Speechlib is a library that unifies speaker diarization, transcription and speaker recognition in a single pipeline to create transcripts for audio conversations with actual speaker names and time tags. This library also contains audio preprocessor functions.

Project description
Recall.ai - Meeting Transcription API
If you’re looking for a transcription API for meetings, consider checking out Recall.ai, an API that works with Zoom, Google Meet, Microsoft Teams, and more. Recall.ai diarizes by pulling the speaker data and separate audio streams from the meeting platforms, which means 100% accurate speaker diarization with actual speaker names.
Speechlib
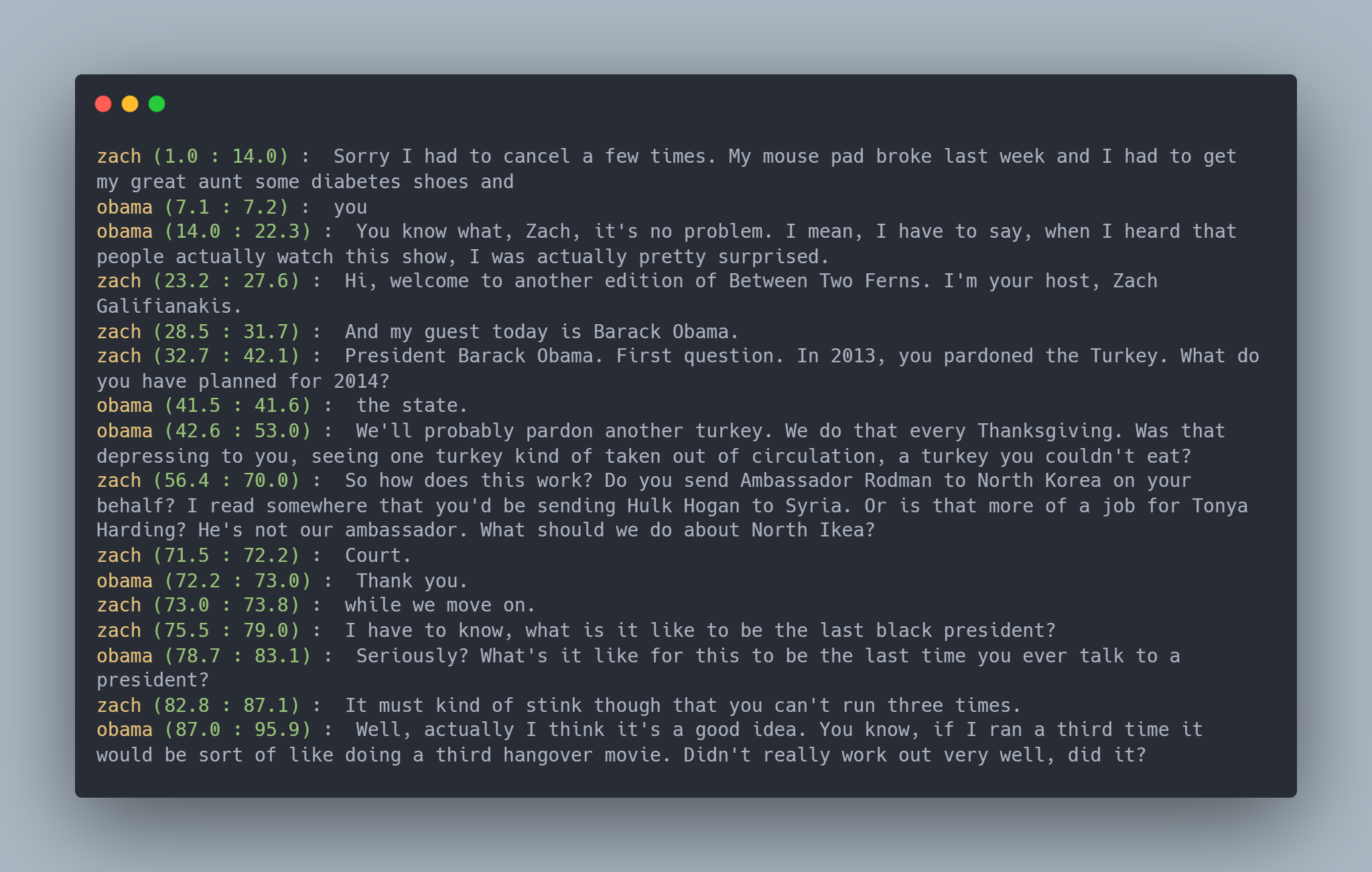







Speechlib is a Python library that unifies speaker diarization, speaker recognition, and transcription into a single pipeline, producing transcripts with speaker names and time tags.
Table of Contents
- Requirements
- Installation
- GPU Execution
- Quick Start
- Pipeline Parameters
- ASR Backends
- Diarization
- Speaker Recognition
- Examples
- Output Format
- Audio Preprocessing
- Supported Languages
- Performance
- Citation
Requirements
- Python 3.10 or greater
- ffmpeg installed
Windows users: Run your IDE as administrator to avoid
OSError: [WinError 1314] A required privilege is not held by the client.
Installation
# installs with cpu-only torch
pip install speechlib
# installs with gpu-supported torch (replace correct index url with your compatible cuda driver)
pip install speechlib --extra-index-url https://download.pytorch.org/whl/cu126
if this error occured:
hf_hub_download() got an unexpected keyword argument 'use_auth_token'. then runpip install --force-reinstall huggingface-hub==0.36.0
Dependencies
accelerate>=1.12.0
assemblyai>=0.50.0
faster-whisper>=1.2.1
huggingface-hub==0.36.0
numpy==1.26.4
openai-whisper>=20250625
pyannote-audio==3.4.0
pydub>=0.25.1
speechbrain==1.0.3
torch==2.2.0
torchaudio==2.2.0
torchvision==0.17.0
transformers>=4.57.6
GPU Execution
GPU execution requires CUDA 11 and the following NVIDIA libraries:
Quick Start
import os
from speechlib import Pipeline, PyAnnoteDiarizer, FasterWhisperASR
pipeline = Pipeline(
diarization_model=PyAnnoteDiarizer(
access_token=os.environ["HF_TOKEN"],
min_speakers=1,
max_speakers=2,
),
asr_model=FasterWhisperASR("turbo"),
language=None, # None = auto-detect
log_folder="logs",
output_format="both", # "txt", "json", or "both"
)
segments = pipeline.run("interview.wav")
Pipeline Parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
diarization_model |
BaseDiarizer |
required | Diarization backend instance |
asr_model |
BaseASR |
required | ASR backend instance |
speaker_recognition_model |
BaseRecognizer | None |
None |
Speaker recognition backend; omit to use anonymous SPEAKER_XX tags |
language |
str | None |
None |
BCP-47 language code (e.g. "en", "fr"), or None for auto-detection |
voices_folder |
str | None |
None |
Root directory of per-speaker reference recordings (see structure below) |
log_folder |
str |
"logs" |
Output directory for transcript files |
output_format |
str |
"both" |
"txt", "json", or "both" |
verbose |
bool |
False |
Print per-segment progress and stage timings |
srt |
bool |
False |
Also write an SRT subtitle file |
workers |
int | None |
None |
Threads for parallel transcription. None = cpu_count - 1, 1 = sequential |
ASR Backends
FasterWhisperASR (recommended)
CTranslate2-based faster-whisper. Lowest memory, fastest inference.
from speechlib import FasterWhisperASR
FasterWhisperASR(
model_size="turbo", # tiny, base, small, medium, large, large-v1/v2/v3, turbo, large-v3-turbo
quantization=False, # True = int8 quantization (less memory, faster on CPU/GPU)
beam_size=5, # any whisper.transcribe kwarg accepted
)
WhisperASR
OpenAI Whisper.
from speechlib import WhisperASR
WhisperASR(
model_size="turbo",
temperature=0.0, # any whisper.transcribe kwarg accepted
)
CustomWhisperASR
Local fine-tuned Whisper checkpoint.
from speechlib import CustomWhisperASR
CustomWhisperASR(model_path="/path/to/model.pt")
HuggingFaceASR
Any HuggingFace automatic-speech-recognition model.
from speechlib import HuggingFaceASR
HuggingFaceASR("distil-whisper/distil-small.en")
AssemblyAIASR
AssemblyAI cloud transcription.
from speechlib import AssemblyAIASR
import assemblyai as aai
AssemblyAIASR(
api_key="your_assemblyai_key",
speech_model=aai.SpeechModel.nano, # optional, defaults to nano
)
Diarization
PyAnnoteDiarizer
Requires a HuggingFace token with access to pyannote/speaker-diarization@2.1 and pyannote/segmentation.
