Agent-native Stata bridge — one core, multiple frontends (MCP, Jupyter, VSCode)
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description

stata-code











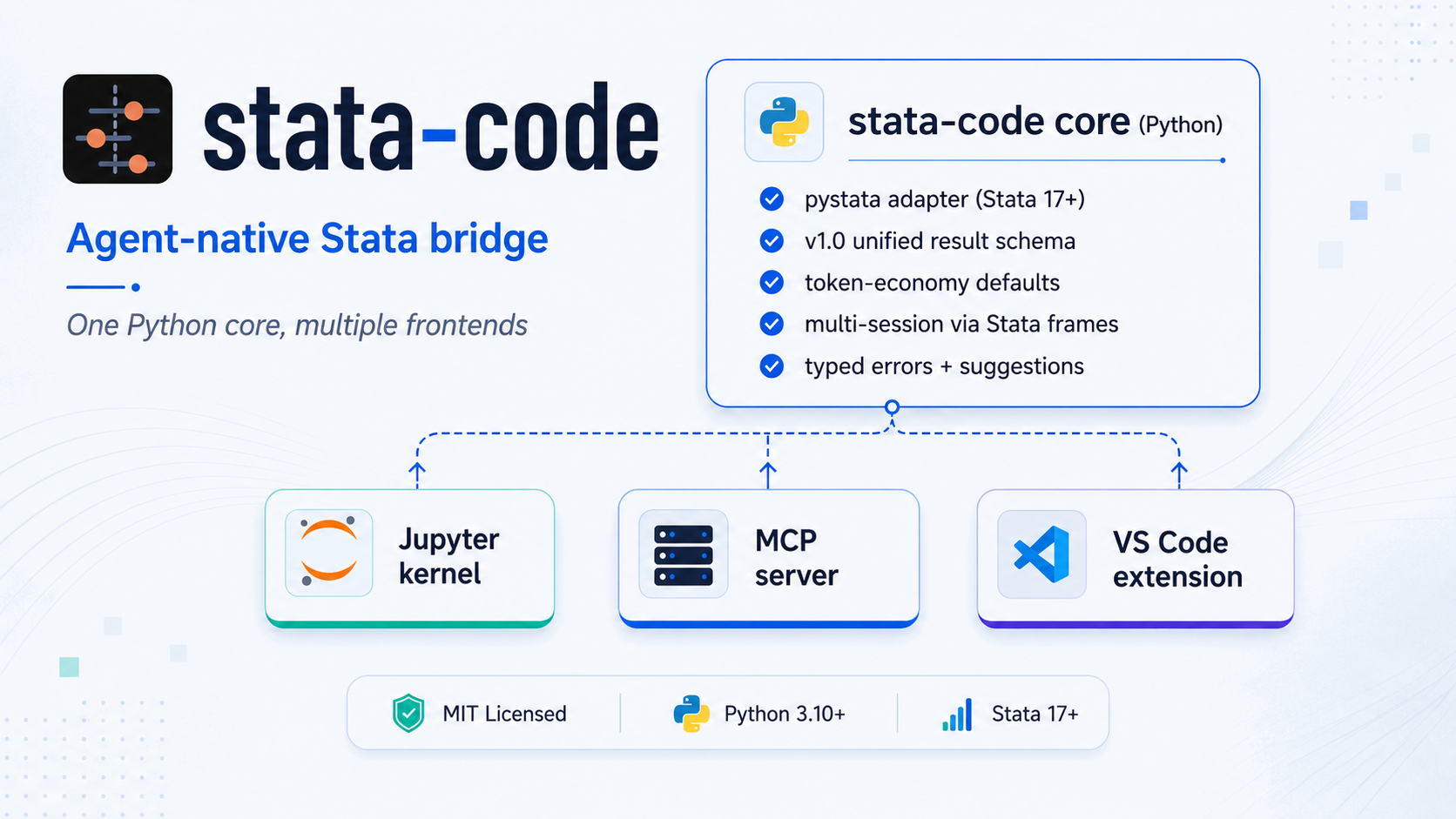
Agent-native Stata bridge — one Python core, multiple frontends.
stata-code lets you drive Stata from modern environments: an LLM agent (Claude Code, Cursor, Claude Desktop), a Jupyter notebook, or a VS Code editor session. All frontends share one Python core and return a stable, structured, agent-friendly result schema.
