Just Query wikidata and other SPARQL endpoints by query name - a frontend to Introduce Named Queries and Named Query Middleware to wikidata and other SPARQL endpoints
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
snapQuery
Just query by name of query ...
snapquery catsis all you need
This endpoint and query detail independent style of querying wikidata and similar knowledge graph services makes your queries future proof. No worries about blazegraph being replaced, the graph being split or timeouts haunting you. snapquery introduces named queries and named query middleware to wikidata and other knowledge graph endpoints.
snapquery is a tool that simplifies the process of previewing, annotating, rating, commenting, running, and exploring queries across different backends. It enhances user experience by storing query results and allowing easy comparison across various backends and over time.
This tool is designed to assist users in curating and collaborating on queries, ensuring their continued functionality over time. Developers and data consumers can access data conveniently through APIs, streamlining their workflow.
The technology behind the backend knowlede graphs such as RDF, SPARQL, SQL, CSV, APIs is hidden.
| PyPi |      |
| GitHub |       |
| Code |   |
| Docs |    |
 |
|
 |
Demos
Background
In the Wikimedia ecosystem, we now boast several SPARQL engines and backends housing the complete Wikidata graph for querying purposes.
Over recent years, WDQS has encountered escalating timeouts as the graph expands. Users desire alternative endpoints without grappling with disparities among SPARQL engines and their impact on query construction.
Recognizing the needs of Wikidata data consumers, we aim to establish a system that simplifies:
- Discovering pre-existing queries
- Facilitating easy forking, sharing, rating, and monitoring of queries
- Executing queries (or their variations) on diverse endpoints
- Comparing query results over time and/or across multiple endpoints
- Cultivating a collaborative community for query construction
- Ensuring the reliability of query results
- Providing alerts if a query no longer yields the expected results
- Developing tools that access data from dependable, middleware-cached queries via an accessible API, eliminating delays for downstream users.
Links
- Phabricator Task: Introduce Named Queries and Named Query Middleware to wikidata
- Named Queries prototype by Tim Holzheim
Docs

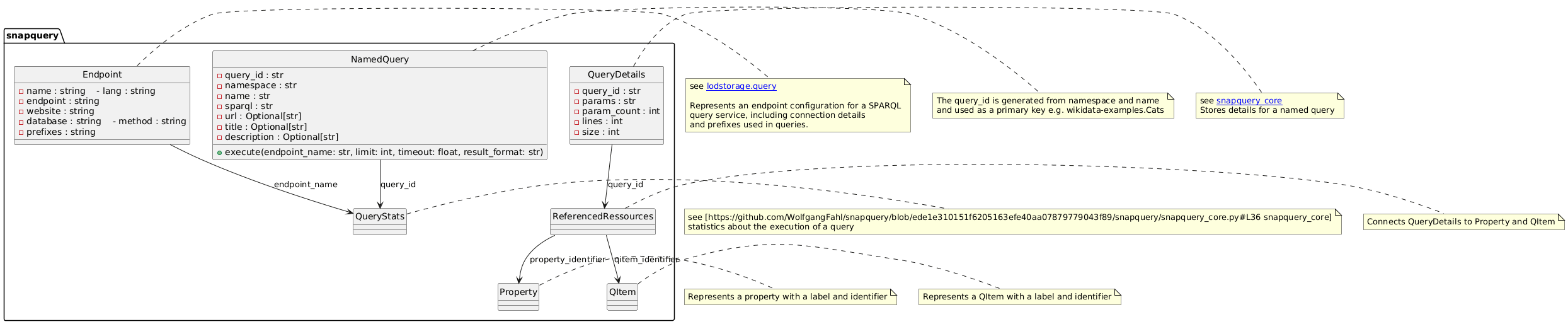
Model
Authors
Features
Planned
These are the planned features
- support for naming queries (#9) ✅
- support for sharing queries (unique identifier) (#2) ✅
- query multiple backends simultaneously and repeatedly ✅
- stores queries and adaptations needed for different backends ✅
- support user login ✅
- support for spam protection
- support for rating queries
- support for commenting on queries
- support for detecting when a query returns different results between different backends ✅
- support for query states: reliable, needs investigation, need verification ✅
- support for autodetecting when a query returns fewer results than before (change in underlying data/model in Wikidata) -> needs investigation
- support for marking queries as reliable query by users
- support for seeing a state history per query ✅
- support for storing query results so you don’t have to wait
- support for adding metadata to queries
- add main subject (QID) to query
- author -> id of author in the system
- forked from x
- has REST API for data consumers e.g. LLM developers who want to present user-verified queries and data to users to increase reliability ✅
User stories
- as a user I want to know in advance if the query is returning what I expect
- as a user I want to find all the rock bands starting with 'M' in Wikidata without having to know how it is modeled
- as a user I want pay someone to help me get the information from Wikidata that I need
- as a user I want to know how a query performed in the past so I can trust that the underlying model is stable and I get the expected results
- as a user I want to comment on a query
- as a user I want to read comments from others on a query so I get and idea how reliable it is
- as a user I want to rate a query with 1-5 stars
- as a user I want to get information from multiple sparql engines at the same time
- as a user I don’t want to wait for a fresh query to finish and just get the information from the latest time a query succeeded.
