Add your description here


Project description
spacy-matching

Background
In Germany's cancer registries, substances are reported in a free text field, e.g., "Interferon alpha-2a weekly i.v.". The reported text might include additional information such as dosage or labels or typos. For analysis, it is helpful to have substances reported in a harmonized way. The aim of this Python function is extracting the substance name from the free text field. The script uses the FuzzyMatcher from spaczz and spacy to scan each free text for potential matches.
Usage
Call add_substance() with these arguments as Series:
col_with_substances- original substance name (freetext)col_with_ref_substances- reference list of substances
Returns a dataframe with the following columns:
Original- column with original valueMapped_to- column with recoded value, i.e the substance name that is deemed most likelySimilarity- column with similarity score
Original Mapped_to Similarity
0 Fluorouracil Fluorouracil 1.00
1 Epirubicin Epirubicin 1.00
2 PEG-Asparaginase Pegaspargase 0.86
3 Trastuzumab Trastuzumab 1.00
4 Temozolomid (Temodal®) Temozolomid 1.00
from spacy_matching import recoding as rec
# * get substance reference table from public repo
URL_V2 = "https://gitlab.opencode.de/robert-koch-institut/zentrum-fuer-krebsregisterdaten/cancerdata-references/-/raw/main/data/v2/Klassifikationen/substanz.csv?ref_type=heads"
reference_list = pd.read_csv(URL_V2, sep=";")
# * create a pandaSeries with some test data
fake_data = pd.Series(["Interferon alpha 2a", "Paclitaxel (nab)", "Filgrastim", "Leuprorelin; Tamoxifen"])
# * add a column with recoded substances
results = rec.add_substance(
col_with_substances=fake_data,
col_with_ref_substances=reference_list["substanz"],
threshold=0.85
)
Options and parameters
threshold
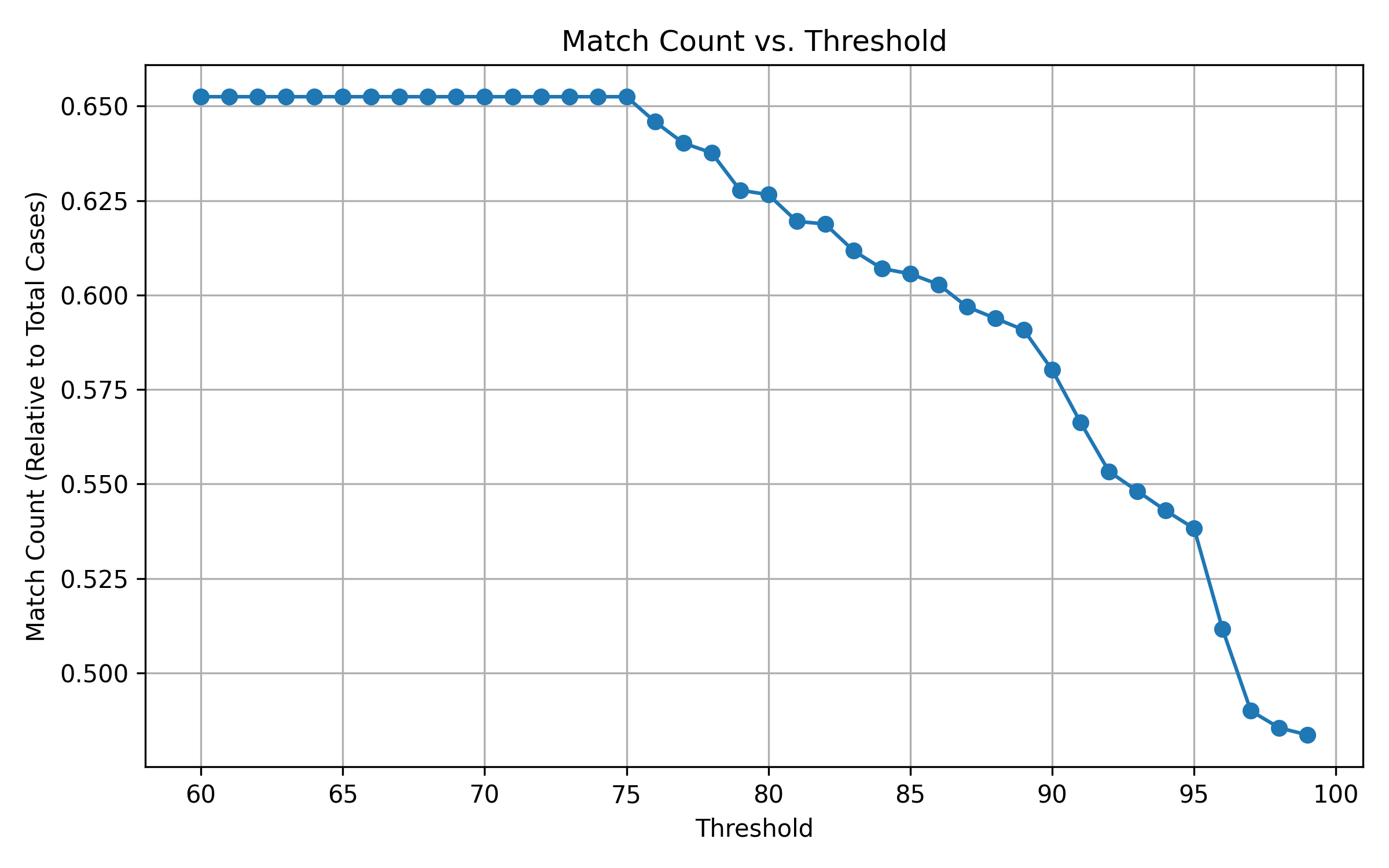
The function features some parameters: The threshold parameter defines the accuracy. The lower the more matches but higher
values lead to more accurate matches. The graph below plots the number of substances extracted from free text fields against the corresponding threshold parameter. There is a tradeoff between the number of matches and their accuracy. A threshold value of 0.85 is set as default as it usually ensures sufficient accuracy.
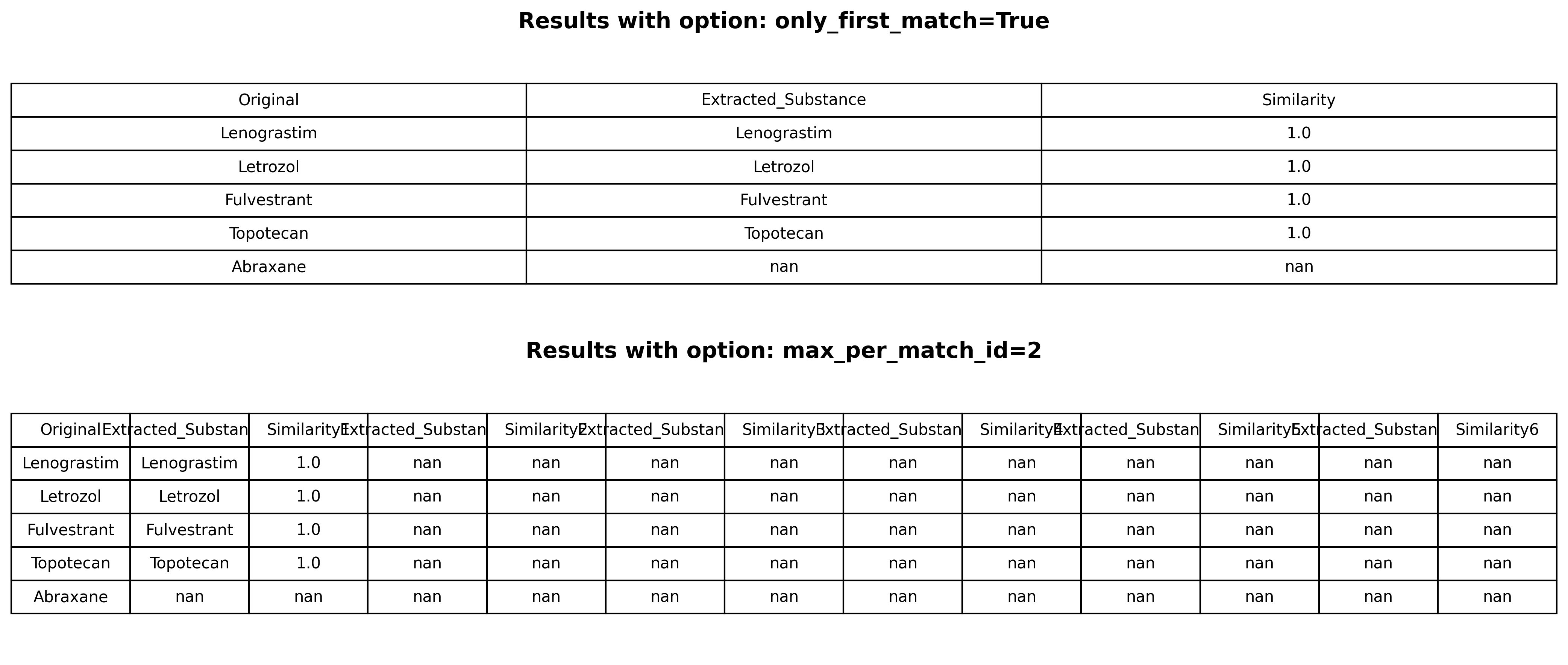
only_first_match
The option only_first_match = True should be used if the user wants to allow only one match per free text field.
Even if there are several substances in the free text field such as "Leuprorelin; Tamoxifen", the function will return only the first match.
If the option is set to "False", the function can return multiple hits. For the input "Interferon alpha-2a weekly i.v.", the function might return two substances "Interferon alpha-2a" and "Interferon alpha-2b" (assuming they are both on the reference list). Results based on both options is shown below.
Credits
Thanks to @smeisegeier for helpful feedback on the code and for making the function available as a python package.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file spacy_matching-0.5.1.tar.gz.
File metadata
- Download URL: spacy_matching-0.5.1.tar.gz
- Upload date:
- Size: 9.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c721c0aef438cb2b4c689f55b229f0d4f625255a47fc9e5c56aa28cb999be64b
|
|
| MD5 |
9f0989fe53f45dccc6b1db98338d1e95
|
|
| BLAKE2b-256 |
b567d51a286c166e9dce5587295b54b4a75209c4b823ec6f94d1206759941429
|
File details
Details for the file spacy_matching-0.5.1-py3-none-any.whl.
File metadata
- Download URL: spacy_matching-0.5.1-py3-none-any.whl
- Upload date:
- Size: 11.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e18d037675edb5da0b21baab52401a64bf8a43016a12f8b93eab47452ef9c400
|
|
| MD5 |
d48e99d3369978c12a4d4255e5c5930f
|
|
| BLAKE2b-256 |
619efc60cb5f4c99cd427185e148d4153733104363d4ec7901d2f54db56edfe3
|