┌────────────────────────────────────────┐
│ stata-code core (Python) │
│ │
│ • pystata adapter (Stata 17+) │
│ • v1.0 unified result schema │
│ • token-economy defaults │
│ • multi-session via Stata frames │
│ • typed errors + suggestions │
└────────────────────────────────────────┘
↑ ↑ ↑
┌────────┴────┐ ┌──────┴─────┐ ┌────┴────────────┐
│ Jupyter │ │ MCP │ │ VS Code │
│ kernel │ │ server │ │ extension │
└─────────────┘ └────────────┘ └─────────────────┘
Status: v0.6 (May 2026) — the core, MCP server, Jupyter kernel, and VS Code extension work end-to-end against Stata 18 MP. Current test suite: 329 passing tests across schema, runner, MCP, kernel, notebook, run-index, subprocess-pool, and VS Code modules. License: MIT.
Two workflows v0.6 explicitly supports for end users:
- Run Stata code from a Jupyter notebook.
pip install "stata-code[kernel]"+stata-code-kernel install --userregisters a Stata kernel that the Jupyter Notebook UI, JupyterLab, and the VS Code Jupyter extension all pick up by name. Cells render Stata logs, graphs, and warnings inline (the kernel logo bundled since v0.5 makes it appear in VS Code's kernel picker too). See As a Jupyter Kernel. - Optional agent "fix and rerun" loop.
stata_runreturns typederror.kind/line/contextplussuggestionson every failure. By default Claude Code only reports diagnostics — but if you explicitly say "fix this and rerun until it passes", the agent uses the same fields to edit your.dofile and re-callstata_rununtil the run is green. The repair loop is opt-in: failed runs are diagnostics first, not automatic rewrite permission. See Error Recovery in Agent Workflows.
Why this exists
The Stata AI / agent tooling landscape is fragmented; see References-tools.md:
- Existing MCP servers (SepineTam/stata-mcp, tmonk/mcp-stata) are AGPL-3.0, which is not a fit for closed-source or commercial integration.
- The popular VS Code AI extension (hanlulong/stata-mcp) is MIT, but it bundles the MCP server inside the extension, making standalone reuse awkward.
- Each tool wraps
pystatawith its own result shape, so agents have to special-case each integration. - Many existing tools were designed for humans first and then bolted onto MCP; they often dump long logs and base64 graph blobs into every reply, burning tokens by default.
stata-code is designed to fill that gap:
- MIT-licensed, with no copyleft contagion.
- One shared result schema for every frontend: SCHEMA.md.
- Agent-native by default: typed errors, structured
r()/e(), log refs, graph refs, and suggestion seeds. - One core, multiple frontends: Jupyter kernel, MCP server, and VS Code extension.
For the project's clean-room policy around AGPL/GPL Stata projects, see LICENSE-POLICY.md.
Install
Requirements: Stata 17+ (with pystata shipped by Stata) and Python 3.10+.
# from PyPI
pip install stata-code
# with the MCP server and Jupyter kernel extras
pip install "stata-code[mcp,kernel]"
# or from source (editable install for development)
git clone https://github.com/brycewang-stanford/stata-code.git
cd stata-code
pip install -e ".[mcp,kernel]"
Naming note. The PyPI distribution is
stata-code(hyphen), but the Python import isstata_code(underscore — Python identifiers can't contain hyphens). Same convention asscikit-learn→import sklearn. So:pip install stata-code,from stata_code import run.
Note: pystata is not on PyPI; it ships with Stata. stata-code auto-discovers it on macOS at /Applications/Stata/utilities/pystata and at equivalent Linux / Windows paths. If your install is elsewhere, add it to PYTHONPATH before importing.
Quick Start
See examples/ for end-to-end cookbook entries: basic regression, DiD, graphs, multi-session, and large matrices.
As a Python Library
The package-level run() / execute() API uses the same subprocess-backed
runner as the MCP server, so long calls honor timeout_ms and pystata
stdout redirection stays isolated from the caller process.
from stata_code import run
r = run("sysuse auto, clear")
r = run("regress mpg weight")
if r.ok:
print(r.results.e.scalars["r2"]) # 0.6515 (native float)
print(r.results.e.macros["cmd"]) # "regress"
b = r.results.e.matrices["b"]
print(dict(zip(b.cols, b.values[0]))) # {"weight": -0.006, "_cons": 39.44}
else:
print(r.error.kind, r.error.message) # ErrorKind.VARNAME_NOT_FOUND, "..."
for s in r.error.suggestions:
print("hint:", s.action) # "Did you mean `mpg`?"
As an MCP Server
After pip install "stata-code[mcp]", the stata-code-mcp binary is on your PATH. You can wire it into Claude Code, Cursor, Claude Desktop, or any other MCP-compatible client.
Claude Code via claude mcp add (recommended)
If you have not installed Claude Code yet, see anthropics/claude-code.
The fastest way is the claude mcp add CLI. Pick a scope based on how widely you want stata-code available:
# user scope — install once, available in every Claude Code workspace on this machine
claude mcp add stata-code --scope user -- stata-code-mcp
# local scope — only for the current workspace (your local Claude config, not committed)
claude mcp add stata-code --scope local -- stata-code-mcp
# project scope — written into ./.mcp.json so collaborators on this repo share it
claude mcp add stata-code --scope project -- stata-code-mcp
Then launch claude and type /mcp to confirm stata-code shows up with its 15 tools (stata_run, stata_info, get_log, get_graph, get_matrix, list_sessions, cancel_session, reset_session, notebook_outline, notebook_get_cell, notebook_locate, notebook_edit_cell, notebook_insert_cell, notebook_delete_cell, list_runs).
Error Recovery in Agent Workflows
stata_run does not rewrite the source .do file or change code on its own. It executes the submitted Stata code, so that code may still create logs, graphs, tables, or other outputs as usual. When Stata fails, stata_run returns typed diagnostics (error.kind, error.message, error.line, error.context) plus best-effort suggestions. That supports two distinct Claude Code workflows:
- For "run this do-file" or "verify this code", Claude can report the failure and suggested next steps without changing source files.
- For "fix this and rerun until it passes", Claude can use the same structured error fields to edit the
.dofile, callstata_runagain, and iterate.
If you want the repair loop, say so explicitly. Otherwise, treat failed runs as diagnostics first, not as automatic permission to rewrite code.
uvx (no global pip install)
If you prefer not to pip install stata-code globally, run it ephemerally through uv:
claude mcp add stata-code --scope user -- uvx --from stata-code stata-code-mcp
uvx will resolve and cache stata-code on first launch. Note: pystata is not on PyPI, so it still has to be locatable on the host. The runner adds the standard Stata install path (e.g. /Applications/Stata/utilities/pystata on macOS) to sys.path automatically; if your Stata lives elsewhere, set PYTHONPATH in the env block.
Manual JSON config (Cursor / Claude Desktop / fallback)
For clients without a mcp add CLI, edit the config file directly (~/.claude/mcp.json, Cursor settings, Claude Desktop claude_desktop_config.json, etc.):
{
"mcpServers": {
"stata-code": {
"command": "stata-code-mcp"
}
}
}
Or run it as a module if the binary is not on PATH:
python -m stata_code.mcp
The MCP server registers 15 tools:
| Tool | Purpose |
|---|---|
stata_run |
Execute Stata code and return a v1.0 RunResult JSON |
stata_info |
Report Stata edition, version, and capabilities |
get_log |
Fetch the full log behind a log:// ref |
get_graph |
Fetch graph bytes behind a graph:// ref (ImageContent) |
get_matrix |
Fetch matrix payloads behind a matrix:// ref |
list_sessions |
Enumerate live sessions |
cancel_session |
Cooperatively cancel the next stata_run for a session |
reset_session |
Drop a session's data |
notebook_outline |
Compact per-cell index of a .ipynb (cell_id, type, preview) |
notebook_get_cell |
One cell's full source plus a token-economic outputs summary |
notebook_locate |
Find cells by snippet / regex / pasted error text |
notebook_edit_cell |
Atomically replace one cell's source (preserves id, clears outputs) |
notebook_insert_cell |
Insert a new cell with a fresh nbformat 4.5+ UUID |
notebook_delete_cell |
Remove a cell by id |
list_runs |
Query run-bundle manifests (filter by notebook / cell_id / session / since / ok) |
For modern MCP clients, these tools now return structured results through
structuredContent with outputSchema metadata, while still keeping the
serialized JSON text block for older clients. The server also exposes MCP
resources:
| Resource | Purpose |
|---|---|
stata://schema/run-result |
JSON Schema for stata_run structured output |
stata://server/capabilities |
Server instructions, tools, and resource templates |
stata://sessions |
Current subprocess-backed Stata sessions |
log://... |
Full log text from a truncated stata_run result |
graph://... |
Captured graph image bytes |
matrix://... |
Deferred large matrix payloads |
MCP prompts are available for common agent workflows:
run_do_file_and_report, debug_stata_error,
fix_and_rerun_until_passes, replication_audit, and
summarize_estimation_results.
As a Jupyter Kernel
stata-code ships a Jupyter kernel as part of the Python package — there is no separate "Jupyter plugin" in the JupyterLab extension marketplace. Installation is two steps: pip install the package with the kernel extra, then register the kernelspec with Jupyter.
Prerequisites: Stata 17+ installed locally with a valid license (the kernel calls Stata via pystata), and Python 3.10+ with jupyter/jupyterlab already on the same environment.
# 1. Install stata-code with the kernel extra (pulls in ipykernel)
pip install "stata-code[kernel]"
# 2. Register the kernelspec into Jupyter's user data dir
stata-code-kernel install --user
# Or, equivalently:
# python -m stata_code.kernel install --user
Verify the kernel is registered:
jupyter kernelspec list
# should include an entry named `stata`
Then open Jupyter Notebook / JupyterLab (or a .ipynb in VS Code), pick Stata in the kernel selector, and run Stata commands in cells. Logs, graphs, and warnings render inline.
JupyterLab's Extension Manager only installs front-end JS extensions, so it cannot install a kernel —
pip installplus theinstall --userstep above is the only supported path.
As a VS Code Extension
The companion extension is on the Marketplace as brycewang-stanford.stata-code-vscode. It spawns stata-code-mcp as a child process and adds syntax highlighting, an Outline view for **# sections and program define blocks, code-lens "Run cell" and "Run section" actions on .do files, a sidebar (sessions / last result / run history / logs / graphs), status-bar indicators, completions, help lookup, conservative variable rename, and inline diagnostics from the v1.0 typed errors.
# from the VS Code CLI
code --install-extension brycewang-stanford.stata-code-vscode
Or open the Extensions sidebar in VS Code and search stata-code.
The extension still requires the MCP extra on your system Python (pip install "stata-code[mcp]"), so that stata-code-mcp resolves on PATH and can import the MCP SDK. Stata 17+ and a valid Stata license are required as for any other frontend.
Token-Economy Defaults
A typical stata_run response is about 10x smaller than servers that dump logs and images directly. Three design choices drive this:
- Logs return
head+tail+refby default. Full logs are fetched on demand viaget_log(ref). A Stata regression log can be about 6,000 tokens;stata-codereturns about 600 by default. - Graphs return refs, not inline base64. A 30 KB PNG can become about 50,000 base64 tokens; returning a ref avoids that unless the agent actually needs the bytes.
- Errors are typed. Agents can check
err.kind == "varname_not_found"instead of regex-parsing English logs.
For example, a misspelled variable returns a structured error:
{
"ok": false,
"rc": 111,
"error": {
"kind": "varname_not_found",
"varname": "mpgg",
"line": 3,
"context": {
"before": ["use auto"],
"failing": "summarize mpgg",
"after": []
},
"suggestions": [
{"action": "Did you mean `mpg`?", "command": "describe"}
]
}
}
The full schema is in SCHEMA.md.
Architecture
stata_code/
├── core/
│ ├── _runtime.py # process-singleton pystata wrapper
│ ├── _refs.py # LRU ref store for log/graph/matrix payloads
│ ├── schema.py # Pydantic v2 models for the v1.0 result schema
│ ├── errors.py # rc → ErrorKind mapping + suggestion seeds
│ ├── runner.py # in-process execute(); collects everything via sfi
│ └── _pool.py # subprocess workers for public API / MCP hard timeouts
├── mcp/
│ └── server.py # MCP server (15 tools)
└── kernel/
└── kernel.py # Jupyter kernel
runner.py is the only place that directly talks to pystata. The public Python API and MCP server route calls through _pool.py, whose workers call runner.execute() in an isolated subprocess; the Jupyter kernel uses the in-process runner for notebook interactivity.
Comparison
| stata-code | SepineTam/stata-mcp | hanlulong/stata-mcp | nbstata | |
|---|---|---|---|---|
| License | MIT | AGPL-3.0 | MIT | GPL-3.0 |
| Standalone MCP | ✓ | ✓ | bundled with VS Code | — |
| Jupyter kernel | ✓ | — | — | ✓ |
| Unified result schema | ✓ (SCHEMA.md) | per-tool | per-tool | per-tool |
| Token-economy defaults | ✓ (log refs, graph refs) | — | — | — |
| Typed errors + suggestions | ✓ (32 kinds) | — | — | — |
| Multi-session | ✓ (Stata frames) | partial | — | — |
| Mature ecosystem | early | ✓ (statamcp.com, cookbook) | ✓ (11k installs) | ✓ |
stata-code is the younger, MIT-licensed, agent-native alternative in this problem space. Among the AGPL options, SepineTam's stata-mcp is currently more mature; stata-code is aimed at cases where copyleft contagion is unacceptable and agents need structured results.
Roadmap
Done (through v0.6 — May 2026)
- v1.0 result schema (SCHEMA.md)
pystata-based runner with native-typedr(),e(), and matrices- Multi-session via Stata frames
- Per-line error attribution: line number, context, commands_executed
- Graph capture:
png/svg/pdfwith ref store - Log truncation with ref store
- Warning extraction: 5 categories + generic notes
- 32-kind error taxonomy with canonical suggestions
- MCP server: 15 tools, including notebook navigation / search / atomic edits and the run-bundle index (
list_runs) - Jupyter kernel: rewired to the v1.0 pipeline, kernel logos bundled
- Matrix size cap +
get_matrix(ref)for large matrices (>10k cells) - Cooperative cancellation:
cancel(session_id)/ MCPcancel_session - Per-cell repair loop on
.ipynbvianotebook_outline/notebook_get_cell/notebook_edit_cellwith optimistic-concurrencyexpected_sourceguards andorigin_cell_idecho onRunResult - Persistent run bundles +
list_runsquery overmanifest.jsonfiles (filter by cell / origin / session / since / ok) - JSON Schema artifact auto-generated from
schema.py:schema/run_result.schema.json - VS Code extension published to the Marketplace as
brycewang-stanford.stata-code-vscode: syntax highlighting, section outline/navigation, code-lens cell and section runners, sidebar (sessions / last result / run history / logs / graphs), status bar, completions, conservative variable rename, diagnostics, MCP child-process spawn - Clean-room license policy (LICENSE-POLICY.md)
Next Up
- Console fallback for Stata 11–16, re-implemented against the v1.0 schema
- Hard timeout / mid-Stata interrupt; design and tradeoffs in
docs/design/hard_timeout.md - Extra VS Code polish (esbuild bundle, lighter VSIX, command palette UX)
- v1.0 — Stable schema, broader Stata edition coverage
See SCHEMA.md §7 for explicitly out-of-scope items.
Testing
pip install -e ".[dev,mcp,kernel]"
pytest # full suite (310 tests)
pytest -m "not stata_required" # CI subset; no Stata needed
pytest -m "stata_required" -v # Stata-only integration tests
The stata_required marker tags the real-Stata integration tests. CI uses pytest -m "not stata_required" so it does not collect them. Locally without Stata, those tests skip cleanly with the "pystata / Stata 17+ not available" message.
Contributing
- Read LICENSE-POLICY.md before opening a PR.
- Add a one-line acknowledgement to your first PR description; the template is in the policy file.
- Tests are required for any new schema field or runner behavior.
License
The code is licensed under MIT. LICENSE-POLICY.md explains how this project relates to other Stata projects.
Trademark Notice
Stata is a registered trademark of StataCorp LLC. This project is independent and not affiliated with or endorsed by StataCorp.
Acknowledgements
The Stata tooling landscape that this project builds on and learns from is surveyed in References-tools.md. All listed projects retain their own licenses and authorship; please consult each repository before reuse.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file stata_code-0.6.3.tar.gz.
File metadata
- Download URL: stata_code-0.6.3.tar.gz
- Upload date:
- Size: 177.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
58299b68ca21eb7531d914c9b12cbcef3ee366fd36de027cdc25733bf517d725
|
|
| MD5 |
0ab32a5dc33db0de64996f7425737071
|
|
| BLAKE2b-256 |
f0b6b97d8024f4658861051732fd9d5e10b2a29ec18ad8202be7212bacb92fef
|
Provenance
The following attestation bundles were made for stata_code-0.6.3.tar.gz:
Publisher:
release.yml on brycewang-stanford/stata-code
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
stata_code-0.6.3.tar.gz -
Subject digest:
58299b68ca21eb7531d914c9b12cbcef3ee366fd36de027cdc25733bf517d725 - Sigstore transparency entry: 1500360941
- Sigstore integration time:
-
Permalink:
brycewang-stanford/stata-code@3c1661ce71b935b3a3b4a4730de3681ad98f7d57 -
Branch / Tag:
refs/tags/v0.6.3 - Owner: https://github.com/brycewang-stanford
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@3c1661ce71b935b3a3b4a4730de3681ad98f7d57 -
Trigger Event:
push
-
Statement type:
File details
Details for the file stata_code-0.6.3-py3-none-any.whl.
File metadata
- Download URL: stata_code-0.6.3-py3-none-any.whl
- Upload date:
- Size: 100.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b342e108b2828740c54362eab437ade490c062bd0bb33b0731aec3bd5917db59
|
|
| MD5 |
c52be42ec376960198b091847a8bf918
|
|
| BLAKE2b-256 |
e2a85c56972ba71599181fdcdbe007f20cbac87f367c71a81c877e08d37de514
|
Provenance
The following attestation bundles were made for stata_code-0.6.3-py3-none-any.whl:
Publisher:
release.yml on brycewang-stanford/stata-code
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
stata_code-0.6.3-py3-none-any.whl -
Subject digest:
b342e108b2828740c54362eab437ade490c062bd0bb33b0731aec3bd5917db59 - Sigstore transparency entry: 1500361059
- Sigstore integration time:
-
Permalink:
brycewang-stanford/stata-code@3c1661ce71b935b3a3b4a4730de3681ad98f7d57 -
Branch / Tag:
refs/tags/v0.6.3 - Owner: https://github.com/brycewang-stanford
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@3c1661ce71b935b3a3b4a4730de3681ad98f7d57 -
Trigger Event:
push
-
Statement type:







