Slurm job workflow management

Project description

srunx
A unified CLI, web dashboard, and Python API for SLURM job management.
Stop juggling sbatch scripts, squeue loops, and SSH sessions.






- Submit & manage SLURM jobs from CLI, browser, or Python
- Orchestrate multi-step workflows with YAML and dependency graphs
- Monitor GPU availability and job states with Slack notifications
- SSH remote — submit jobs, sync files, and browse remote clusters from your laptop
- Container-native — Pyxis, Apptainer, and Singularity support built in
Installation
Requires Python 3.12+ and access to a SLURM cluster (local or via SSH).
uv add srunx # with uv (recommended)
pip install srunx # or with pip
The web dashboard and Slack notifications are included in the base install — no extras required.
For AI agent integration (MCP server), add the mcp extra:
uv add "srunx[mcp]"
Quick Start
Submit a job, wait for it, and view the logs — end to end:
# 1. Submit (use -- to separate srunx flags from the command)
$ srunx submit --name training --gpus-per-node 2 --conda ml_env -- python train.py
✅ Submitted job training (id=847291)
# 2. Follow until completion
$ srunx monitor jobs 847291
⠋ 847291 training PENDING → RUNNING → COMPLETED (4m 12s)
# 3. Inspect output
$ srunx logs 847291 -n 20
Or describe the whole pipeline once and let srunx drive it:
srunx flow run workflow.yaml
Why srunx?
Instead of stitching together sbatch, squeue, SSH, and a pipeline runner, srunx offers one coherent surface that covers the day-to-day SLURM loop.
| Capability | srunx | submitit | simple-slurm | Snakemake |
|---|---|---|---|---|
| CLI for submit / status / cancel | ✅ | ❌ | ❌ | ⚠️ partial |
| Python API | ✅ | ✅ | ✅ | ✅ |
| Web dashboard | ✅ | ❌ | ❌ | ❌ |
| Workflow DAG with dependencies | ✅ | ❌ | ❌ | ✅ |
| Inter-job value passing (load-time) | ✅ | ❌ | ❌ | ⚠️ via files |
| Matrix parameter sweeps | ✅ | ⚠️ manual | ❌ | ⚠️ via wildcards |
| GPU availability monitoring | ✅ | ❌ | ❌ | ❌ |
| SSH remote submit + file sync | ✅ | ❌ | ❌ | ❌ |
| Container support (Pyxis / Apptainer / Singularity) | ✅ | ⚠️ limited | ❌ | ⚠️ via rules |
| Slack notifications | ✅ | ❌ | ❌ | ⚠️ plugin |
If you need full-featured scientific workflow tooling, Snakemake / Nextflow are still the right call. srunx targets the sweet spot of "SLURM + a few dependencies + a nice UI" without Airflow-scale infrastructure.
CLI
| Command | Description |
|---|---|
srunx submit |
Submit a SLURM job |
srunx status |
Check job status |
srunx list |
List jobs in queue |
srunx cancel |
Cancel a job |
srunx logs |
View / stream job logs |
srunx resources |
Display GPU availability |
srunx monitor |
Monitor jobs, resources, or cluster |
srunx flow |
Run / validate YAML workflows |
srunx flow run --arg KEY=VALUE |
Override workflow args from the CLI |
srunx flow run --sweep KEY=V1,V2 --max-parallel N |
Ad-hoc matrix parameter sweep |
srunx ssh |
Remote SLURM operations over SSH |
srunx history |
Show job execution history |
srunx report |
Generate job execution report |
srunx config |
Manage configuration |
srunx template |
Manage job templates |
srunx ui |
Launch the web dashboard |
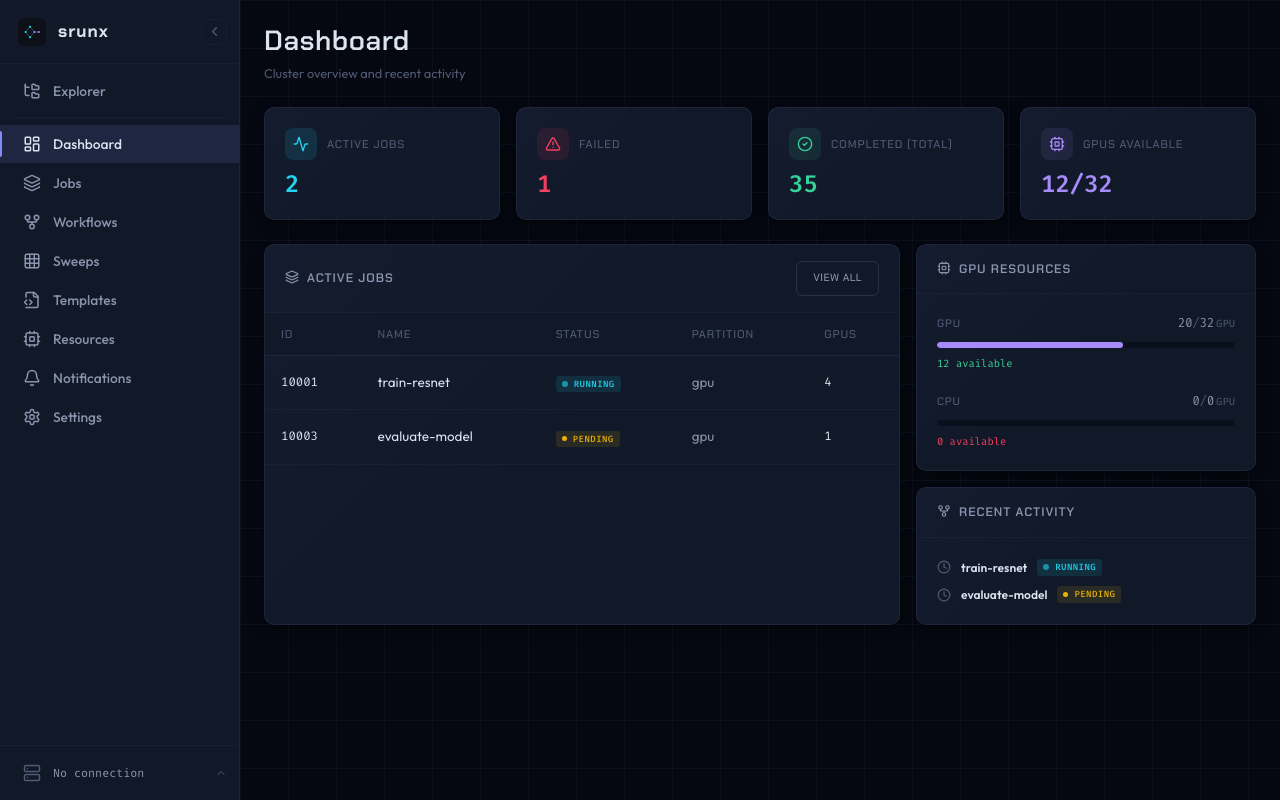
Web Dashboard
A dashboard for visual cluster management. Connect to your SLURM cluster over SSH and manage jobs, workflows, and resources from a browser.
srunx ui # -> http://127.0.0.1:8000
srunx ui --port 3000 # custom port
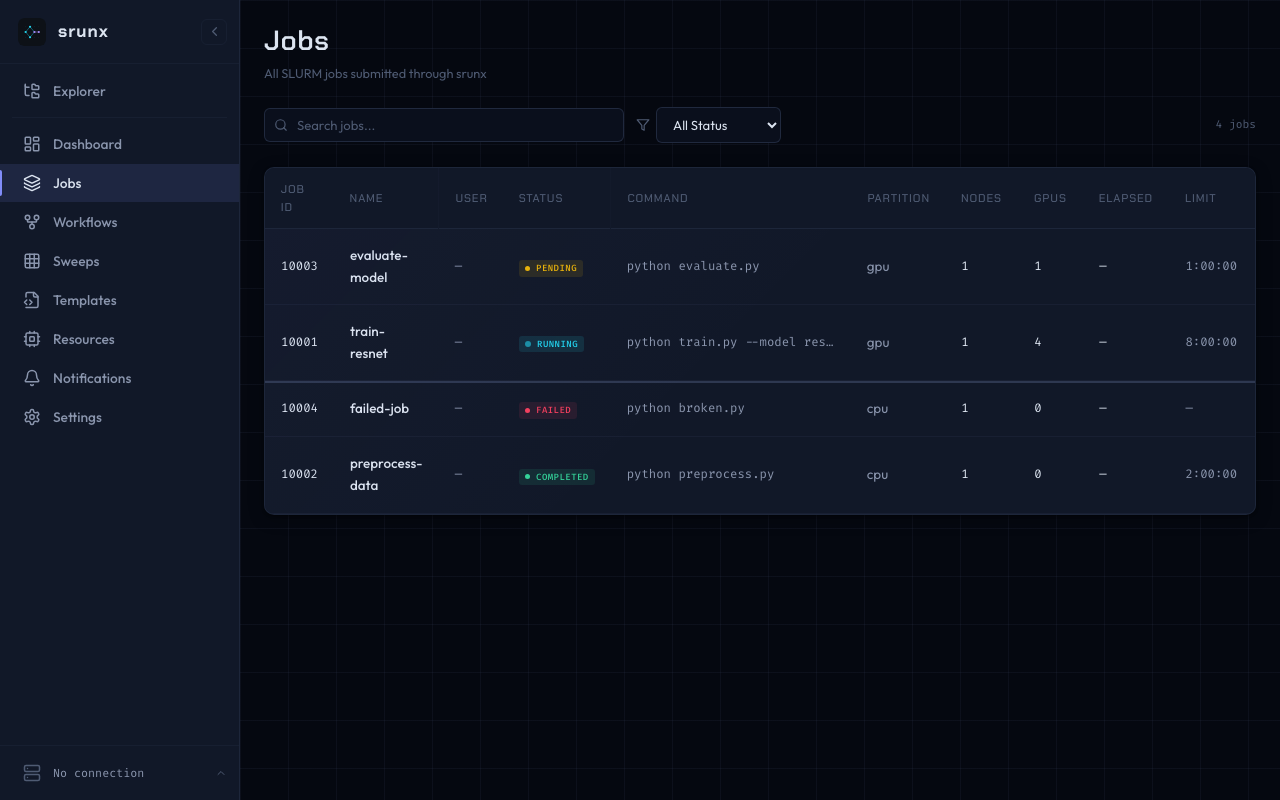
Jobs
Browse, search, filter, and cancel jobs.
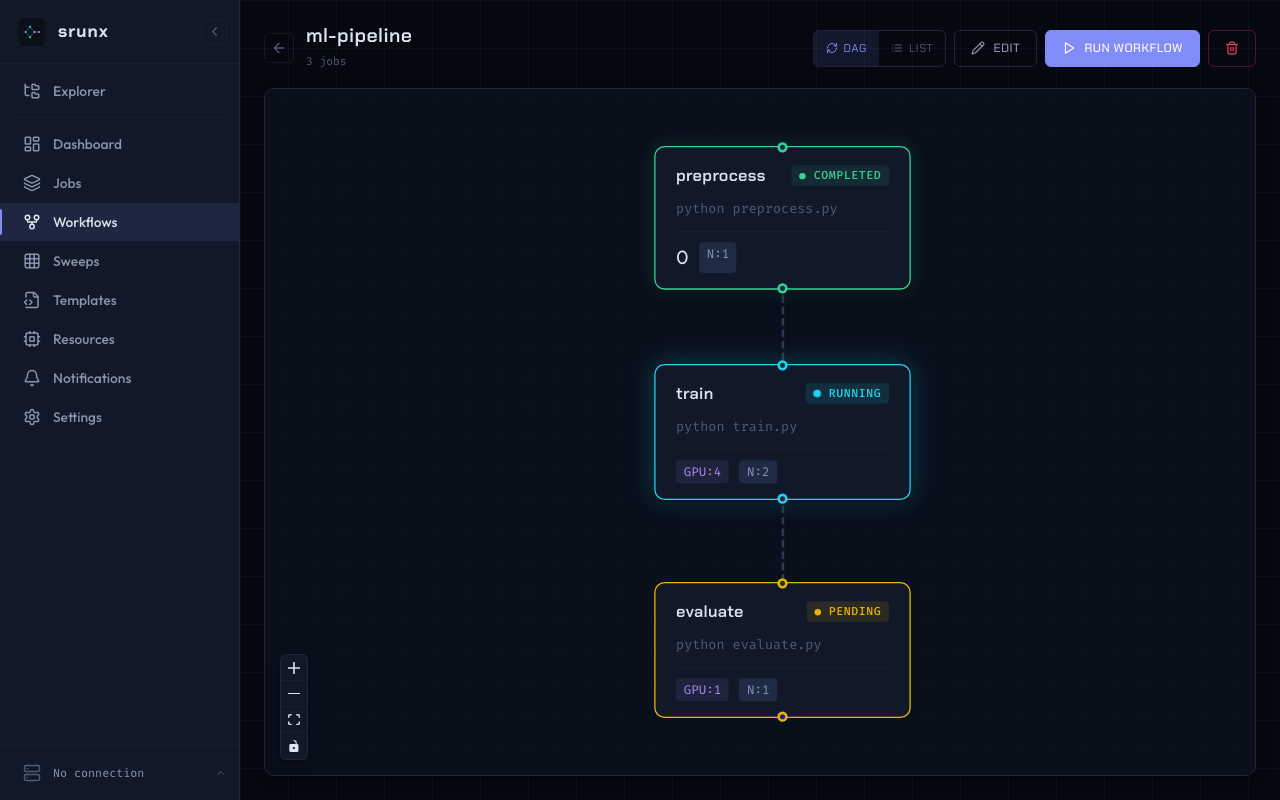
