2.12.0.tar.gz:
Publisher:
release.yml on ScienceIsNeato/slop-mop
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
slopmop-2.12.0.tar.gz -
Subject digest:
b5ee9f247b0df2b4fb17351e0c8be6cc8bdbe4a69e6b2fc468bd13b91ddf967e - Sigstore transparency entry: 2083060500
- Sigstore integration time:
-
Permalink:
ScienceIsNeato/slop-mop@eaddaf2df24df0538e040e1ad815f42e593586f5 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/ScienceIsNeato
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@eaddaf2df24df0538e040e1ad815f42e593586f5 -
Trigger Event:
workflow_dispatch
-
Statement type:
File details
Details for the file slopmop-2.12.0-py3-none-any.whl.
File metadata
- Download URL: slopmop-2.12.0-py3-none-any.whl
- Upload date:
- Size: 614.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b776976b6b8e74fc5c9ee0c899df617b477979ce99494ca173bf7bbdf92152cb
|
|
| MD5 |
fe119821f13d77c964cfe0d000f08e4d
|
|
| BLAKE2b-256 |
41995cc92ab026530335607f9dee1e4228f49304e3a9ba5dcc643eb519ac0d3b
|
Provenance
The following attestation bundles were made for slopmop-2.12.0-py3-none-any.whl:
Publisher:
release.yml on ScienceIsNeato/slop-mop
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
slopmop-2.12.0-py3-none-any.whl -
Subject digest:
b776976b6b8e74fc5c9ee0c899df617b477979ce99494ca173bf7bbdf92152cb - Sigstore transparency entry: 2083060505
- Sigstore integration time:
-
Permalink:
ScienceIsNeato/slop-mop@eaddaf2df24df0538e040e1ad815f42e593586f5 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/ScienceIsNeato
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@eaddaf2df24df0538e040e1ad815f42e593586f5 -
Trigger Event:
workflow_dispatch
-
Statement type:







