A lightweight text-to-speech model with zero-shot voice cloning.

Project description
https://github.com/user-attachments/assets/40254391-248f-45ff-b9a4-107d64fbb95f
Sopro TTS

📰 News
2026.02.04 – SoproTTS v1.5 is out: more stable, faster, and smaller. Trained for just $100, it reaches 250 ms TTFA streaming and 0.05 RTF (~20× realtime) on CPU.
Sopro (from the Portuguese word for “breath/blow”) is a lightweight English text-to-speech model I trained as a side project. Sopro is composed of dilated convs (à la WaveNet) and lightweight cross-attention layers, instead of the common Transformer architecture. Even though Sopro is not SOTA across most voices and situations, I still think it’s a cool project made with a very low budget (trained on a single L40S GPU), and it can be improved with better data.
Some of the main features are:
- 147M parameters
- Streaming
- Zero-shot voice cloning
- 0.05 RTF on CPU (measured on an M3 base model), meaning it generates 32 seconds of audio in 1.77 seconds
- 3-12 seconds of reference audio for voice cloning
Instructions
I only pinned the minimum dependency versions so you can install the package without having to create a separate env. However, some versions of Torch work best. For example, on my M3 CPU, torch==2.6.0 (without torchvision) achieves ~3× more performance.
(Optional)
conda create -n soprotts python=3.10
conda activate soprotts
From PyPI
pip install -U sopro
From the repo
git clone https://github.com/samuel-vitorino/sopro
cd sopro
pip install -e .
Examples
CLI
soprotts \
--text "Sopro is a lightweight 169 million parameter text-to-speech model. Some of the main features are streaming, zero-shot voice cloning, and 0.25 real-time factor on the CPU." \
--ref_audio ref.wav \
--out out.wav
You have the expected temperature and top_p parameters, alongside:
--style_strength(controls the FiLM strength; increasing it can improve or reduce voice similarity; default1.2)
Python
Non-streaming
from sopro import SoproTTS
tts = SoproTTS.from_pretrained("samuel-vitorino/sopro", device="cpu")
wav = tts.synthesize(
"Hello! This is a non-streaming Sopro TTS example.",
ref_audio_path="ref.wav",
)
tts.save_wav("out.wav", wav)
Streaming
import torch
from sopro import SoproTTS
tts = SoproTTS.from_pretrained("samuel-vitorino/sopro", device="cpu")
chunks = []
for chunk in tts.stream(
"Hello! This is a streaming Sopro TTS example.",
ref_audio_path="ref.mp3",
):
chunks.append(chunk.cpu())
wav = torch.cat(chunks, dim=-1)
tts.save_wav("out_stream.wav", wav)
You can also precalculate the reference to reduce TTFA:
import torch
from sopro import SoproTTS
tts = SoproTTS.from_pretrained("samuel-vitorino/sopro", device="cpu")
ref = tts.prepare_reference(ref_audio_path="ref.mp3")
chunks = []
for chunk in tts.stream(
"Hello! This is a streaming Sopro TTS example.",
ref=ref,
):
chunks.append(chunk.cpu())
wav = torch.cat(chunks, dim=-1)