from speechlib import PyAnnoteDiarizer
# Variable speaker count
PyAnnoteDiarizer(
access_token="hf_...",
min_speakers=1,
max_speakers=4,
)
# Exact speaker count (more accurate when known)
PyAnnoteDiarizer(
access_token="hf_...",
num_speakers=2,
)
Speaker Recognition
Provide a voices_folder with one subfolder per known speaker containing .wav reference recordings. The recognizer maps diarization tags to real names.
voices_folder/
├── alice/
│ └── alice_sample.wav
└── bob/
└── bob_sample.wav
from speechlib import SpeechBrainRecognizer
pipeline = Pipeline(
diarization_model=PyAnnoteDiarizer(access_token="hf_..."),
speaker_recognition_model=SpeechBrainRecognizer("speechbrain/spkrec-ecapa-voxceleb"),
asr_model=FasterWhisperASR("turbo"),
voices_folder="voices",
...
)
If voices_folder is not provided, speakers are labelled SPEAKER_00, SPEAKER_01, etc.
Customizing the Pipeline
You can plug in any diarization, recognition, or ASR backend by subclassing the abstract base classes. All provider-specific parameters go in __init__; the pipeline calls the abstract method at runtime.
Custom ASR
from speechlib import BaseASR
class MyASR(BaseASR):
def __init__(self, model_path: str):
self.model = load_my_model(model_path) # your own loading logic
def transcribe(self, audio, language):
# audio is either a file path (str) or a BytesIO buffer
return self.model.infer(audio, lang=language)
Custom Diarizer
from speechlib import BaseDiarizer
class MyDiarizer(BaseDiarizer):
def __init__(self, threshold: float = 0.5):
self.threshold = threshold
def diarize(self, waveform, sample_rate: int) -> list[tuple[float, float, str]]:
# waveform: torch.Tensor of shape (channels, samples)
# return [(start_sec, end_sec, speaker_tag), ...]
return my_diarize(waveform, sample_rate, threshold=self.threshold)
Custom Speaker Recognizer
from speechlib import BaseRecognizer
class MyRecognizer(BaseRecognizer):
def recognize(self, file_name, voices_folder, segments, identified) -> str:
# file_name: path to the preprocessed mono WAV
# voices_folder: root dir with one subfolder per known speaker
# segments: [[start, end, tag], ...] for this speaker tag
# identified: names already assigned to other tags (must not reuse)
# return matched speaker name or "unknown"
return my_verify(file_name, voices_folder, segments, identified)
Examples
Minimal
from speechlib import Pipeline, PyAnnoteDiarizer, FasterWhisperASR
pipeline = Pipeline(
diarization_model=PyAnnoteDiarizer(access_token="hf_...", min_speakers=1, max_speakers=2),
asr_model=FasterWhisperASR("turbo"),
language=None,
log_folder="logs",
output_format="both",
)
segments = pipeline.run("interview.wav")
With Speaker Recognition + SRT
from speechlib import Pipeline, PyAnnoteDiarizer, SpeechBrainRecognizer, FasterWhisperASR
pipeline = Pipeline(
diarization_model=PyAnnoteDiarizer(access_token="hf_...", min_speakers=1, max_speakers=2),
speaker_recognition_model=SpeechBrainRecognizer("speechbrain/spkrec-ecapa-voxceleb"),
asr_model=FasterWhisperASR("turbo", quantization=True, beam_size=5),
language="en",
voices_folder="voices",
log_folder="logs",
output_format="json",
srt=True,
verbose=True,
)
segments = pipeline.run("interview.wav")
Batch Processing
batch_results = pipeline.run(["call1.wav", "call2.wav", "call3.wav"])
# returns list[list[dict]] — one inner list per file, in input order
HuggingFace Backend
from speechlib import Pipeline, PyAnnoteDiarizer, HuggingFaceASR
pipeline = Pipeline(
diarization_model=PyAnnoteDiarizer(access_token="hf_...", num_speakers=2),
asr_model=HuggingFaceASR("distil-whisper/distil-small.en"),
language="en",
log_folder="logs",
output_format="json",
)
pipeline.run("interview.wav")
AssemblyAI Backend
from speechlib import Pipeline, PyAnnoteDiarizer, AssemblyAIASR
pipeline = Pipeline(
