Starlake Python Distribution For orchestration

Project description
Starlake Orchestration
What is Starlake?
Starlake is a configuration-driven platform designed to simplify Extract, Load, and Transform (ELT) operations while supporting declarative orchestration of data pipelines. By minimizing coding requirements, it empowers users to create robust data workflows with YAML-based configurations.
Typical Use Case
- Extract: Gather data from sources such as Fixed Position files, DSV (Delimiter-Separated Values), JSON, or XML formats.
- Define or infer structure: Use YAML to describe or infer the schema for each data source.
- Load: Configure and execute the loading process to your data warehouse or other sinks.
- Transform: Build aggregates and join datasets using SQL, Jinja, and YAML configurations.
- Output: Observe your data becoming available as structured tables in your data warehouse.
Flexibility Across Workflows
Starlake supports any or all steps in your data pipeline, allowing for seamless integration into existing workflows:
- Extract : Export selective data from SQL databases into CSV files.
- Preload: Evaluate whether the loading process should proceed, based on a configurable preload strategy.
- Load : Ingest FIXED-WIDTH, CSV, JSON, or XML files, converting them into strongly-typed records stored as Parquet files, data warehouse tables (e.g., Google BigQuery), or other configured sinks.
- Transform : Join loaded datasets and save them as Parquet files, data warehouse tables, or Elasticsearch indices.
What is Starlake orchestration?
Starlake Orchestration is a Python-based API for creating, scheduling and managing data pipelines. It abstracts the complexities of various orchestration platforms (e.g., Apache Airflow , Dagster), offering a unified interface for pipeline orchestration.
Starlake Orchestration aligns with Starlake's philosophy by abstracting orchestration complexities into a simple, unified Python-based API.
It is recommended to use it in combinaison with starlake dag generation, but can be used directly as is in your DAGs.
Key Features
1. Multi-Orchestrator Support
Starlake Orchestration integrates seamlessly with frameworks like Apache Airflow and Dagster, letting you select the best fit for your requirements.
2. Write Once, Deploy Anywhere
Design your pipelines once and execute them seamlessly across diverse orchestrators and environments—without rewriting code. Starlake ensures consistent pipeline definitions, whether you are using Dagster or Airflow on Google Cloud Platform ( GCP ), Amazon Web Services ( AWS ), or on-prem. Run Starlake jobs effortlessly using GCP Cloud Run , GCP Dataproc , AWS Fargate , or even simple shell scripts . This flexibility empowers teams to:
- Transition seamlessly between execution environments.
- Integrate with cloud-native or on-premises orchestration tools.
- Simplify deployments without compromising functionality or performance.
3. Data Freshness and Scheduling
Starlake Orchestration supports flexible scheduling mechanisms, ensuring your data pipelines deliver up-to-date results:
- Cron-based Scheduling : Automate periodic pipeline runs (e.g., "Run at 2 AM daily").
- Event-Driven Orchestration : Dynamically trigger pipelines using dataset-aware DAGs, ensuring dependencies and lineage are respected.
By leveraging data lineage and dependencies, Starlake Orchestration aligns schedules automatically, ensuring the freshness of interconnected datasets.
4. Simplified Management
With automated schedule alignment and dependency management, Starlake Orchestration eliminates manual adjustments and simplifies pipeline workflows, while maintaining reliability.
What are the main components of Starlake Orchestration?
Starlake Orchestration provides a modular and extensible framework for creating, scheduling, and managing data pipelines. Below are the primary components and their roles within the orchestration system:
1. IStarlakeJob
ai.starlake.job.IStarlakeJob serves as the generic factory interface for creating orchestration tasks. These tasks execute the appropriate Starlake CLI commands, allowing seamless integration with orchestration platforms.
Key Methods
sl_orchestrator
Returns the orchestrator type (e.g., StarlakeOrchestrator.AIRFLOW) for a concrete implementation. This is critical for the OrchestrationFactory to instantiate the correct AbstractOrchestration.