Workflow DAG
Visualize job dependencies. Run workflows directly from the UI.
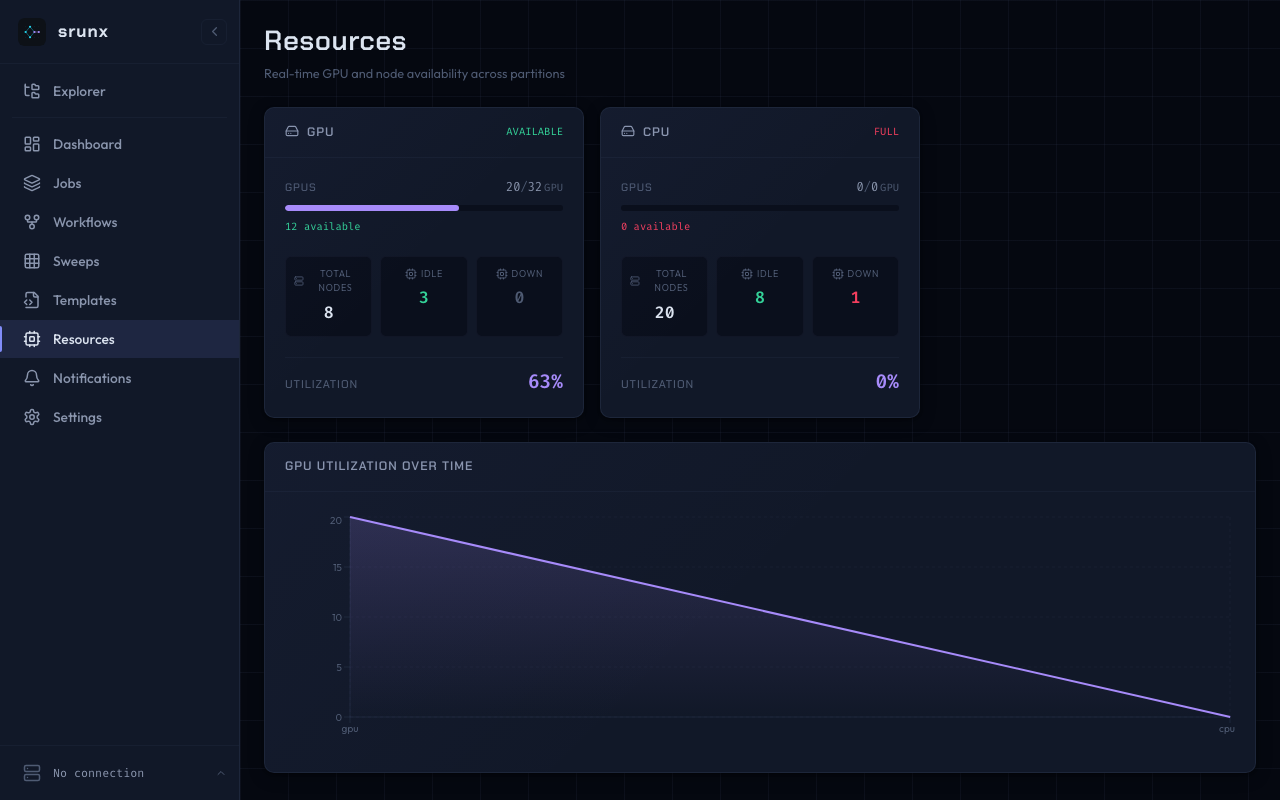
Resources
GPU and node availability per partition.
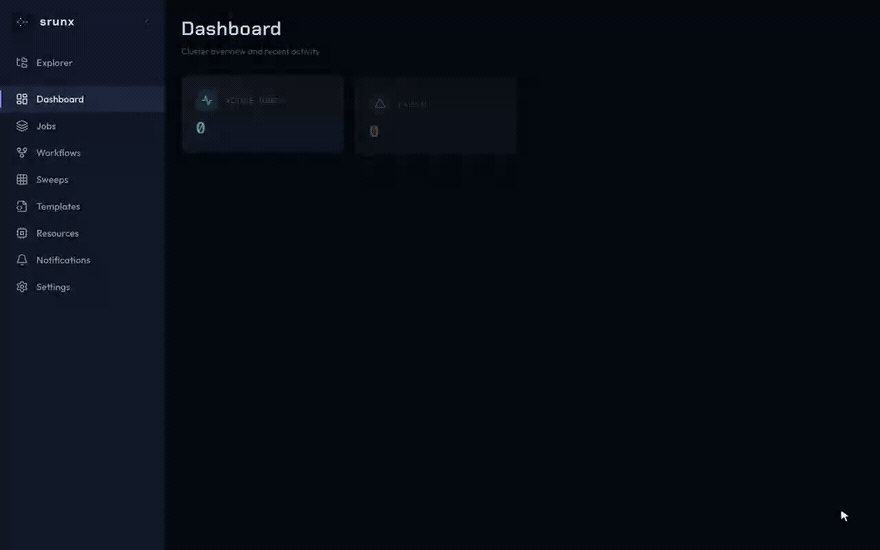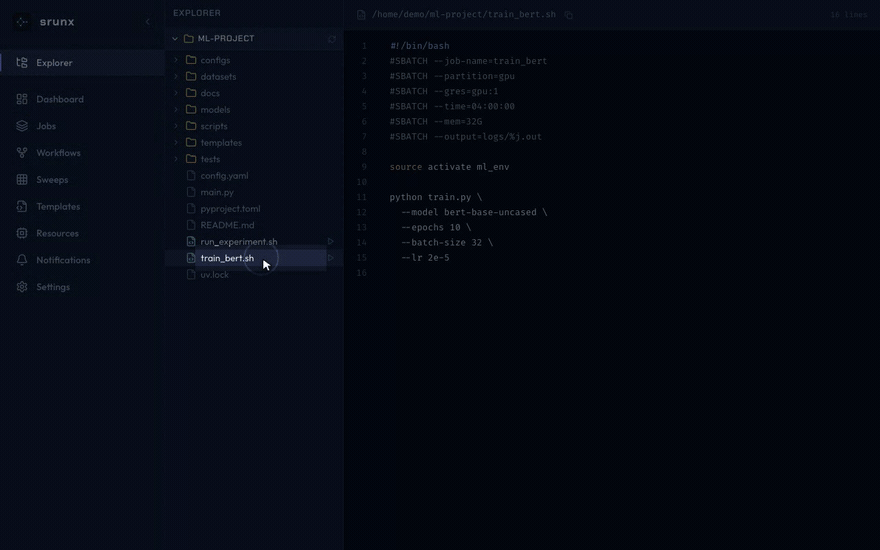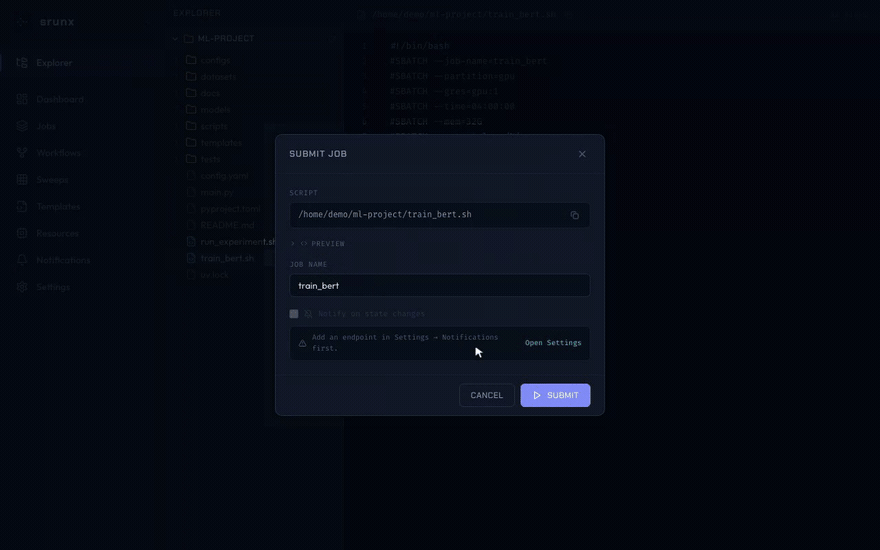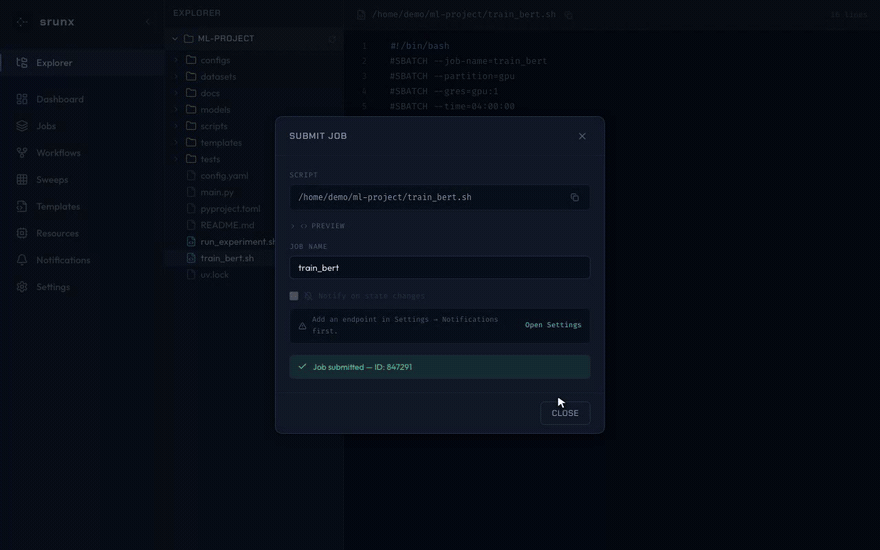
Explorer
Browse remote files via SSH mounts. Shell scripts can be submitted as sbatch jobs directly from the file tree.
Workflow Orchestration
Define pipelines in YAML. Jobs run as soon as their dependencies complete — independent branches execute in parallel automatically.