diarization_model=PyAnnoteDiarizer(access_token="hf_...", min_speakers=1, max_speakers=2),
asr_model=AssemblyAIASR(api_key="your_assemblyai_key"),
log_folder="logs",
output_format="json",
)
pipeline.run("interview.wav")
Custom ASR Backend
from speechlib import Pipeline, PyAnnoteDiarizer, BaseASR
import nemo.collections.asr as nemo_asr
import threading
class NemoASR(BaseASR):
def __init__(self):
self.model = nemo_asr.models.ASRModel.from_pretrained(
model_name="nvidia/parakeet-tdt-0.6b-v2"
)
self.model.freeze()
self._lock = threading.Lock() # this model does not support parallelism unfortunately
def transcribe(self, audio, language):
with self._lock:
if not isinstance(audio, str):
with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as tmp:
tmp.write(audio.read())
tmp_path = tmp.name
try:
output = self.model.transcribe([tmp_path], timestamps=False)
finally:
os.remove(tmp_path)
else:
output = self.model.transcribe([audio], timestamps=False)
return output[0].text
pipeline = Pipeline(
diarization_model=PyAnnoteDiarizer(
access_token=HF_TOKEN,
num_speakers=2
),
asr_model=NemoASR(),
log_folder="logs",
output_format="json",
)
pipeline.run("interview.wav")
Output Format
pipeline.run() returns a list of segment dicts:
[
{
"file_name": "interview.wav",
"start_time": 1.0,
"end_time": 14.0,
"text": "Hello, welcome to the show.",
"speaker": "alice", # or "SPEAKER_00" if no voices_folder
"model_used": "turbo",
"language_detected": "en",
},
...
]
Transcript files are saved to log_folder:
| Format | Contents |
|---|---|
.txt |
speaker (start : end) : text per line |
.json |
Structured JSON with file metadata and segment array |
.srt |
SRT subtitle file (only when srt=True) |
Audio Preprocessing
Non-WAV files are converted automatically by the pipeline. You can also run preprocessing manually:
from speechlib.convert_to_wav import convert_to_wav
from speechlib.convert_to_mono import convert_to_mono
from speechlib.re_encode import re_encode
file = convert_to_wav("audio.mp3")
convert_to_mono(file)
re_encode(file)
Supported Languages
af, am, ar, as, az, ba, be, bg, bn, bo, br, bs, ca, cs, cy, da, de, el, en, es, et,
eu, fa, fi, fo, fr, gl, gu, ha, haw, he, hi, hr, ht, hu, hy, id, is, it, ja, jw, ka,
kk, km, kn, ko, la, lb, ln, lo, lt, lv, mg, mi, mk, ml, mn, mr, ms, mt, my, ne, nl,
nn, no, oc, pa, pl, ps, pt, ro, ru, sa, sd, si, sk, sl, sn, so, sq, sr, su, sv, sw,
ta, te, tg, th, tk, tl, tr, tt, uk, ur, uz, vi, yi, yo, zh, yue
Citation
@software{speechlib,
author = {NavodPeiris},
title = {Speechlib: Speaker Diarization, Recognition, and Transcription in a Single Pipeline},
year = {2024},
publisher = {GitHub},
url = {https://github.com/NavodPeiris/speechlib}
}
Sponsorship ❤️
If you find Speechlib useful, please consider supporting its development:
Your support helps maintain and improve the library. Thank you!
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file speechlib-2.0.2.tar.gz.
File metadata
- Download URL: speechlib-2.0.2.tar.gz
- Upload date:
- Size: 17.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.9.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7e274db06e142817db5235a0436e8410eff4dd156765c1c17f2edce1431717ed
|
|
| MD5 |
2fa72ba1aaeef412f2c92012433ec1ac
|
|
| BLAKE2b-256 |
e89d302ce35ab5629179d792e535fc89ebb6bfe65d2d073bc330af443db4b06f
|
File details
Details for the file speechlib-2.0.2-py3-none-any.whl.
File metadata
- Download URL: speechlib-2.0.2-py3-none-any.whl
- Upload date:
- Size: 21.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.9.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7b927f76dda91ade998ac097642e92013b89e5033c083bd55b36f182139d1775
|
|
| MD5 |
69d9e7855a8296fc50dc5ac894e143a3
|
|
| BLAKE2b-256 |
bb6035bb8fa84e90e0c6803f9395a58624efabf27476d4c5c1d17ea0f7ae4732
|







