KanaText class extends the functionality of Text class, for someone who use index/glossary directives.

Project description
This is a sphinx extention. It extends the functionality of the Text class. Any person, who uses index/glossary directives with Japanse Kanji, is to be so happy.

If word_list.txt is used by kana_text_word_file parameter, the genindex.html is created without editing rst files.
QUICK START
conf.py:
extensions = ['sphinxcontrib.kana_text']#kana_text_word_file = '~/.config/sphinx/word_list.txt'
#kana_text_word_list = ['ようご|用語^21', 'ぶんしょさくせい|文書作成^2222',]
#kana_text_indexer_mode = 'small'
#html_kana_text_on_genindex = Falserst file:
.. index:: ようご|用語^21.. glossary::
ようごいち|用語壱^212
用語1の説明。夜空に浮かぶ\ :index:`あまた|数多^21`\ の星々が\ :kana:`きらめいて|煌めいて^2c`\ いる。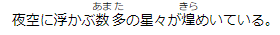
build:
$ make kanagenindex.html
$ sphinx-kana-genindex
$ mv genindex.html.sample path_to_sphinx_project/_templates/genindex.htmlnote(japanese)
当PyPIパッケージのインデクサー部分を「sphinxdexer」として切り分けています。 こちらのパッケージは読み仮名情報を付与する場合のリファレンス実装という役割も担うことになります。
自分なりの記法を実現されたい方は、Githubの実装を参考にして独自の記法を実現してください。独自の記法の解析は「KanaText」に集約されます。他はコピペで済むはずです。
同じパッケージ名は使えないので注意してください。紛らわしい名前(ピリオド/アンダーバーが異なるだけ)を避けてもらえると助かります。「kanatext2」などの気概を感じる名前はアリです。
DEVELOPMENT
structure of the data for genindex.html
entry: {file_name: [(entry_type, value, target, main, index_key)]}
file_name: the name without suffix
entries: [entry]
entry: (entry_type, value, target, main, index_key)
entry_type: in(‘single’, ‘pair’, ‘triple’, ‘see’, ‘seealso’)
value: ‘word’, ‘word; word’ or ‘word; word; word’
target: the target id
main: ‘main’ or ‘’
index_key: classifier or None
genidex: [(classifier, terms)]
classifier: KanaText
terms: [(term, list)]
term: KanaText
list: [links, subterms, index_key]
links: [(main, uri)]
subterms: [(subterm, links)]
subterm: SubTerm[KanaText]
links: [(main, uri)]
index_key: str
tips
with nodes.reprunicode, jinja2 thinks the object is a string.
variables
term: KanaText OBJect. it had better to be ‘ktobj’ vaiable name.
rawword: ex. ‘かな|言葉^11’
rawtext: ex. ‘かな|言葉^11’, ‘かな|言葉^11; いい|壱壱^11’ or ‘かな|言葉^11; …; …’
rawsouce: means Element.rawsource.
text: the string ‘かな|言葉’ of ‘かな|言葉^11’, by object.astext() of KanaText.
hier: the string ‘言葉’ of ‘かな|言葉^11’, by object.ashier() which means hieroglyph.
kana: the string ‘かな’ of ‘かな|言葉^11’. by object.askana()
ruby: ex. [(True, (‘田’, ‘た’)), (True, (‘中’, ‘なか’))]
html: ex. ‘<ruby><rb>言葉</by><rp></rp><rt>かな</rt><rp></rp></ruby>’
latex: (T.B.D.)
epub: (T.B.D.)
separator: used by re.split()
delimiter: used by object.astext(), etc.
option_marker: the ‘^’ of ‘かな|言葉^11’
methods
ashier: return a string like hieroglyph
astext: return a string like a eacy identifier
askana: return a string which is reading
asruby: return a list data for the display with ruby. for genindex.html.
ashtml: return a string which is made with html tags. for document.html which has glossary.
__eq__: return a string by astext, to be identified easily, for unittest
__str__: return a string by ashier, for jinja2
relations
KanaText: Text
KanaTextUnit: TextUnit(T.B.D.) which is a entry(type, value, tid, main, index_key)
IndexUnit: classifier and index entry(word, subword, …, index_key)
IndexRank: something which interpres between IndexUnit and genindex.html
KanaText(ex. ‘かな|言葉^11’)
object[0]: ‘言葉’
object[1]: ‘かな’
object[‘delimiter’]: ‘|’
object[‘ruby’]: ‘specific’
object[‘option’]: ‘11’
object.whatiam: in(‘classifier’, ‘term’:default, ‘subterm’)
object.__eq__: used by unittest and IndexRack.generate_genindex_data
object.__str__: used by jinja2. use object.whatiam
KanaTextUnit(ex. ‘ああ|壱壱^11; いい|弐弐^11; うう|参参^11’)
object[0]: KanaText(‘ああ|壱壱^11’)
object[1]: KanaText(‘いい|弐弐^11’)
object[2]: KanaText(‘うう|参参^11’)
object[‘entry_type’]: ‘single’, ‘pair’, ‘triple’, ‘see’ or ‘seealso’
object[‘file_name’]: file name
object[‘target’]: target id
object[‘main’]: ‘main’ or ‘’
object[‘index_key’]: None or classifier
object.make_IndexUnit(): return [IndexUnit, IndexUnit, …]
TextUnit(T.B.D.)
object[0]: Text(rawtext)
object[1]: Text(rawtext)
object[2]: Text(rawtext)
object[‘entry_type’]: ‘single’, ‘pair’, ‘triple’, ‘see’ or ‘seealso’
object[‘file_name’]: a file name
object[‘target’]: a target id
object[‘main’]: ‘main’ or ‘’
object[‘index_key’]: None or classifier
object.make_index_unit(): return [IndexUnit, IndexUnit, …]
IndexRack
object[n]: IndexUnit(…)
object.append(): make/update classifier_catalog and kana_katalog
object.extend(): call the object.append() by each IndexUnit object
object.udpate(): update IndexUnit object with classifier_catalog and kana_catalog
object.sort(): to be sorted
object.generate_genindex_data()
IndexUnit
object._sortkey: for emphasis which means ‘main’.
object[0]: KanaText(classifier)
object[1]: KanaText(main term)
object[2]: SubTerm([], [KanaText(2nd)], or [KanaText(2nd), KanaText(3rd)])
object[3]: emphasis code (‘main’: 3, ‘’: 5, ‘see’: 8, ‘seealso’: 9)
object[‘file_name’]: target file
object[‘target’]: target id
object[‘main’]: emphasis
object[‘index_key’]: None or classifier
object.delimiter: ‘ ‘ or ‘, ‘
object.get_children: [object[1], object[2][0], object[2][1]]
SubTerm
object[0]: KanaText
object[1]: KanaText
object._delimiter
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file sphinxcontrib.kana_text-0.25.0.tar.gz.
File metadata
- Download URL: sphinxcontrib.kana_text-0.25.0.tar.gz
- Upload date:
- Size: 19.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.2 importlib_metadata/4.6.4 pkginfo/1.7.1 requests/2.24.0 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.8.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6a78433f12c48b3b6e32ad958fe03f797d31d97aec5b8ea7b20c8daeb1d211d0
|
|
| MD5 |
b028c8ff04c98bc99947c93291780b0c
|
|
| BLAKE2b-256 |
3e9b326c1d597f558063e2bb23f4a8b5a8b8d8a092bdc4e1bf78c4ae75836311
|