@classmethod
def sl_orchestrator(cls) -> Union[StarlakeOrchestrator, str]:
#...
sl_execution_environment
Returns the execution environment type (e.g., StarlakeExecutionEnvironment.SHELL) for a concrete implementation. This is critical for the StarlakeJobFactory to instantiate the correct IStarlakeJob.
@classmethod
def sl_execution_environment(cls) -> Union[StarlakeExecutionEnvironment, str]:
#...
sl_job
Creates orchestrator-specific tasks (e.g., Airflow BaseOperator or Dagster OpDefinition).
@abstractmethod
def sl_job(
self,
task_id: str,
arguments: list,
spark_config: StarlakeSparkConfig=None,
**kwargs) -> T:
#...
| name | type | description |
|---|---|---|
| task_id | str | the required task id |
| arguments | list | The required arguments of the starlake command to run |
| spark_config | StarlakeSparkConfig | the optional ai.starlake.job.StarlakeSparkConfig |
Factory Methods for Core Starlake Commands
Each method corresponds to a specific Starlake command.
Preload
Will generate the task that will run the starlake preload command.
def sl_pre_load(
self,
domain: str,
tables: set=set(),
pre_load_strategy: Union[StarlakePreLoadStrategy, str, None] = None,
**kwargs) -> Optional[T]:
#...
| name | type | description |
|---|---|---|
| domain | str | the domain to preload |
| tables | set | the optional tables to preload |
| pre_load_strategy | str | the optional preload strategy (self.pre_load_strategy by default) |
StarlakePreLoadStrategy
ai.starlake.job.StarlakePreLoadStrategy is an enumeration defining preload strategies for conditional domain loading.
Strategies:
- NONE
No condition applied; preload tasks are skipped.
- IMPORTED
Load only if files exist in the landing area (SL_ROOT/datasets/importing/{domain}).
- PENDING
Load only if files exist in the pending datasets area (SL_ROOT/datasets/pending/{domain}).
- ACK
Load only if an acknowledgment file exists at the configured path (global_ack_file_path).



Import
Generates the task for the import command.
def sl_import(
self,
task_id: str,
domain: str,
tables: set=set(),
**kwargs) -> T:
#...
| name | type | description |
|---|---|---|
| task_id | str | the optional task id ({domain}_import by default) |
| domain | str | the required domain to import |
| tables | set | the optional tables to import |
Load
Generates the task for the load command.
def sl_load(
self,
task_id: str,
domain: str,
table: str,
spark_config: StarlakeSparkConfig=None,
**kwargs) -> BaseOperator:
#...
| name | type | description |
|---|---|---|
| task_id | str | the optional task id ({domain}_{table}_load by default) |
| domain | str | the required domain of the table to load |
| table | str | the required table to load |
| spark_config | StarlakeSparkConfig | the optional ai.starlake.job.StarlakeSparkConfig |
Transform
Generates the task for the transform command.
def sl_transform(
self,
task_id: str,
transform_name: str,
transform_options: str=None,
spark_config: StarlakeSparkConfig=None, **kwargs) -> BaseOperator:
#...
| name | type | description |
|---|---|---|
| task_id | str | the optional task id ({transform_name} by default) |
| transform_name | str | the transform to run |
| transform_options | str | the optional transform options |
| spark_config | StarlakeSparkConfig | the optional ai.starlake.job.StarlakeSparkConfig |
2. StarlakeDataset
A ai.starlake.dataset.StarlakeDataset represents the metadata of a dataset produced by a task.
Starlake orchestration will collect all datasets produced by each task into a list of events to trigger per task.
At run time, the orchestrator will trigger subsequent events only if their corresponding tasks succeed.
3. StarlakeOptions
The ai.starlake.job.StarlakeOptions class provides methods to manage and retrieve configuration variables used within the context of a Directed Acyclic Graph (DAG). These variables include options passed to the DAG as a dictionary, environment variables, and other runtime configurations.
The following options are available for all concrete factory classes derived from IStarlakeJob:
| name | type | description |
|---|---|---|
| default_pool | str | pool of slots to use (default_pool by default) |
| sl_env_var | str | optional starlake environment variables passed as an encoded json string |
| retries | int | optional number of retries to attempt before failing a task (1 by default) |
| retry_delay | int | optional delay between retries in seconds (300 by default) |
| pre_load_strategy | str | one of none (default), imported, pending or ack |
| global_ack_file_path | str | path to the ack file ({SL_DATASETS}/pending/{domain}/{{{{ds}}}}.ack by default) |
| ack_wait_timeout | int | timeout in seconds to wait for the ack file(1 hour by default) |
These options allow you to customize the behavior of the pipeline and the orchestration tasks it defines, providing flexibility for retries, acknowledgment handling, and preload strategies.
4. Abstract Classes
AbstractDependency
Defines task dependencies, ensuring execution order in Directed Acyclic Graphs (DAGs). Operators such as >> and << allow intuitive chaining.
AbstractTask
Wraps concrete orchestration tasks (e.g., Airflow operators) into a unified interface.
AbstractTaskGroup
Groups related tasks into cohesive units, such as an Airflow TaskGroup or a Dagster GraphDefinition.
AbstractPipeline
Defines an entire pipeline, combining tasks and task groups. It handles:
- Task management : Adding and managing orchestrator-specific tasks.
- Dependency management : Ensuring the correct execution order.
AbstractOrchestration
The central abstraction for creating pipelines, tasks, and task groups. Orchestrator-specific implementations (e.g., for Airflow or Dagster) extend this class.
Critical Methods
sl_orchestrator: Returns the orchestrator type (e.g.,StarlakeOrchestrator.AIRFLOW). This is required for theOrchestrationFactoryto register the concrete orchestration classes dynamically.sl_create_pipeline: Creates a pipeline instance, such as an AirflowDAGor a DagsterJobDefinition.sl_create_task_group: Defines task groups for organizing related tasks, such as an AirflowTaskGroupor a DagsterGraphDefinition.
5. TaskGroupContext
A context manager responsible for:
- Tracking the current task group or pipeline context.
- Automatically adding tasks to the active group.
- Managing dependencies within the group.
6. OrchestrationFactory
Handles the dynamic registration and instantiation of concrete orchestration classes.
Features
- Maintains a registry of supported orchestrators.
- Dynamically creates
AbstractOrchestrationinstances based on the orchestrator type.
class OrchestrationFactory:
_registry = {}
_initialized = False
@classmethod
def register_orchestrations_from_package(cls, package_name: str = "ai.starlake") -> None:
"""
Dynamically load all classes implementing AbstractOrchestration from the given root package, including sub-packages,
and register them in the OrchestrationRegistry.
"""
...
@classmethod
def register_orchestration(cls, orchestration_class: Type[AbstractOrchestration]) -> None:
orchestrator = orchestration_class.sl_orchestrator()
if orchestrator is None:
raise ValueError("Orchestration must define a valid orchestrator")
cls._registry.update({orchestrator: orchestration_class})
@classmethod
def create_orchestration(cls, job: J, **kwargs) -> AbstractOrchestration[U, T, GT, E]:
if not cls._initialized:
cls.register_orchestrations_from_package()
cls._initialized = True
orchestrator = job.sl_orchestrator()
if orchestrator not in cls._registry:
raise ValueError(f"Unknown orchestrator type: {orchestrator}")
return cls._registry[orchestrator](job, **kwargs)
7. StarlakeJobFactory
Handles the dynamic registration and instantiation of concrete IStarlakeJob classes.
Features
- Maintains a registry of
IStarleJobconcrete classes per orchestrator and execution environment. - Dynamically creates
IStarleJobinstances based on the chosen orchestrator and execution environment types.
How to extend Starlake Orchestration?
1. Define a Starlake Job
Implement the IStarlakeJob interface to create a concrete factory class responsible for defining orchestrator-specific tasks.
-
Key Responsibilities:
- Implement
sl_orchestrator: Specify the orchestrator type (e.g.,airflow,dagster). - Implement
sl_execution_environment: Specify the execution environment type (e.g.,shell,cloud_run). - Implement
sl_job: Create tasks compatible with the orchestrator's API. - Override factory methods: Customize task creation for Starlake commands such as
preload,load,import, andtransform.
- Implement
-
Example Implementation:
from ai.starlake.job import IStarlakeJob
class MyStarlakeJob(IStarlakeJob):
def sl_orchestrator(cls) -> str:
return "my_orchestrator"
def sl_execution_environment(cls) -> str:
return "shell"
def sl_job(self, task_id: str, arguments: list, spark_config=None, **kwargs) -> MyOrchestratorTask:
# Orchestrator-specific implementation for creating a task
return MyOrchestratorTask(
task_id=task_id,
command_arguments=arguments,
**kwargs
)
2. Implement the Starlake Orchestration API
Extend AbstractOrchestration to integrate the new orchestrator's API and define the pipeline structure.
- Key Responsibilities :
- Pipeline Creation: Use
sl_create_pipelineto define the workflow using the orchestrator’s API. - Task Group Management: Implement
sl_create_task_groupto organize tasks into logical groups.
- Pipeline Creation: Use
Example :
class MyOrchestratorPipeline(AbstractPipeline):
...
class MyOrchestratorTaskGroup(AbstractTaskGroup):
...
class MyOrchestration(AbstractOrchestration):
def sl_orchestrator(cls) -> str:
return "my_orchestrator"
def sl_create_pipeline(self, schedule=None, dependencies=None, **kwargs) -> AbstractPipeline:
# Define pipeline using orchestrator's API
pipeline = MyOrchestratorPipeline(self.job, schedule=schedule, dependencies=dependencies, orchestration=self, **kwargs)
return pipeline
def sl_create_task_group(self, group_id: str, pipeline, **kwargs) -> AbstractTaskGroup[GT]:
# Create task group using orchestrator-specific API
return MyOrchestratorTaskGroup(name=group_id, pipeline=pipeline, **kwargs)
3. Register the Orchestration Class (optional)
Register the custom orchestration class with the OrchestrationFactory, making it available for pipeline execution.
- Example :
OrchestrationFactory.register_orchestration(MyOrchestration)
4. Create and Run the Pipeline
Use the extended Starlake API to define and execute your pipeline.
-
Steps:
- Instantiate a Starlake Job: Use the
StarlakeJobFactoryto create an instance of the customIStarlakeJob. - Create the Orchestration: Use the
OrchestrationFactoryto create an instance of the custom orchestrator. - Define the Pipeline: Add tasks and organize them using task groups.
- Instantiate a Starlake Job: Use the
-
Example Usage:
from ai.starlake.job import StarlakeJobFactory, StarlakeExecutionEnvironment
from ai.starlake.orchestration import StarlakeSchedule, StarlakeDomain, StarlakeTable, OrchestrationFactory
schedule =
StarlakeSchedule(
name='daily',
cron='0 0 * * *',
domains=[
StarlakeDomain(
name='starbake',
final_name='starbake',
tables=[
StarlakeTable(
name='Customers',
final_name='Customers'
),
StarlakeTable(
name='Ingredients',
final_name='Ingredients'
),
StarlakeTable(
name='Products',
final_name='Products'
)
]
)
]
)
# Define the job options
options = {}
import os
import sys
# Define the orchestrator type
orchestrator = "my_orchestrator"
# Define the execution environment
execution_environment = StarlakeExecutionEnvironment.SHELL
# Create a Starlake job instance
sl_job = StarlakeJobFactory.create_job(
filename=os.path.basename(__file__),
module_name=f"{__name__}",
orchestrator=orchestrator,
execution_environment=execution_environment,
options=options
)
# Create the Orchestration
with OrchestrationFactory.create_orchestration(job=sl_job) as orchestration:
# Define the pipeline
with orchestration.sl_create_pipeline(schedule=schedule) as pipeline:
# Add tasks and task groups
start = pipeline.start_task()
def generate_load_domain(domain: StarlakeDomain):
from ai.starlake.common import sanitize_id
with orchestration.sl_create_task_group(group_id=sanitize_id(domain.name), pipeline=pipeline) as ld:
def load_domain_tables():
with orchestration.sl_create_task_group(group_id=sanitize_id(f'load_{domain.name}'), pipeline=pipeline) as load_domain_tables:
for table in domain.tables:
pipeline.sl_load(
task_id=sanitize_id(f'load_{domain.name}_{table.name}'),
domain=domain.name,
table=table.name,
spark_config=pipeline.sl_spark_config(f'{domain.name}.{table.name}'.lower()),
params={'cron':schedule.cron},
)
return load_domain_tables
ld_tables=load_domain_tables()
return ld
load_domains = [generate_load_domain(domain) for domain in schedule.domains]
start >> load_domains
end = pipeline.end_task()
end << load_domains
return pipeline
What are the available Starlake Orchestration distributions?
Airflow
Starlake Airflow is the Starlake Python Distribution of Starlake orchestration for Airflow.
Starlake Airflow Installation
pip install starlake-orchestration[airflow] --upgrade
Starlake Airflow Load example
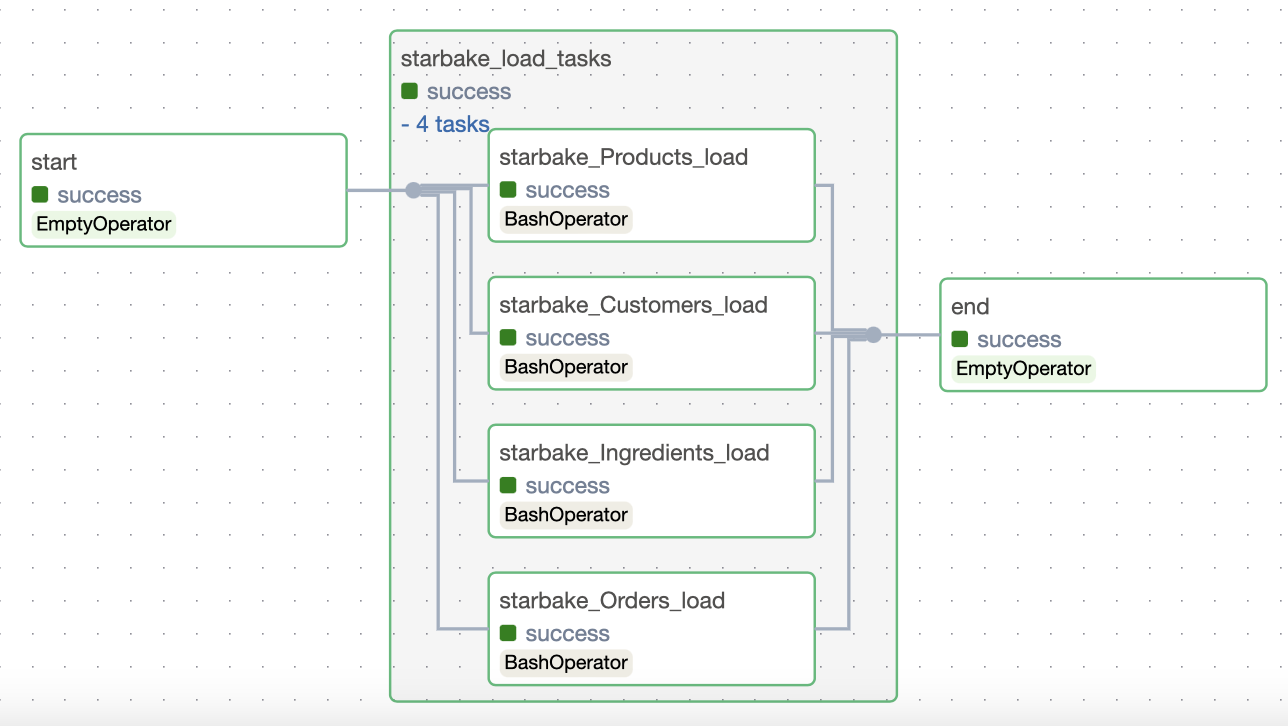
The following example demonstrates how to create a Starlake Airflow pipeline for loading data into a domain.
description="""data loading for starbake domain"""
options={
'sl_env_var':'{"SL_ROOT": "/demo-starbake", "SL_ENV": "BQ"}',
'SL_STARLAKE_PATH':'/bin/starlake',
'SL_TIMEZONE':'Europe/Paris',
'tags':'starbake',
'pre_load_strategy':'imported',
'ack_wait_timeout':'60',
'global_ack_file_path':'/demo-starbake/datasets/pending/starbake/GO.ack'
}
from ai.starlake.job import StarlakeOrchestrator
orchestrator = StarlakeOrchestrator.AIRFLOW
from ai.starlake.job import StarlakeExecutionEnvironment
execution_environment = StarlakeExecutionEnvironment.SHELL
import os
import sys
from ai.starlake.job import StarlakeJobFactory
sl_job = StarlakeJobFactory.create_job(
filename=os.path.basename(__file__),
module_name=f"{__name__}",
orchestrator=orchestrator,
execution_environment=execution_environment,
options=dict(options, **sys.modules[__name__].__dict__.get('jobs', {}))
)
from ai.starlake.job import StarlakePreLoadStrategy
from ai.starlake.dataset import StarlakeDataset
from ai.starlake.orchestration import StarlakeSchedule, StarlakeDomain, StarlakeTable, OrchestrationFactory
from typing import List
schedules= [
StarlakeSchedule(
name='daily',
cron='0 0 * * *',
domains=[
StarlakeDomain(
name='starbake',
final_name='starbake',
tables=[
StarlakeTable(
name='Customers',
final_name='Customers'
),
StarlakeTable(
name='Ingredients',
final_name='Ingredients'
),
StarlakeTable(
name='Products',
final_name='Products'
)
]
)
]),
StarlakeSchedule(
name='hourly',
cron='0 * * * *',
domains=[
StarlakeDomain(
name='starbake',
final_name='starbake',
tables=[
StarlakeTable(
name='Orders',
final_name='Orders'
)
]
)
])
]
with OrchestrationFactory.create_orchestration(job=sl_job) as orchestration:
def generate_pipeline(schedule: StarlakeSchedule):
# generate the load pipeline
with orchestration.sl_create_pipeline(
schedule=schedule,
) as pipeline:
pipeline_id = pipeline.pipeline_id
schedule = pipeline.schedule
schedule_name = pipeline.schedule_name
start = pipeline.start_task(task_id=f'start_{schedule_name}')
if not start:
raise Exception("Start task not defined")
pre_tasks = pipeline.pre_tasks()
if pre_tasks:
start >> pre_tasks
def generate_load_domain(domain: StarlakeDomain):
from ai.starlake.common import sanitize_id
if schedule_name:
name = f"{domain.name}_{schedule_name}"
else:
name = domain.name
with orchestration.sl_create_task_group(group_id=sanitize_id(name), pipeline=pipeline) as ld:
pre_load_strategy=pipeline.pre_load_strategy
def pre_load(pre_load_strategy: StarlakePreLoadStrategy):
if pre_load_strategy != StarlakePreLoadStrategy.NONE:
with orchestration.sl_create_task_group(group_id=sanitize_id(f'pre_load_{name}'), pipeline=pipeline) as pre_load_tasks:
pre_load = pipeline.sl_pre_load(
domain=domain.name,
tables=set([table.name for table in domain.tables]),
params={'cron':schedule.cron, 'schedule': schedule_name},
)
skip_or_start = pipeline.skip_or_start(
task_id=f'skip_or_start_loading_{name}',
upstream_task=pre_load
)
if pre_load_strategy == StarlakePreLoadStrategy.IMPORTED:
sl_import = pipeline.sl_import(
task_id=f"import_{name}",
domain=domain.name,
tables=set([table.name for table in domain.tables]),
)
else:
sl_import = None
if skip_or_start:
pre_load >> skip_or_start
if sl_import:
skip_or_start >> sl_import
elif sl_import:
pre_load >> sl_import
return pre_load_tasks
else:
return None
pld = pre_load(pre_load_strategy)
def load_domain_tables():
with orchestration.sl_create_task_group(group_id=sanitize_id(f'load_{name}'), pipeline=pipeline) as load_domain_tables:
for table in domain.tables:
pipeline.sl_load(
task_id=sanitize_id(f'load_{domain.name}_{table.name}'),
domain=domain.name,
table=table.name,
spark_config=pipeline.sl_spark_config(f'{domain.name}.{table.name}'.lower()),
params={'cron':schedule.cron},
)
return load_domain_tables
ld_tables=load_domain_tables()
if pld:
pld >> ld_tables
return ld
load_domains = [generate_load_domain(domain) for domain in schedule.domains]
end = pipeline.end_task(
task_id=f'end_{schedule_name}',
output_datasets=[StarlakeDataset(uri=pipeline_id, cron=schedule.cron)]
)
if pre_tasks:
start >> pre_tasks >> load_domains
else:
start >> load_domains
end << load_domains
post_tasks = pipeline.post_tasks()
if post_tasks:
all_done = pipeline.sl_dummy_op(task_id="all_done")
all_done << load_domains
all_done >> post_tasks >> end
return pipeline
[generate_pipeline(schedule) for schedule in schedules]


Dagster
Starlake Dagster is the Starlake Python Distribution of Starlake orchestration for Dagster.
Starlake Dagster Installation
pip install starlake-orchestration[dagster] --upgrade
Starlake Dagster Load example
The following example demonstrates how to create a Starlake Dagster pipeline for loading data into a domain.
orchestrator = StarlakeOrchestrator.DAGSTER


The only difference with the previous example is the orchestrator type.
Conclusion
With Starlake Orchestration, Write once, Deploy anywhere. :)
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file starlake_orchestration-0.4.3.2.tar.gz.
File metadata
- Download URL: starlake_orchestration-0.4.3.2.tar.gz
- Upload date:
- Size: 65.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3b867e2585fdbfdb22c43198e3c013abbe2c1f3e54e5f2fcceb6d9e431db5f5b
|
|
| MD5 |
f5c76ba38ab509c88893b0bd2eebc507
|
|
| BLAKE2b-256 |
7663fb819ed3d4b69ae9c8a4b5a1954bcd72743cd85f715279b4bd4b4774bfe1
|
File details
Details for the file starlake_orchestration-0.4.3.2-py3-none-any.whl.
File metadata
- Download URL: starlake_orchestration-0.4.3.2-py3-none-any.whl
- Upload date:
- Size: 73.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0a89c0290dca08c1345fc30159fc20386e4cd0c607549212cadb562994cd60e5
|
|
| MD5 |
70a7ba871eea6d9d7d1018b35a8024e3
|
|
| BLAKE2b-256 |
9dcbadd5876f7365a4f20f38e31cafcf2161a7723e341b9fb87c0e625e78ad3b
|







