Datasets and evaluation from the Spatial Reasoning with Denoising Models paper

Project description
SRM Benchmarks






Benchmark datasets and evaluation metrics for testing spatial reasoning in image generative models.
Used in the ICML 2025 paper: Spatial Reasoning with Denoising Models
Features:
- Three challenging datasets (MNIST Sudoku, Even Pixels, Counting Objects)
- Automated evaluation metrics
- Automatic dataset download from Hugging Face

Table of Contents
Installation
From PyPI
pip install srmbench
From source
git clone https://github.com/spatialreasoners/srmbench.git
cd srmbench
pip install -e .
Development installation
git clone https://github.com/spatialreasoners/srmbench.git
cd srmbench
pip install -e ".[dev]"
Datasets
SRM Benchmarks provides three main datasets for evaluating spatial reasoning capabilities in generative models. Each dataset tests different aspects of spatial understanding and constraint satisfaction.
🧩 MNIST Sudoku

Challenge: Inpaint the image by filling the missing cells with MNIST digits where no digit repeats in any row, column, or 3×3 subgrid.
What the model needs to understand:
- Digit recognition: Understanding and generating MNIST digits correctly [easy]
- Spatial relationships: Row, column, and subgrid uniqueness [hard]
Dataset Details:
- Image size: 252×252 pixels (9×9 grid of 28×28 MNIST digits)
- Format: Grayscale images with corresponding masks
- Masks: Indicate which cells are given (white) vs. need to be filled (black)
- Difficulty: Configurable via
min_given_cellsandmax_given_cellsparameters
Evaluation Metrics:
is_valid_sudoku: Boolean indicating valid Sudoku (no duplicates in any row/column/subgrid)duplicate_count: Number of constraint violations (0 = perfect)
🎨 Even Pixels
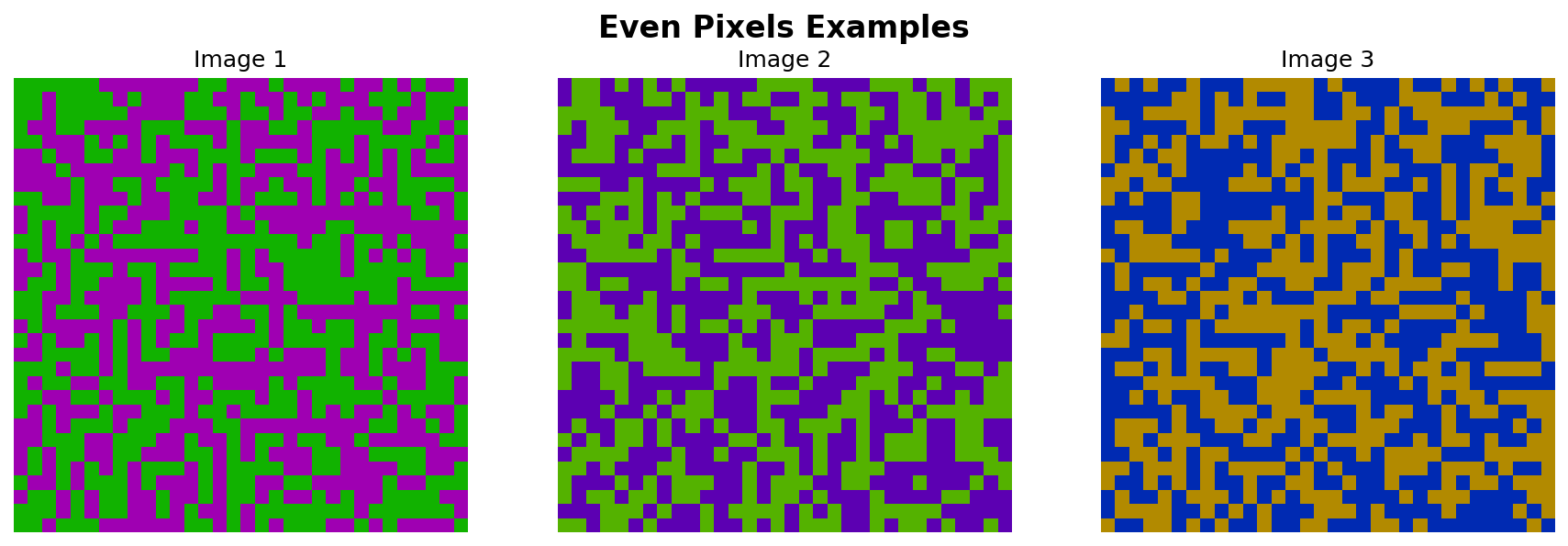
Challenge: Generate images where exactly 50% of pixels are one color and 50% are another color, with uniform saturation and brightness.
What the model needs to understand:
- Color choice: Choosing two colors that are opposite in the HSV color space [easy]
- Pixel-level counting: Precise balance between two colors [hard]
Dataset Details:
- Image size: 32×32 pixels
- Format: RGB images
- Color constraint: There are two colors in the image (with opposite hue values), randomly positioned, but the count of pixels for each color is exactly 50% of the total number of pixels.
Evaluation Metrics:
color_imbalance_count: Deviation from perfect 50/50 split (0 = perfect)is_color_count_even: Boolean for exact pixel balance (1.0 = perfect)saturation_std: Standard deviation of saturation (should be ~0)value_std: Standard deviation of brightness (should be ~0)
🔢 Counting Objects

