STREAM (Sequential Tasks Review to Evaluate Artificial Memory) is a dataset of 12 diverse sequential tasks to assess neural networks’ memory. Scalable in complexity and sequence length, it covers pattern completion, copy tasks, forecasting, bracket matching, and sorting—ideal for comparing architectures on memory retention and sequential reasoning.

Project description
Stream Dataset
A comprehensive dataset suite for evaluating sequence modeling capabilities of neural networks, particularly focusing on memory, long-term dependencies, and temporal reasoning tasks.
🚀 Features
- 12 Diverse Tasks: From simple memory tests to complex pattern recognition
- Multiple Difficulty Levels: Small, medium and large configurations. Advice : if you're building an architecture, you should begin with small.
- Unified Interface: Consistent API across all tasks with standardized evaluation metrics
- Ready-to-Use: Pre-configured datasets with train/validation/test splits
- Flexible: Support for both classification/multi-classification and regression tasks
📦 Installation
pip install stream-dataset
Or install from source:
git clone https://github.com/Naowak/stream-dataset.git
cd stream-dataset
pip install -e .
🎯 Quick Start
import stream_dataset as sd
# Build a task
task_data = sd.build_task('simple_copy', difficulty='small', seed=0)
# Access the data
X_train = task_data['X_train'] # Training inputs
Y_train = task_data['Y_train'] # Training targets
T_train = task_data['T_train'] # Prediction timesteps
# Train your model (example with dummy predictions)
Y_pred = your_model.predict(X_train)
# Evaluate performance
score = sd.compute_score(
Y=Y_train,
Y_hat=Y_pred,
prediction_timesteps=T_train,
category=task_data['category']
)
print(f"Score: {score}")
📚 Available Tasks
Memory Tests
Postcasting Tasks
-
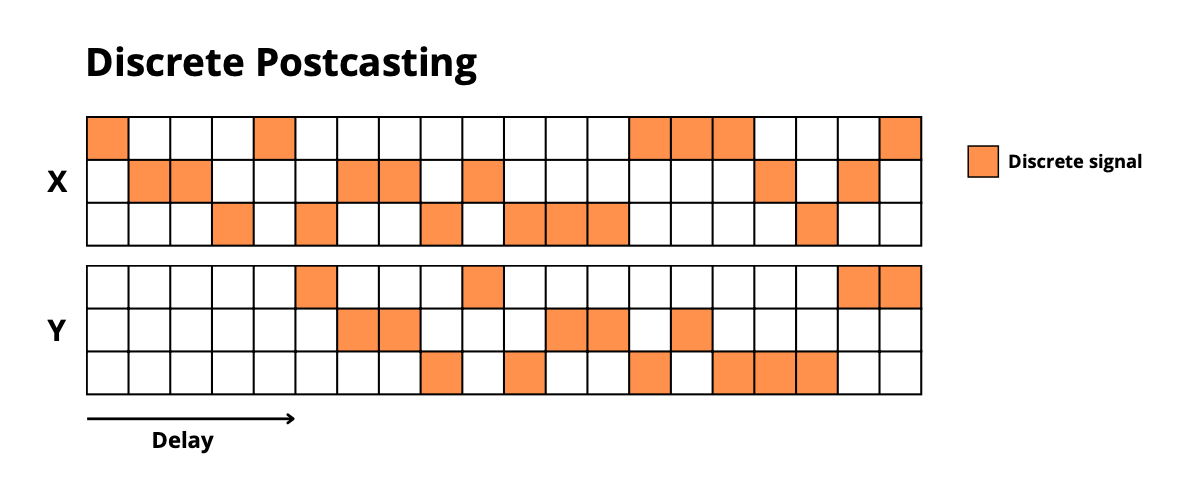
discrete_postcasting: Copy discrete sequences after a delay -
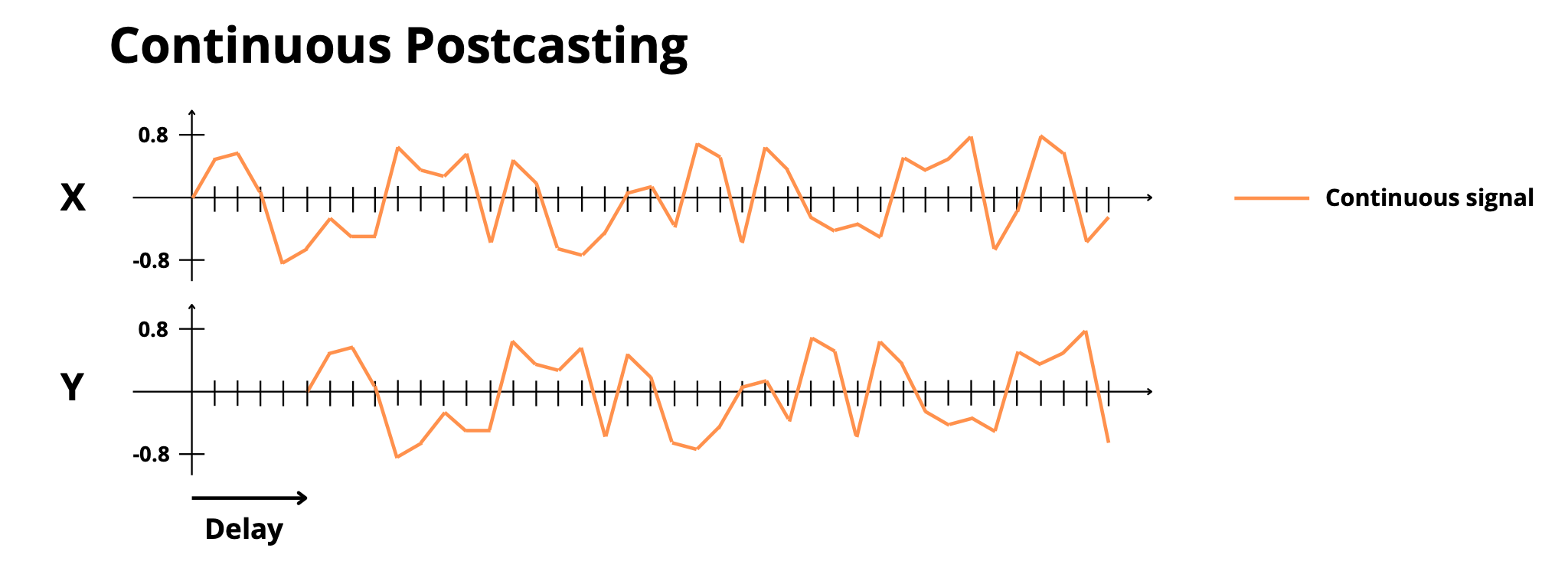
continuous_postcasting: Copy continuous sequences after a delay
Signal Processing
-
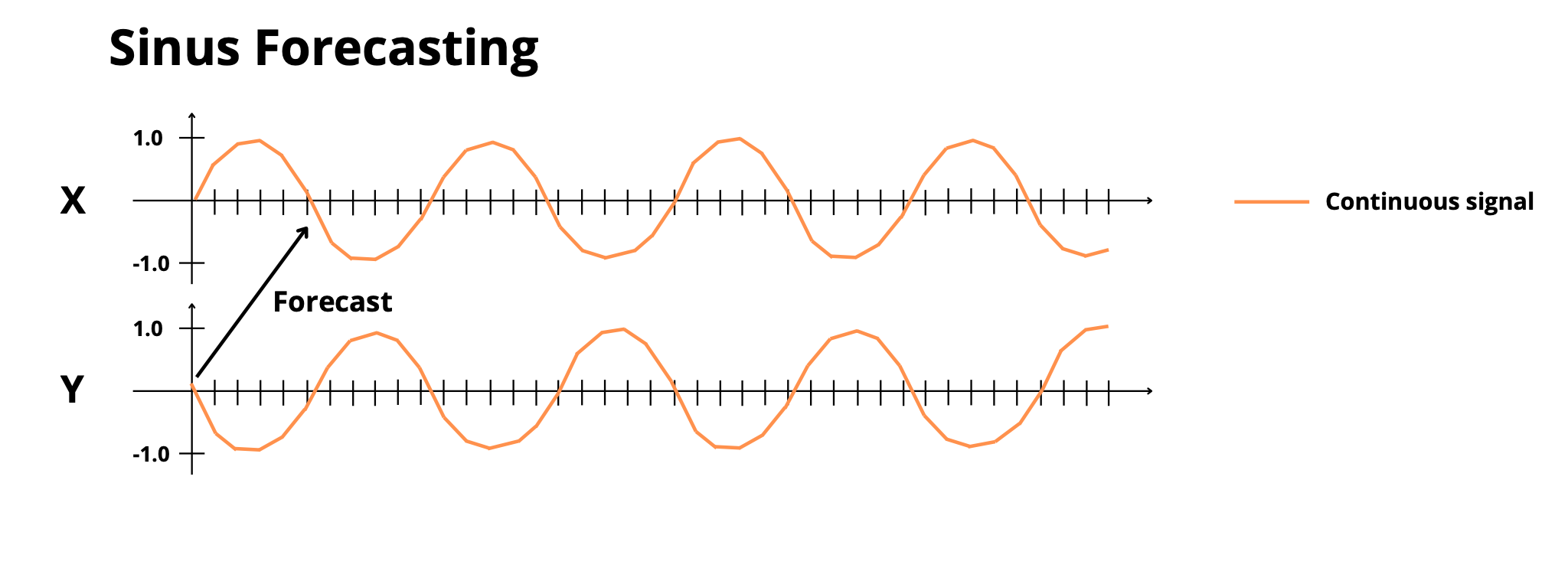
sinus_forecasting: Predict frequency-modulated sinusoidal signals -
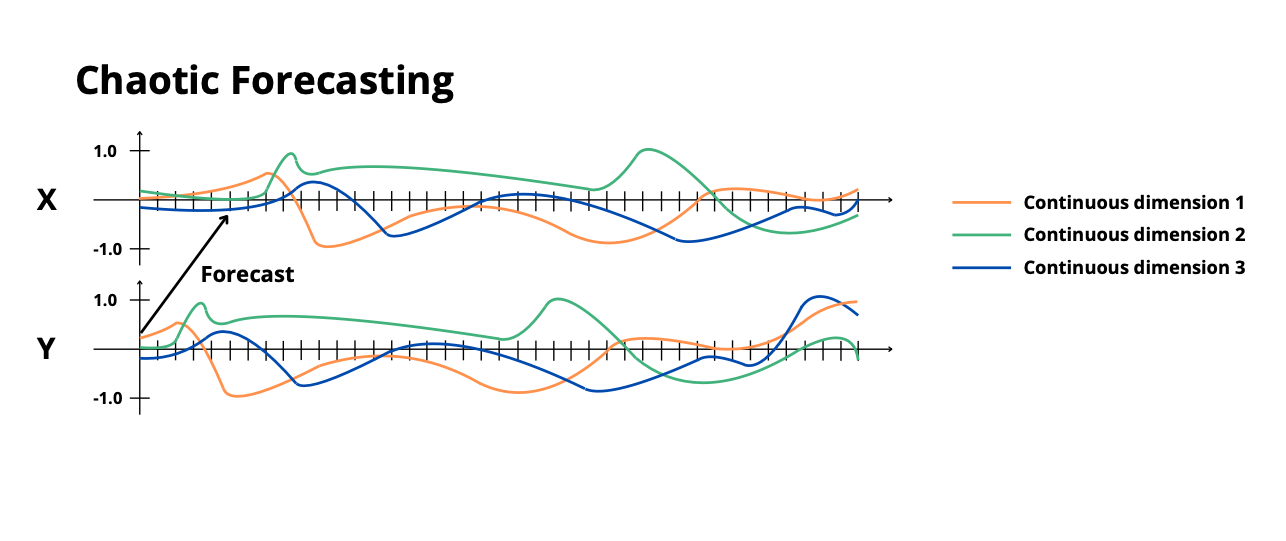
chaotic_forecasting: Forecast Lorenz system dynamics
Long-term Dependencies
-
discrete_pattern_completion: Complete masked repetitive patterns (discrete) -
continuous_pattern_completion: Complete masked repetitive patterns (continuous) -
simple_copy: Memorize and reproduce sequences after delay + trigger -
selective_copy: Memorize only marked elements and reproduce them
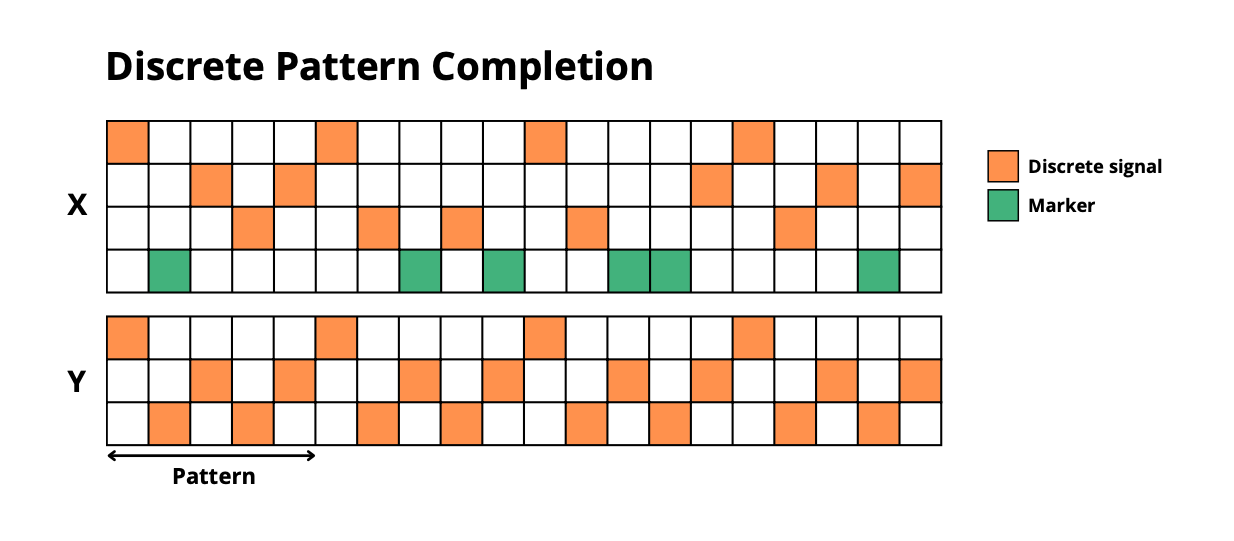
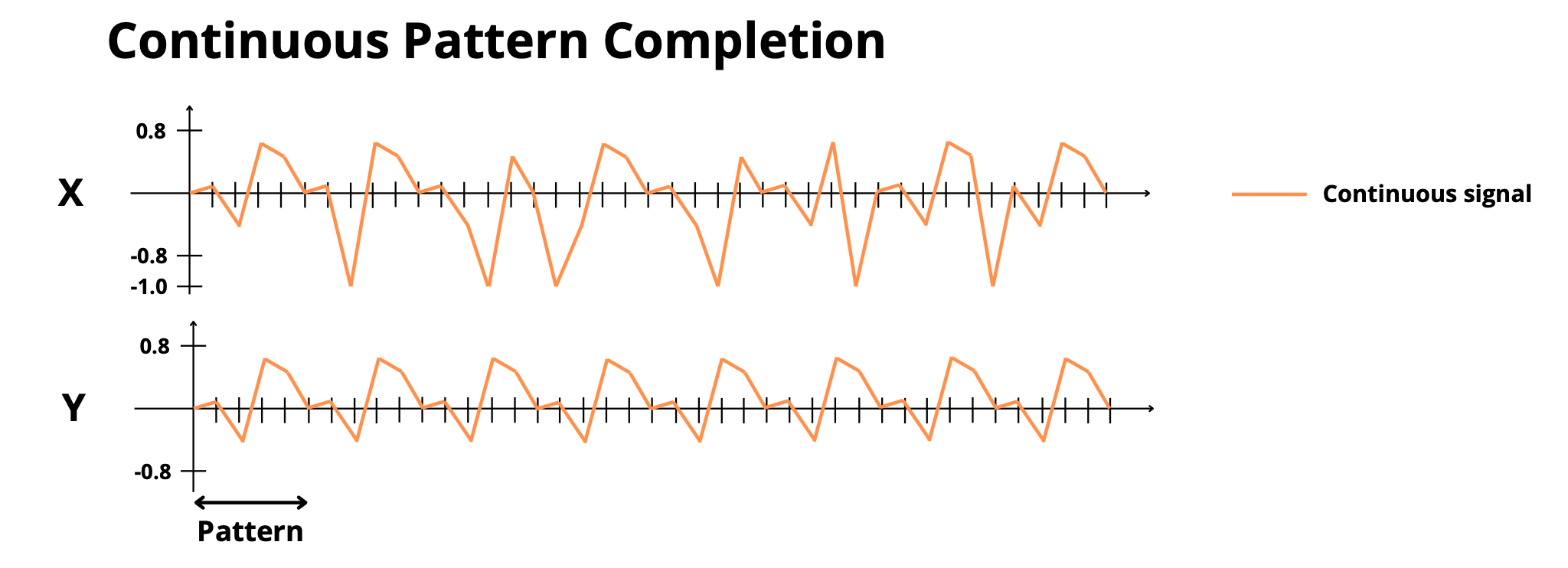
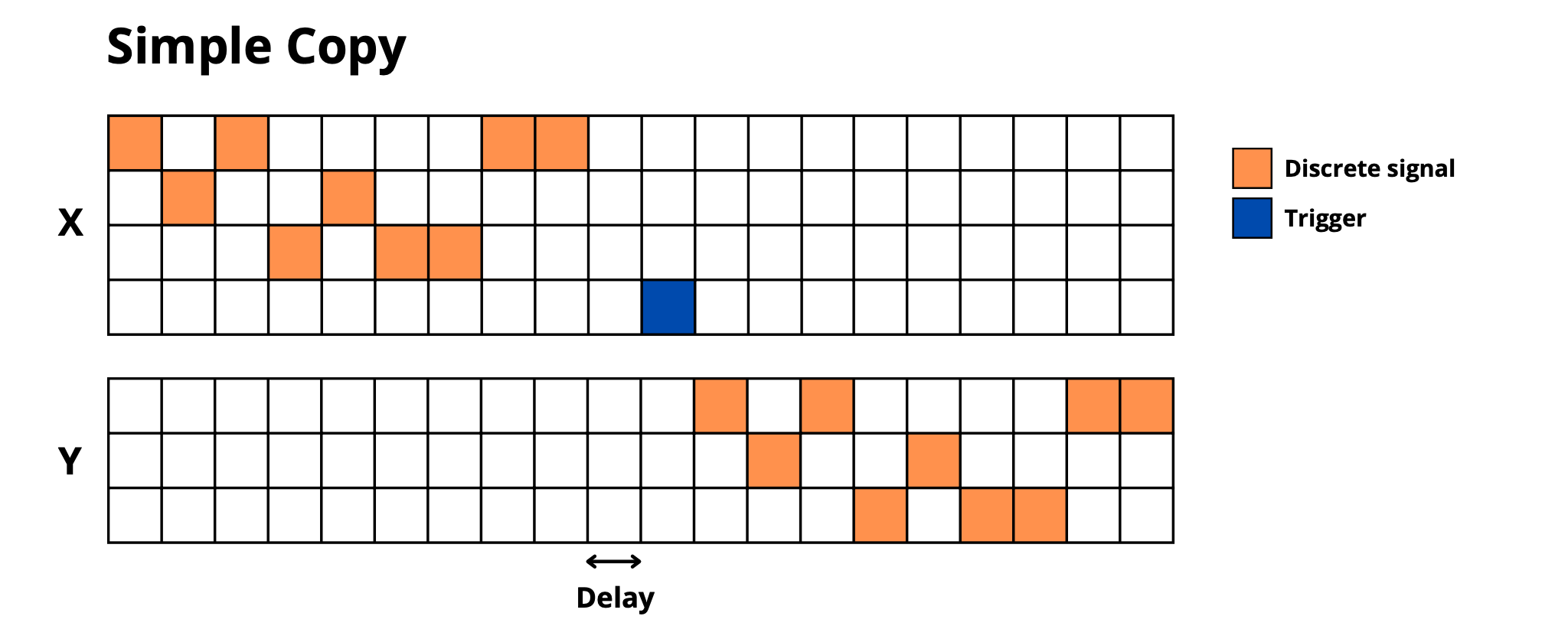
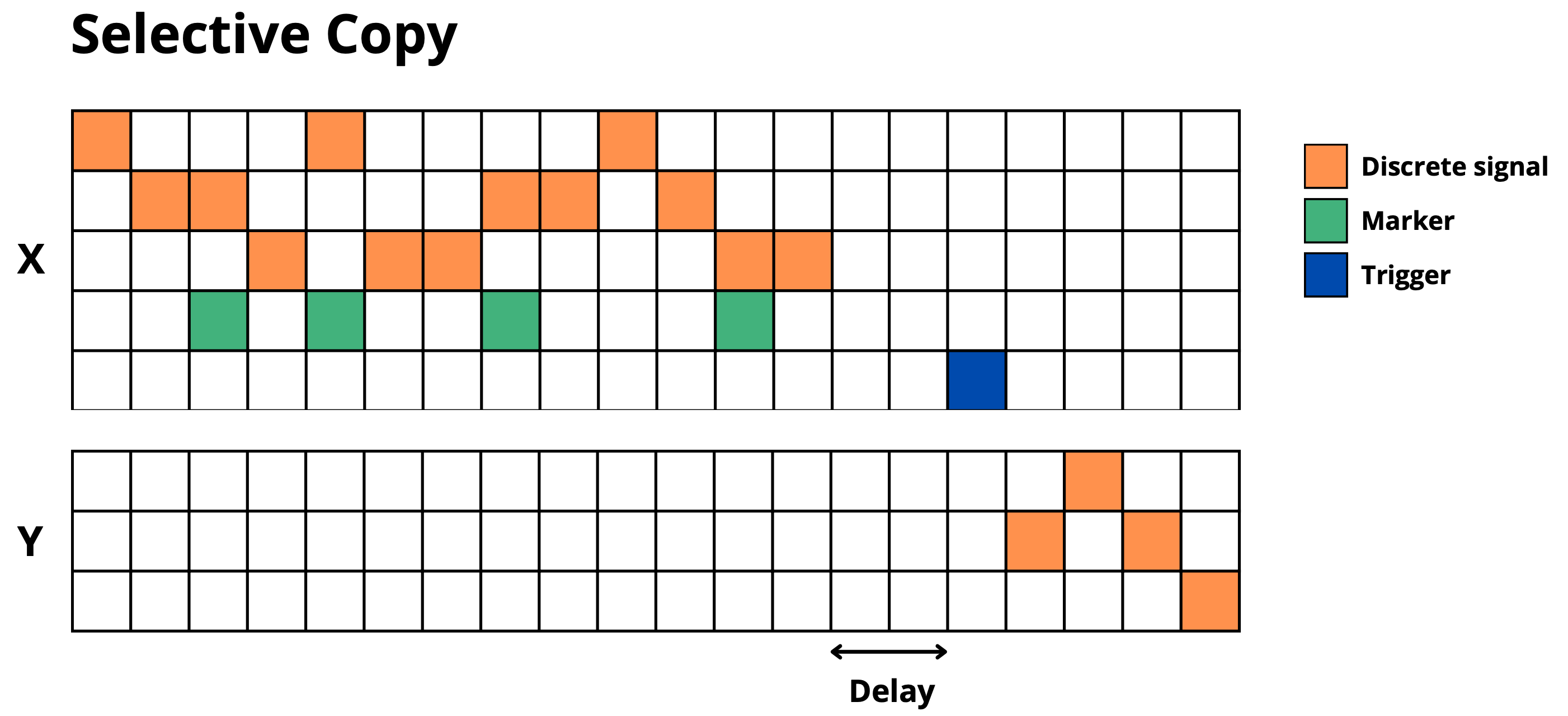
Information Manipulation
-
adding_problem: Add numbers at marked positions -
sorting_problem: Sort sequences according to given positions -
bracket_matching: Validate parentheses sequences -
cross_situation: Classify objects based on multiple attributes (color, shape, position)
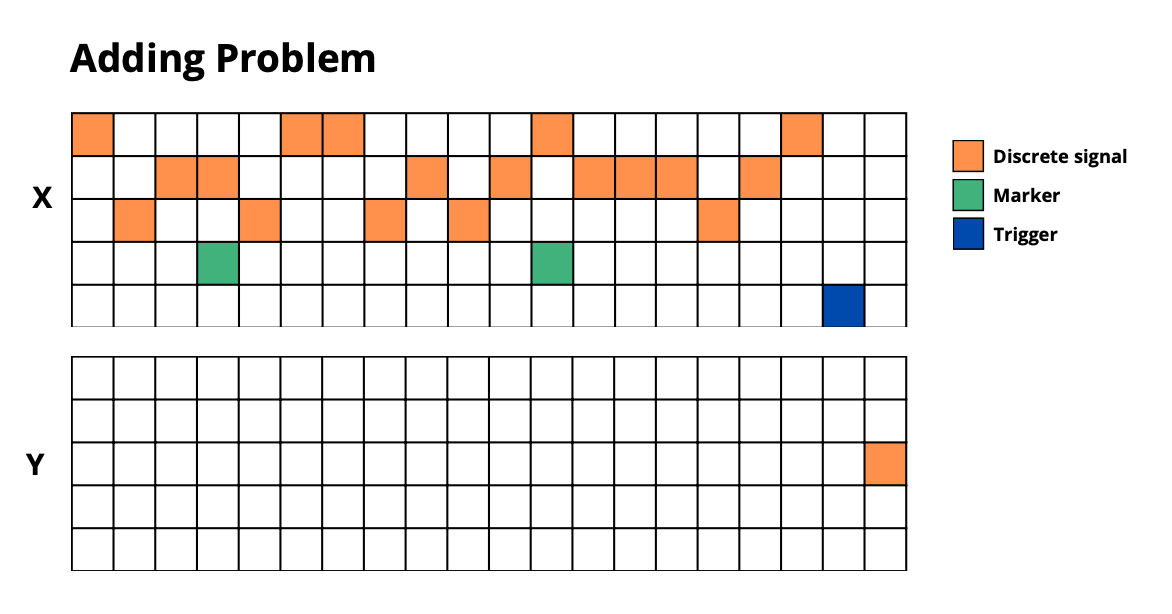
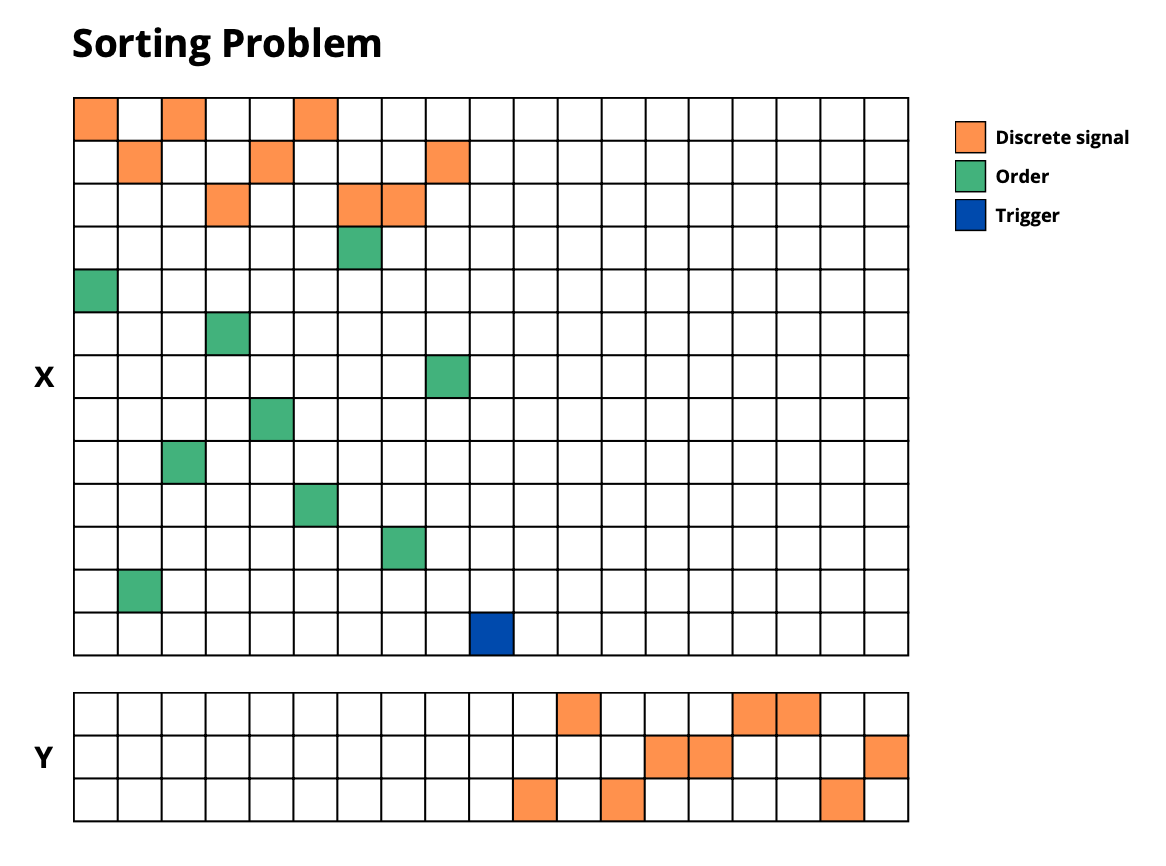
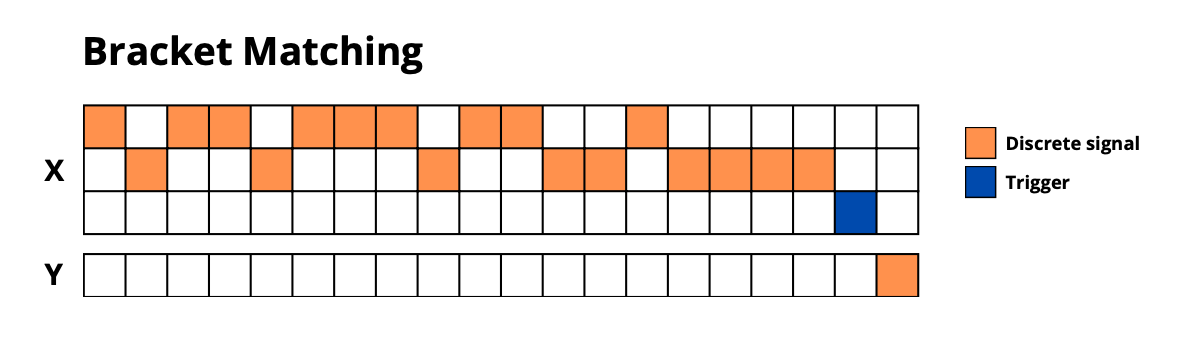
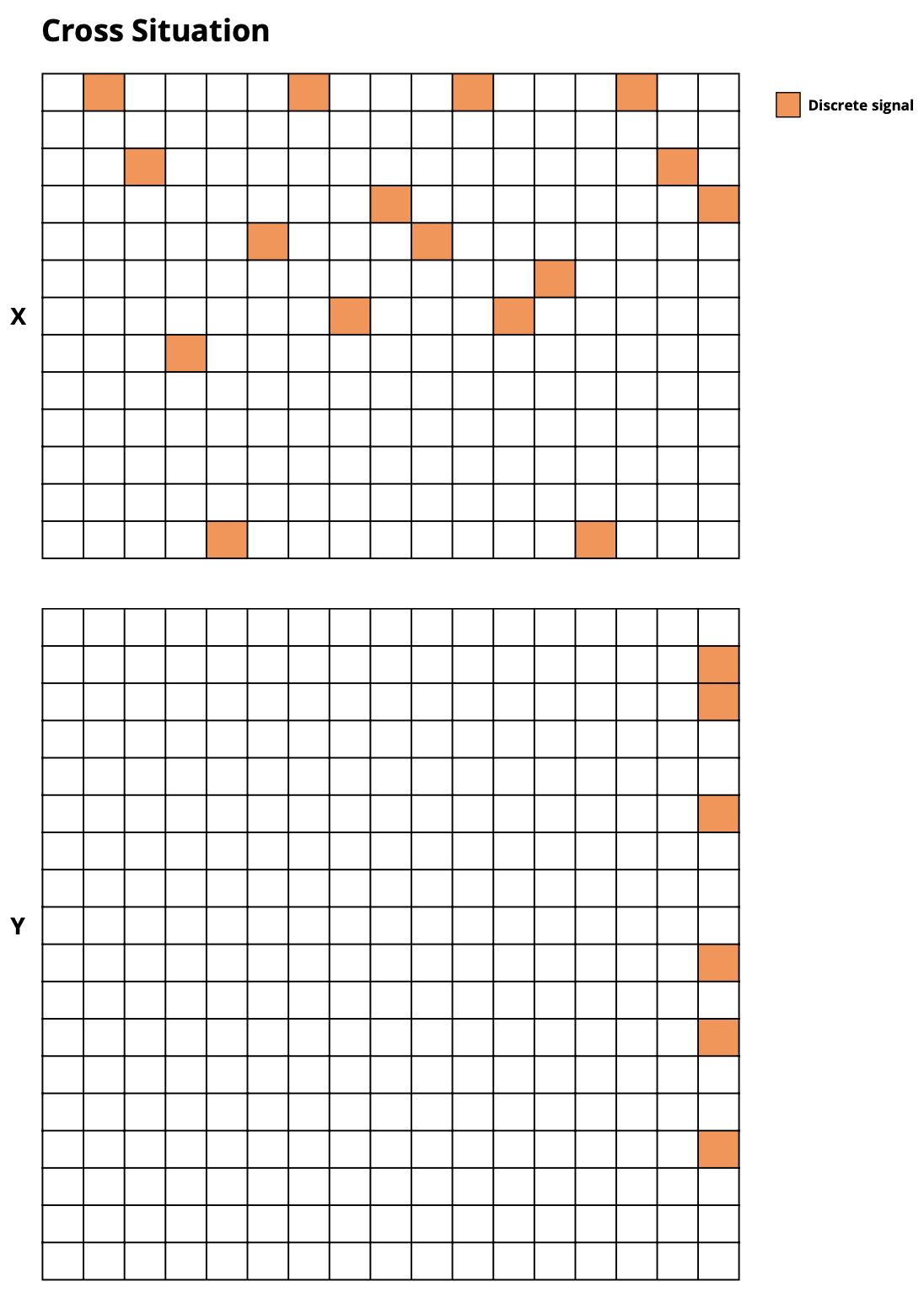
🔧 Task Configuration
Each task supports three difficulty levels (the following numbers may vary in function of the task):
Small
- Reduced sequence lengths and sample counts
- Suitable for quick experiments and debugging
- Example: 100 training samples, sequences of ~50-100 timesteps
Medium
- Realistic problem sizes
- Suitable for thorough model evaluation
- Example: 1,000 training samples, sequences of ~100-200 timesteps
Large
- Big Data configurations
- Suitable for high-performance models
- Example: 10,000 training samples, sequences of ~200-500 timesteps
For the tasks that allow it, the difficulty is also adjusted by the dimensions of input & output.
# Small configuration (fast)
task_small = sd.build_task('bracket_matching', difficulty='small', seed=0)
# Medium configuration (thorough)
task_medium = sd.build_task('bracket_matching', difficulty='medium', seed=0)
# Large configuration (comprehensive)
task_large = sd.build_task('bracket_matching', difficulty='large', seed=0)
📊 Data Format
All tasks return a standardized dictionary:
{
'X_train': np.ndarray, # Training inputs [batch, time, features]
'Y_train': np.ndarray, # Training targets [batch, time, outputs]
'T_train': np.ndarray, # Training prediction timesteps [batch, n_predictions]
'X_valid': np.ndarray, # Validation inputs
'Y_valid': np.ndarray, # Validation targets
'T_valid': np.ndarray, # Validation prediction timesteps
'X_test': np.ndarray, # Test inputs
'Y_test': np.ndarray, # Test targets
'T_test': np.ndarray, # Test prediction timesteps
'category': str # 'classification', 'multi_classification', or 'regression'
}
🎨 Example: Complete Evaluation Pipeline
import stream_dataset as sd
import numpy as np
from MyModel import MyModel
def evaluate_model_on_all_tasks(model, difficulty='small'):
"""Evaluate a model on all available tasks."""
results = {}
task_names = [
'simple_copy', 'selective_copy', 'adding_problem',
'discrete_postcasting', 'continuous_postcasting',
'discrete_pattern_completion', 'continuous_pattern_completion',
'bracket_matching', 'sorting_problem', 'cross_situation',
'sinus_forecasting', 'chaotic_forecasting'
]
for task_name in task_names:
print(f"Evaluating on {task_name}...")
# Load task
task_data = sd.build_task(task_name, difficulty=difficulty)
# Train model (simplified)
model = MyModel(...)
model.train(task_data['X_train'], task_data['Y_train'], task_data['T_train'])
# If you want your model to learn all timesteps, including the ones that are not evaluated :
# Comment the previous line and uncomment the following one
# model.train(task_data['X_train'], task_data['Y_train'])
# Predict on test set
Y_pred = model.predict(task_data['X_test'])
# Compute score
score = sd.compute_score(
Y=task_data['Y_test'],
Y_hat=Y_pred,
prediction_timesteps=task_data['T_test'],
category=task_data['category']
)
results[task_name] = score
print(f" Score: {score:.4f}")
return results
# Usage
# results = evaluate_model_on_all_tasks(your_model, difficulty='medium')
📈 Evaluation Metrics
- Classification tasks: Error rate (1 - accuracy)
- Regression tasks: Mean Squared Error (MSE)
- Multi-class classification tasks: Exact match accuracy (1 - exact match accuracy)
Lower scores indicate better performance for both metrics.
📄 License
This project is licensed under the MIT License - see the LICENSE file for details.
📚 Citation
If you use Stream Dataset in your research, please cite:
(paper in progress...)
@software{stream_dataset,
title={Stream Dataset: Sequential Task Review to Evaluate Artificial Memory},
author={Yannis Bendi-Ouis, Xavier Hinaut},
year={2025},
url={https://github.com/Naowak/stream-dataset}
}
🙏 Acknowledgments
- Inspired by classic sequence modeling datasets
- Built with NumPy and Hugging Face Datasets
📞 Support
- 🐛 Issues: GitHub Issues
- 💬 Discussions: GitHub Discussions
Stream Dataset - Advancing sequence modeling evaluation, one task at a time.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file stream_dataset-0.1.3.tar.gz.
File metadata
- Download URL: stream_dataset-0.1.3.tar.gz
- Upload date:
- Size: 678.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8de3cba1df436539cd5e0c2c4408d032658b44aa877864a1b9913c3a039b8960
|
|
| MD5 |
1ba7d5cb9e9f26d09f1ef033a66ee922
|
|
| BLAKE2b-256 |
18370c2c628ef01688b8abcb2ed4c7ba635e19cba2a92c427d497ada52b94c7c
|
File details
Details for the file stream_dataset-0.1.3-py3-none-any.whl.
File metadata
- Download URL: stream_dataset-0.1.3-py3-none-any.whl
- Upload date:
- Size: 15.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f833424878aa98244cf89a17f76abd637a27224412982b461fb13c773ecf4140
|
|
| MD5 |
a6b234b4fb1247de7d677367c5fdf242
|
|
| BLAKE2b-256 |
16e638a88ad67e3ad3b1d2258fa5377d96246605e320ecc1c50650329747b9e9
|







