Calibrating model scores/probabilities with PySpark DataFrames

Project description
Model calibration with pyspark
This package provides a Betacal class which allows the user to fit/train the default beta calibration model on pyspark dataframes and predict calibrated scores
Setup
spark-calibration package is uploaded to PyPi and can be installed with this command:
pip install spark-calibration
Usage
Training
train_df should be a pyspark dataframe containing:
- A column with raw model scores (default name:
score) - A column with binary labels (default name:
label)
You can specify different column names when calling fit(). In some tree-based models like LightGBM, the predicted scores may fall outside the [0, 1] range and can even be negative. Please apply a sigmoid function to normalize the outputs accordingly.
from spark_calibration import Betacal
from spark_calibration import display_classification_calib_metrics
from spark_calibration import plot_calibration_curve
# Initialize model
bc = Betacal(parameters="abm")
# Load training data
train_df = spark.read.parquet("s3://train/")
# Fit the model
bc.fit(train_df)
# Or specify custom column names
# bc.fit(train_df, score_col="raw_score", label_col="actual_label")
# Access model parameters
print(f"Model coefficients: a={bc.a}, b={bc.b}, c={bc.c}")
The model learns three parameters:
- a: Coefficient for log(score)
- b: Coefficient for log(1-score)
- c: Intercept term
Saving and Loading Models
You can save the trained model to disk and load it later:
# Save model
save_path = bc.save("/path/to/save/")
# Load model
loaded_model = Betacal.load("/path/to/save/")
Prediction
test_df should be a pyspark dataframe containing a column with raw model scores. By default, this column should be named score, but you can specify a different column name when calling predict(). The predict function adds a new column prediction which has the calibrated score.
test_df = spark.read.parquet("s3://test/")
# Using default column name 'score'
test_df = bc.predict(test_df)
# Or specify a custom score column name
# test_df = bc.predict(test_df, score_col="raw_score")
Pre & Post Calibration Classification Metrics
The test_df should have score, prediction & label columns.
The display_classification_calib_metrics functions displays brier_score_loss, log_loss, area_under_PR_curve and area_under_ROC_curve
display_classification_calib_metrics(test_df)
Output
model brier score loss: 0.08072683729933376
calibrated model brier score loss: 0.01014015353257748
delta: -87.44%
model log loss: 0.3038106859864252
calibrated model log loss: 0.053275633947890755
delta: -82.46%
model aucpr: 0.03471287564672635
calibrated model aucpr: 0.03471240518472563
delta: -0.0%
model roc_auc: 0.7490639506966398
calibrated model roc_auc: 0.7490649764289607
delta: 0.0%
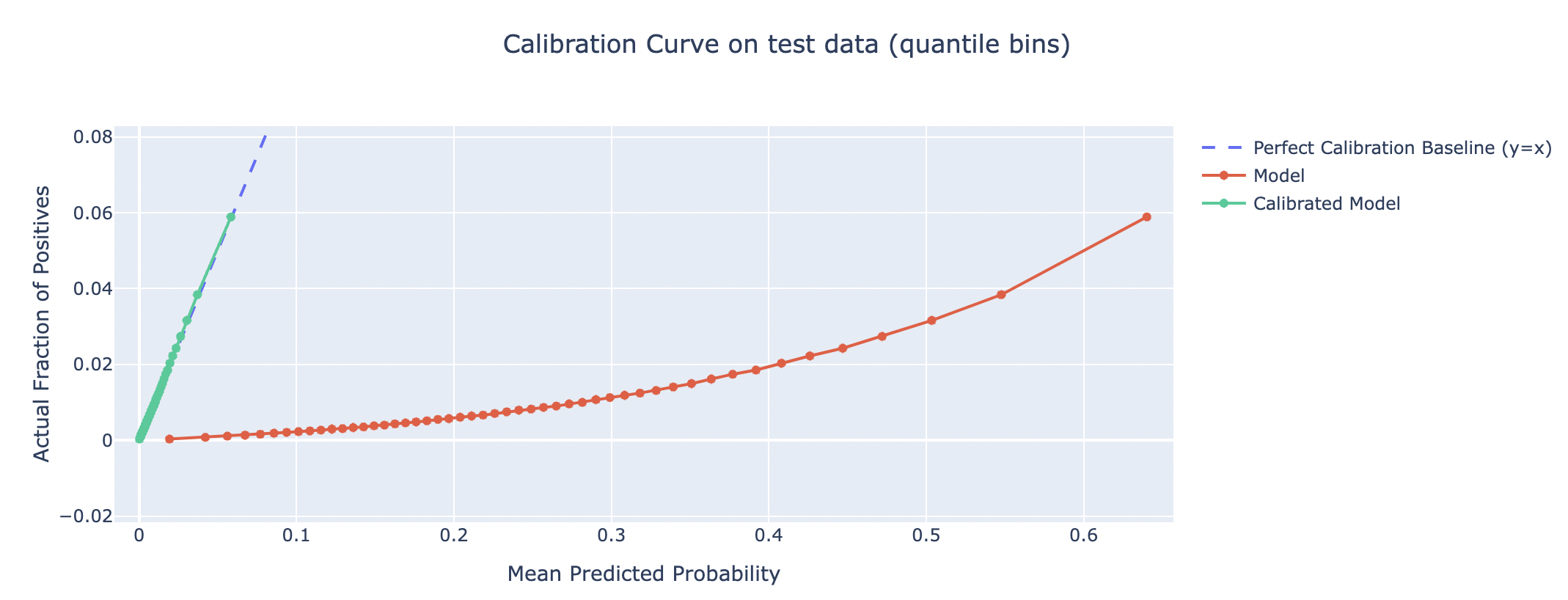
Plot the Calibration Curve
Computes true, predicted probabilities (pre & post calibration) using quantile binning strategy with 50 bins and plots the calibration curve
plot_calibration_curve(test_df)


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file spark_calibration-2.0.0.tar.gz.
File metadata
- Download URL: spark_calibration-2.0.0.tar.gz
- Upload date:
- Size: 10.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.9.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5f76590c4acdf8073e21207dcace51c0f3315ecf8bb2f782e65aa7a33d704202
|
|
| MD5 |
1e1f838d1097549f1b7352c0dbed4620
|
|
| BLAKE2b-256 |
75a3976929d943df21f421d4c618ccea641a269f9ce3c98a2a6012f19e5ae44c
|
File details
Details for the file spark_calibration-2.0.0-py3-none-any.whl.
File metadata
- Download URL: spark_calibration-2.0.0-py3-none-any.whl
- Upload date:
- Size: 11.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.9.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8240951c45c895e8e3251cb3af2c9f221cd0096e57b259ae615db1db25708dce
|
|
| MD5 |
278770b52f9be98f3760f3cf0cec1a03
|
|
| BLAKE2b-256 |
6ccd45778e9f9ef9a933f17b3648eacb73ea4900e66df035ab6483495d404104
|