Challenge: Generate images with the number of objects (polygons or stars) where the displayed numbers match the actual object counts.
What the model needs to understand:
- Consistency: All objects within an image have the same number of vertices (uniform constraint) [medium]
- Matching numbers: The displayed numbers match the actual object counts and number of vertices [hard]
Dataset Details:
- Image size: 128×128 pixels
- Format: RGB images with objects overlaid on FFHQ background faces
- Variants:
- Polygons: 3-7 sided polygons
- Stars: 2-9 pointed stars
- Numbers: Optional overlay showing object counts (via
are_nums_on_imagesparameter)
Evaluation Metrics:
are_vertices_uniform: Fraction where all objects have same vertex countnumbers_match_objects: Fraction where displayed numbers match actual counts- Additional, optional metrics:
relative_vertex_count_N: Fraction of images with N-vertex objects (Can show biases when averaged over larger number of images)relative_polygons_count_N: Fraction of images with N objects (Can show biases when averaged over larger number of images)
Quick Start
1. MNIST Sudoku Dataset
Training (Load Dataset):
import torch
from torch.utils.data import DataLoader
from torchvision.transforms import v2 as transforms
from srmbench.datasets import MnistSudokuDataset
# Define transforms for images and masks
image_mask_transform = transforms.Compose([
transforms.ToImage(),
transforms.ToDtype(torch.float32, scale=True), # Scales from [0,255] to [0,1]
transforms.Lambda(lambda x: x.squeeze(0)), # Remove channel dimension
])
# Create dataset with transforms
dataset = MnistSudokuDataset(
stage="train", # or "test"
transform=image_mask_transform,
mask_transform=image_mask_transform
)
# Create DataLoader
dataloader = DataLoader(
dataset,
batch_size=8,
shuffle=True,
num_workers=4,
)
# Training loop
for images, masks in dataloader:
# Apply mask and train your model to reconstruct
# masked_images = images * masks # Keep given cells
# reconstructed = your_model_inpainting_function(masked_images, masks)
# loss = loss_fn(reconstructed, images)
pass
Evaluation:
from srmbench.evaluations import MnistSudokuEvaluation
evaluation = MnistSudokuEvaluation()
# Evaluate your model's generated images
for images, masks in dataloader:
masked_images = images * masks
generated_images = your_model_inpainting_function(masked_images, masks)
results = evaluation.evaluate(generated_images)
print(f"Valid Sudoku: {results['is_valid_sudoku'].float().mean():.2%}")
print(f"Avg Duplicate Count: {results['duplicate_count'].float().mean():.2f}")
2. Even Pixels Dataset
Training (Load Dataset):
import torch
from torch.utils.data import DataLoader
from torchvision.transforms import v2 as transforms
from srmbench.datasets import EvenPixelsDataset
# Define transform: PIL RGB (H, W, 3) -> Tensor (3, H, W) in [-1, 1]
transform = transforms.Compose([
transforms.ToImage(),
transforms.ToDtype(torch.float32, scale=True), # Scales from [0,255] to [0,1]
transforms.Lambda(lambda x: x * 2.0 - 1.0), # Normalize to [-1,1]
])
# Create dataset with transforms
dataset = EvenPixelsDataset(stage="train", transform=transform) # or "test"
# Create DataLoader
dataloader = DataLoader(
dataset,
batch_size=8,
shuffle=True,
num_workers=4,
)
# Training loop
for images in dataloader:
# Train your generative model
# generated = model(noise)
# loss = loss_fn(generated, images)
pass
Evaluation:
from srmbench.evaluations import EvenPixelsEvaluation
evaluation = EvenPixelsEvaluation()
# Generate and evaluate images from your model
images_batch = your_model_generation_function(batch_size=8)
results = evaluation.evaluate(images_batch)
print(f"Saturation STD: {results['saturation_std']:.4f}")
print(f"Value STD: {results['value_std']:.4f}")
print(f"Color Imbalance: {results['color_imbalance_count']:.0f} pixels")
print(f"Perfect Balance: {results['is_color_count_even']:.2%}")
3. Counting Objects Dataset
Training (Load Dataset):
import torch
from torch.utils.data import DataLoader
from torchvision.transforms import v2 as transforms
from srmbench.datasets import CountingObjectsFFHQ
# Define transform: PIL RGB (H, W, 3) -> Tensor (3, H, W) in [-1, 1]
transform = transforms.Compose([
transforms.ToImage(),
transforms.ToDtype(torch.float32, scale=True), # Scales from [0,255] to [0,1]
transforms.Lambda(lambda x: x * 2.0 - 1.0), # Normalize to [-1,1]
])
# Create dataset with transforms (polygons or stars variant)
dataset = CountingObjectsFFHQ(
stage="train", # or "test"
object_variant="polygons", # or "stars"
transform=transform,
)
# Create DataLoader
dataloader = DataLoader(
dataset,
batch_size=8,
shuffle=True,
num_workers=4,
)
# Training loop
for images in dataloader:
# Train your generative model
# generated = model(noise)
# loss = loss_fn(generated, images)
pass
Evaluation:
from srmbench.evaluations import CountingObjectsEvaluation
# Set device="cpu" if no GPU available
evaluation = CountingObjectsEvaluation(object_variant="polygons", device="cpu")
# Generate and evaluate images from your model
images_batch = your_model_generation_function(batch_size=8)
results = evaluation.evaluate(images_batch, include_counts=True)
print(f"Vertices Uniform: {results['are_vertices_uniform']:.2%}")
print(f"Numbers Match Objects: {results['numbers_match_objects']:.2%}")
The basic examples in runnable variants are available in the examples directory.
python examples/mnist_sudoku_example.py
python examples/even_pixels_example.py
python examples/counting_objects_example.py
License
This project's code is licensed under the MIT License - see the LICENSE file for details. The benchmark datasets included in this package are subject to their respective licenses:
MNIST Sudoku Dataset
Counting Objects Dataset
- FFHQ Dataset:
- Individual images: Various licenses (Creative Commons BY 2.0, BY-NC 2.0, Public Domain Mark 1.0, Public Domain CC0 1.0, U.S. Government Works)
- Dataset compilation by NVIDIA: Creative Commons BY-NC-SA 4.0
- Reference: FFHQ GitHub Repository
- Roboto Font: Apache License 2.0
Note: When using this package, please ensure compliance with the respective dataset licenses, particularly for commercial use. The FFHQ dataset is generally restricted to non-commercial purposes under the CC BY-NC-SA 4.0 license.
Running tests
pytest
Citation
If you use this package in your research, please cite:
@inproceedings{wewer25srm,
title = {Spatial Reasoning with Denoising Models},
author = {Wewer, Christopher and Pogodzinski, Bartlomiej and Schiele, Bernt and Lenssen, Jan Eric},
booktitle = {International Conference on Machine Learning ({ICML})},
year = {2025},
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file srmbench-1.0.1.tar.gz.
File metadata
- Download URL: srmbench-1.0.1.tar.gz
- Upload date:
- Size: 29.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cd40154d14ff6aa44865e6fbdb3d87f92e4a3280b3469d9281cfdbecff421704
|
|
| MD5 |
e31e4f7ce525f7cf83c7bfe486dc21da
|
|
| BLAKE2b-256 |
73773db646d3be22f65d134aef79800fe3dfdef7a6ff5b166638c882b022b9b4
|
File details
Details for the file srmbench-1.0.1-py3-none-any.whl.
File metadata
- Download URL: srmbench-1.0.1-py3-none-any.whl
- Upload date:
- Size: 27.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9a9ee75499315b34bb912ce5aa64a54067126ee3b233bd26c879b3afe20143e3
|
|
| MD5 |
f63e013cf2239a597adf8b4690bfafa2
|
|
| BLAKE2b-256 |
157c81c2c7a84867504a8b661932c1687e726241407c0de2f1102396baf88de3
|