- as a user I want a list of queries in the middleware
- as a user I want to sort the list based on the rate of queries
- as a user I want to annotate a query with a name
- as a user I want to annotate a query with a wikidata item as main subject
- as a user I want to see a list of queries that is tagged with a certain topic (wikidata item)
- as a user I want an API to get information from the middleware about queries
- as a user I want an api endpoint /list that gives me all queries with the main subject=Qxxxx
- as a user I want the system to warn me and annotate a query that no longer returns the data the user expects, ie. if a query suddenly start returning no results or fewer results
- as a user I want to see a state on a query
- as a user I want to log in using github to avoid the hassle of creating another account
- as a user I want to log in using gitlab to avoid the hassle of creating another account
- as a user I want to log in using facebook to avoid the hassle of creating another account
- as a user I want to know how many backends a query is working on, so I get an overview
- as a user I want to get query results immediately if possible so I don’t have to wait
- as a user I want to import a query by copy pasting a url from WDQS
- as a user I want to run a query on multiple backends with one click
- as a user I want to fork a query and build on it
- as a user I want an email if a query I'm watching needs investigation
- as a user I want settings to control whether I get email notifications or not for all queries I'm watching
- as a user I want to watch a query
- as a user I want to see the history of actions of other users
- as a user I want to know who created a query
- as a user I want a setting to get email about new comments on queries I'm watching
- as a user I want a setting to get emails about new queries every day, week, month
- as a user I want to star a query
- as a user I want to browse queries and sort by number of stars
- as a user I want to see who starred a query
- as a user I want to see a list of my notifications
- as a wikidata contributor I want to be able to override the “bad query” state
- as a wikidata user I want to be able to log in using my wmf credentials to avoid the hassle of creating another account
- as a wikidata user I want to link my current account to my wmf account so others can find me by username
- as a developer I want to expose the data in API endpoints
- as a LLM developer I want to consume the queries and use them to improve my LLM so it can suggest KNOWN GOOD queries to users
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file snapquery-0.2.5.tar.gz.
File metadata
- Download URL: snapquery-0.2.5.tar.gz
- Upload date:
- Size: 1.0 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
27b60e94b105134c2af1952657cd94f3e12a90a83c4f2c75d0efeb4119fbc51e
|
|
| MD5 |
c6ba4badf0c20b4975fea90b1792ac0f
|
|
| BLAKE2b-256 |
f5598e7894561a478f396752a35d6e7711e9de7bfd4dd7181e3100b9b7d00fae
|
Provenance
The following attestation bundles were made for snapquery-0.2.5.tar.gz:
Publisher:
upload-to-pypi.yml on WolfgangFahl/snapquery
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
snapquery-0.2.5.tar.gz -
Subject digest:
27b60e94b105134c2af1952657cd94f3e12a90a83c4f2c75d0efeb4119fbc51e - Sigstore transparency entry: 768988078
- Sigstore integration time:
-
Permalink:
WolfgangFahl/snapquery@88d7e54e8d18ee7065a91e0936aa4c0c7d358cec -
Branch / Tag:
refs/tags/v0.2.5 - Owner: https://github.com/WolfgangFahl
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
upload-to-pypi.yml@88d7e54e8d18ee7065a91e0936aa4c0c7d358cec -
Trigger Event:
release
-
Statement type:
File details
Details for the file snapquery-0.2.5-py3-none-any.whl.
File metadata
- Download URL: snapquery-0.2.5-py3-none-any.whl
- Upload date:
- Size: 1.0 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b22be320872046756fa8fc95a0650b1d65210edfcaac6e18b50df4d5a0bfe8dd
|
|
| MD5 |
2bdaed91dcbcc4c2f6cc0391f9af1581
|
|
| BLAKE2b-256 |
2d50c5163d35e54afb11d738827ea4e33a9860e983752533240b7d8a541addca
|
Provenance
The following attestation bundles were made for snapquery-0.2.5-py3-none-any.whl:
Publisher:
upload-to-pypi.yml on WolfgangFahl/snapquery
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
snapquery-0.2.5-py3-none-any.whl -
Subject digest:
b22be320872046756fa8fc95a0650b1d65210edfcaac6e18b50df4d5a0bfe8dd - Sigstore transparency entry: 768988090
- Sigstore integration time:
-
Permalink:
WolfgangFahl/snapquery@88d7e54e8d18ee7065a91e0936aa4c0c7d358cec -
Branch / Tag:
refs/tags/v0.2.5 - Owner: https://github.com/WolfgangFahl
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
upload-to-pypi.yml@88d7e54e8d18ee7065a91e0936aa4c0c7d358cec -
Trigger Event:
release
-
Statement type:







