A process pool that allows workers to maintain state across tasks.

Project description
Stateful Pool

Default ProcessPoolExecutor makes it hard to maintain stateful workers,
especially workers with expensive setup (e.g., workers each with a model loaded in GPU memory).
This library lets you create a pool of stateful workers (spawn once) to run tasks in parallel across processes (execute many) using a worker pattern actor model.
+-----------------------+ +----------------------+
| Main Process | | Process Pool |
| +--------+ +--------+ | | +------------------+ |
| | Thread | | Thread | | --- Task --> | | Worker (Process) | |
| | 1 | | 2 | | <-- Resp --- | +------------------+ |
| +--------+ +--------+ | | +------------------+ |
| ... ... | | | Worker (Process) | |
| +--------+ +--------+ | | +------------------+ |
| | Thread | | Thread | | --- Task --> | ... |
| | N-1 | | N | | <-- Resp --- | +------------------+ |
| +--------+ +--------+ | | | Worker (Process) | |
| | | +------------------+ |
+-----------------------+ +----------------------+
Installation:
pip install stateful-pool
Following is an example of how to define a worker class, spawn workers (assigned several GPU IDs), and execute tasks on them.
from stateful_pool import SPool, SWorker
import time, random
# will run in another process
class SquareWorker(SWorker):
def spawn(self, gpu_ids: list[int]):
self.gpu_ids = gpu_ids
return f"Worker initialized on GPU: {self.gpu_ids}"
def execute(self, value):
time.sleep(random.uniform(0.1, 1.0))
return f"[Execute] Square of {value} is {value * value} (computed on GPU: {self.gpu_ids})"
if __name__ == "__main__":
with SPool(SquareWorker, queue_size=100) as pool:
# spawn a worker, return value can be captured
s = pool.spawn(gpu_ids=[0, 1])
print(f"{s}")
# submit a single task and wait for result
r = pool.execute(100)
print(r)
The example calls pool.execute once. This doesn't demonstrate the power of the pool (parallelism).
In practice, you would likely want to submit tasks in a non-blocking manner via submit_* or async_* counterparts:
with SPool(SquareWorker) as pool:
spawn_futures = [pool.submit_spawn(gpu_ids=[i, i+1]) for i in range(0, 4, 2)]
for f in spawn_futures:
print(f.result())
execute_futures = [pool.submit_execute(i) for i in range(4)]
for f in execute_futures:
print(f.result())
more examples can be found in the example.py and benchmark/exp/server_spool.py.
Benchmark
The performance is benchmarked in a stress test scenario where multiple clients send concurrent requests to a server processing image data. The benchmark compares three server implementations, essentially comparing load-balancing strategies:
server_simple: A simple threaded server that randomly dispatches requests to worker threads.server_mp: A multiprocessing server that maintains a pool of workers, but still random dispatch without producer-consumer queues.server_spool: A server that utilizes thestateful-poollibrary, allowing for efficient parallel task execution.
The result shows that server_spool achieves ~30% higher throughput and more stable latency, while implemented with less complexity (~40% code reduction).
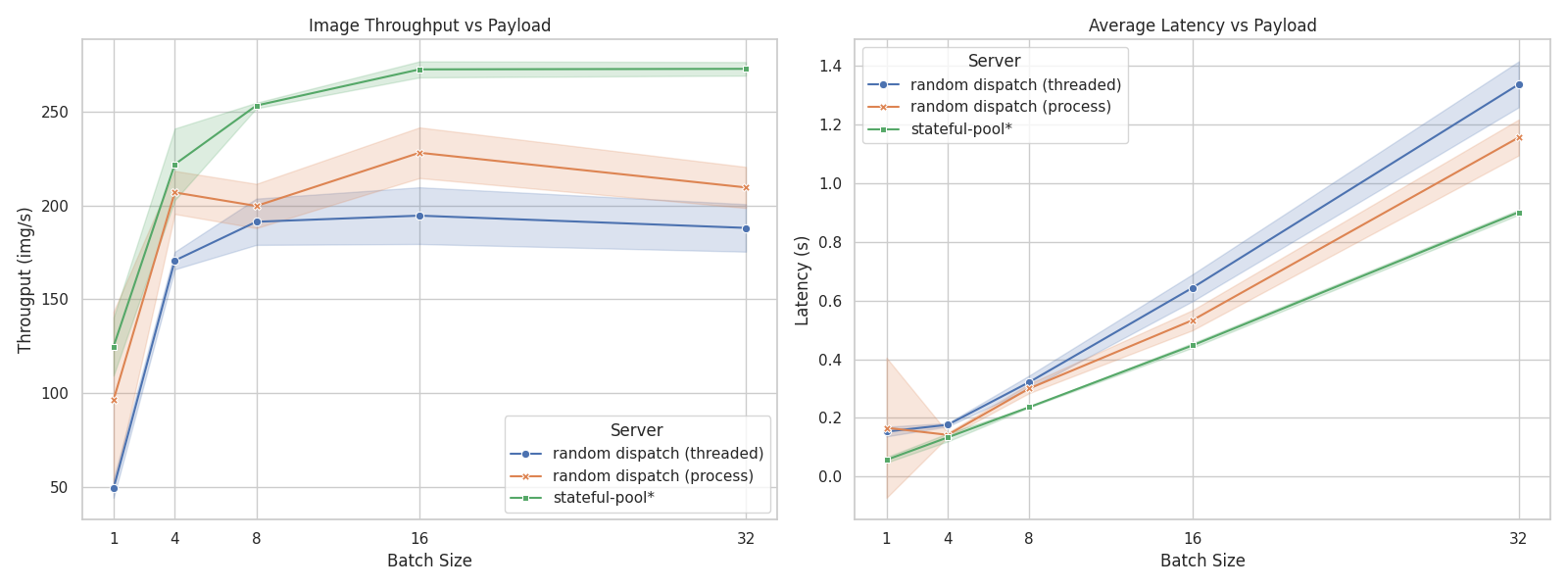
The result is obtained by running a stress test with 100 concurrent clients sending requests to each server implementation. Each request involves processing an image and returning a response.
We use ViT-L/16 as the model for processing images, the server runs on a machine with 2 GPUs.
The test is run for 5 times for each server, and the average throughput and latency, as well as their standard deviation, are recorded.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file stateful_pool-0.3.2.tar.gz.
File metadata
- Download URL: stateful_pool-0.3.2.tar.gz
- Upload date:
- Size: 5.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.0 CPython/3.10.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
750a7cd7142f7d4c3a406d6e818e090508b6dac7fa33e104c11f43649154b3cb
|
|
| MD5 |
2497e0222e6d94ebc4faa7e6f889ef5b
|
|
| BLAKE2b-256 |
cc2ef31e9c2e57e09b66d7e399512f6f460976edd0df3a614e7497764b403df0
|
File details
Details for the file stateful_pool-0.3.2-py3-none-any.whl.
File metadata
- Download URL: stateful_pool-0.3.2-py3-none-any.whl
- Upload date:
- Size: 5.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.0 CPython/3.10.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b97bdb4f7f536e3a9d2709f9028d8f9908b49bff330224261c08c5040577f18f
|
|
| MD5 |
c7f5ddfae35532358c1ed01467e4b55d
|
|
| BLAKE2b-256 |
273df313942e5f6b77fd5130ef4cbf7e8bed47398099c53518a43bec34bed71d
|