name: experiment
args:
model: "bert-base-uncased"
output_dir: "/outputs/{{ model }}"
jobs:
- name: preprocess
command: ["python", "preprocess.py", "--out", "{{ output_dir }}/data"]
exports:
DATA_PATH: "{{ output_dir }}/data/processed.parquet"
- name: train
command: ["python", "train.py", "--model", "{{ model }}", "--data", "{{ deps.preprocess.DATA_PATH }}"]
depends_on: [preprocess]
gpus_per_node: 2
environment:
container:
image: nvcr.io/nvidia/pytorch:24.01-py3
mounts:
- /data:/data
exports:
MODEL_PATH: "{{ output_dir }}/models/best.pt"
- name: evaluate
command: ["python", "eval.py", "--model", "{{ deps.train.MODEL_PATH }}"]
depends_on: [train]
What this shows off:
argswith Jinja2 — reusable, parameterized pipelines ({{ model }},{{ output_dir }})- Inter-job exports — parents declare
exports:; children read them via{{ deps.<parent>.<key> }}, fully resolved at workflow load time (no runtime env files) - Containers per job — Pyxis / Apptainer / Singularity are first-class (
environment.container) - Dependency-driven scheduling —
evaluateblocks ontrain; parallel branches run automatically
Run it:
srunx flow run workflow.yaml # execute
srunx flow run workflow.yaml --dry-run # show plan only
srunx flow run workflow.yaml --from train # resume / partial execution
Retry with retry: N and retry_delay: <seconds> per job.
Parameter Sweeps
Run the same workflow across a matrix of hyperparameters without copying YAML. Each cell materializes into its own sbatch submission and is tracked independently.
name: train
args:
lr: 0.01
seed: 1
sweep:
matrix:
lr: [0.001, 0.01, 0.1]
seed: [1, 2, 3]
fail_fast: false
max_parallel: 4
jobs:
- name: train
command: ["python", "train.py", "--lr", "{{ lr }}", "--seed", "{{ seed }}"]
gpus_per_node: 1
Run it — or declare the axes ad-hoc on the command line:
srunx flow run train.yaml # YAML-declared sweep
srunx flow run --sweep lr=0.001,0.01 --max-parallel 2 train.yaml # ad-hoc
srunx flow run --sweep lr=0.001,0.01 --max-parallel 2 --dry-run train.yaml
Sweeps are a first-class concept across CLI, Web UI, and MCP. Web-triggered sweeps route cells through a bounded SlurmSSHExecutorPool against the configured SSH profile, while CLI and MCP runs use the local SLURM client by default. The Web UI surfaces per-cell progress with ETA, filter / sort, and per-cell cancellation.
Monitoring
# Monitor a job until completion
srunx monitor jobs 12345
# Wait for GPUs, then submit
srunx monitor resources --min-gpus 4
srunx submit python train.py --gpus-per-node 4
# Periodic cluster reports to Slack
srunx monitor cluster --schedule 1h --notify $SLACK_WEBHOOK
Remote SSH
Keep your local editor workflow while running on the cluster:
# Submit to remote cluster
srunx ssh submit train.py --host dgx-server
# Manage connection profiles
srunx ssh profile add myserver --ssh-host dgx1
# Map local directories to remote and sync with rsync
srunx ssh profile mount add myserver workspace \
--local ~/projects/ml-exp --remote /home/user/ml-exp
srunx ssh sync
- SSH config hosts, saved profiles, and proxy jump support
- Environment variable passthrough (
--env KEY=VALUE,--env-local WANDB_API_KEY) - File sync via rsync — auto-detects profile from current directory
Slack Notifications
Get notified when jobs finish — set SLACK_WEBHOOK_URL (or configure it in the web dashboard), then append --slack to any srunx flow run command. In Python, pass SlackCallback to the runner (see the Python API section below).
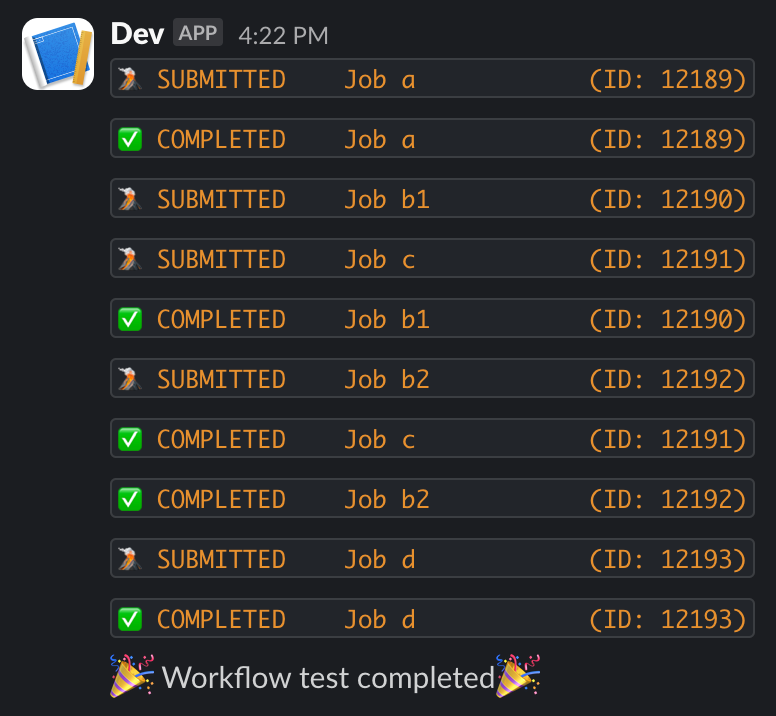
export SLACK_WEBHOOK_URL="https://hooks.slack.com/services/..."
srunx flow run workflow.yaml --slack
MCP Server
srunx ships an MCP server so Claude Code (and other MCP clients) can submit jobs, inspect the queue, and drive workflows over stdio. Install the extra and register the server with your client:
uv add "srunx[mcp]"
srunx-mcp # launch the stdio server directly
# Or register with Claude Code in one shot
claude mcp add --scope user srunx -- uvx --from 'srunx[mcp]' srunx-mcp
Once connected, the agent can call run_workflow with optional sweep and mount parameters:
run_workflow(
yaml_path="train.yaml",
sweep={"matrix": {"lr": [0.001, 0.01]}, "max_parallel": 2},
mount="my-project",
)
Passing mount=<name> routes the run through the matching SSH profile mount, translating work_dir / log_dir into remote paths — so the agent can launch mount-aware submissions against a remote cluster without leaving the chat.
Python API
The full CLI surface is available as a Python library. Use it inside notebooks, existing Python pipelines, or custom tooling.
Submit and wait:
from srunx import Job, JobResource, JobEnvironment, Slurm
job = Job(
name="training",
command=["python", "train.py"],
resources=JobResource(nodes=1, gpus_per_node=2, time_limit="4:00:00"),
environment=JobEnvironment(conda="ml_env"),
)
client = Slurm()
completed = client.run(job) # submit, poll, and return when terminal
print(completed.status, completed.job_id)
Fire-and-track:
submitted = client.submit(job) # returns Job with job_id populated
info = client.retrieve(submitted.job_id) # poll status on demand
client.cancel(submitted.job_id) # if you change your mind
Run a YAML workflow programmatically, with callbacks:
from srunx.callbacks import SlackCallback
from srunx.runner import WorkflowRunner
runner = WorkflowRunner.from_yaml(
"workflow.yaml",
callbacks=[SlackCallback(webhook_url="...")],
)
runner.run() # blocks until the DAG finishes
Documentation
Full documentation at ksterx.github.io/srunx.
Development
git clone https://github.com/ksterx/srunx.git
cd srunx
uv sync --dev
# Full pre-commit quality gate
uv run pytest && uv run mypy . && uv run ruff check .
Contributions welcome — please open an issue or PR on GitHub.
License
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file srunx-1.2.1.tar.gz.
File metadata
- Download URL: srunx-1.2.1.tar.gz
- Upload date:
- Size: 808.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
02dcce717d3a1853580ad1523a4506b3e8e2e7fb08f8cfeededc5bcb610b8fa2
|
|
| MD5 |
5efe6f09b147e7550001e338b1496cf1
|
|
| BLAKE2b-256 |
bb07d44fe6652f1f0aa6c0ba80474f60a12948e3608a8148ec1bee160b958fd2
|
File details
Details for the file srunx-1.2.1-py3-none-any.whl.
File metadata
- Download URL: srunx-1.2.1-py3-none-any.whl
- Upload date:
- Size: 753.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c23d37625f356f0f47defeb69c7a2fd2ab4a11ca98fc7a778092c4ad4c9799f0
|
|
| MD5 |
920059f11d37f8e144a4f2ce807a4225
|
|
| BLAKE2b-256 |
ceb57420f171b95798c1778f70dea9a71e0f618bb15381de51aedf31b2a45523
|