tts.save_wav("out_stream.wav", wav)
Interactive streaming demo
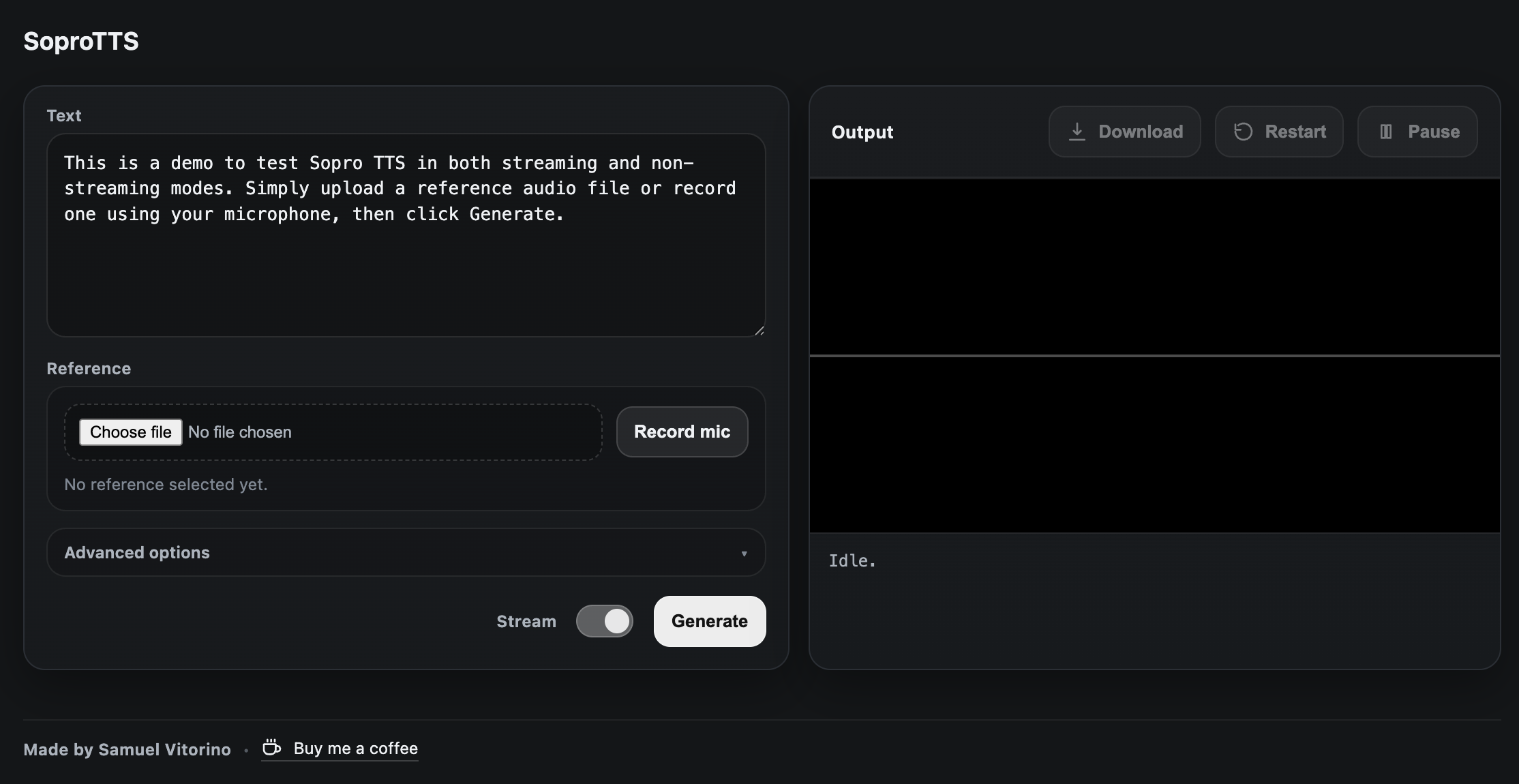
After you install the sopro package:
pip install -r demo/requirements.txt
uvicorn demo.server:app --host 0.0.0.0 --port 8000
Or with docker:
docker build -t sopro-demo .
docker run --rm -p 8000:8000 sopro-demo
Navigate to http://localhost:8000 on your browser.
Disclaimers
- Sopro can be inconsistent, so mess around with the parameters until you get a decent sample.
- Voice cloning is highly dependent on mic quality, ambient noise, etc. On more OOD voices it might fail to match the voice well.
- Prefer phonemes instead of abbreviations and symbols. For example,
“1 + 2”→“1 plus 2”. That said, Sopro can generally read abbreviations like “CPU”, “TTS”, etc. - The streaming version is not bit-exact compared to the non-streaming version. For best quality, prioritize the non-streaming version.
- If you use torchaudio to read or write audio, ffmpeg may be required. I recommend just using soundfile.
- I will publish the training code once I have time to organize it.
Due to budget constraints, the dataset used for training was pre-tokenized and the raw audio was discarded (it took up a lot of space). Later in training, I could have used the raw audio to improve the speaker embedding / voice similarity, because some nuances of voice are lost when you compress it with a neural codec into a discrete space.
I didn't lose much time trying to optimize further, but there is still some room for improvement. For example, caching conv states.
Currently, generation is limited to ~32 seconds (400 frames). You can increase it, but the model generally hallucinates beyond that.
AI was used mainly for creating the web demo, organizing my messy code into this repo, ablations and brainstorming.
I would love to support more languages and continue improving the model. If you like this project, consider buying me a coffee so I can buy more compute: https://buymeacoffee.com/samuelvitorino
Training data
Acknowledgements
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file sopro-1.5.0.tar.gz.
File metadata
- Download URL: sopro-1.5.0.tar.gz
- Upload date:
- Size: 29.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8d85d27949b85a7401d52777b0798204e973145eeb39fcc9f01c1925cbf3d8a4
|
|
| MD5 |
625231f54e0d29f53a83fef9df374ceb
|
|
| BLAKE2b-256 |
971bbab0b7e0d0f5b477f6b7f98b8181bc95191be75f9d9525540a4a1ce5be7e
|
File details
Details for the file sopro-1.5.0-py3-none-any.whl.
File metadata
- Download URL: sopro-1.5.0-py3-none-any.whl
- Upload date:
- Size: 34.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.19
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cc18f002bc88d0c350cf238c1e05c38192fa7da0817e54ba02f193e539bed2b4
|
|
| MD5 |
f08c68baf5ea88d87d140eeac9029447
|
|
| BLAKE2b-256 |
43913ba5c337add6bdf56ff267c69b5cc9f39e013f601785e7298abb59a2838b
|







