Package designed to match strings by similarity

Project description




StringPairFinder is a Python package designed to simplify the process of finding similarities between strings.

Installation
pip install stringpairfinder
Computing String Similarity
import stringpairfinder as spf
spf.get_similarity("Munich", "Munchen")
>> 0.23809523809523808
Finding the Nearest String
spf.get_nearest_string(
string="Naples",
string_list=["Munchen", "Napoli", "Warszawa"]
)
>> 'Napoli'
Mapping Strings to Their Nearest Counterparts
spf.match_strings(
source_strings=["Naples", "Munich", "Warsaw"],
target_strings=["Munchen", "Napoli", "Warszawa"]
)
>> {
'Naples': 'Napoli',
'Munich': 'Munchen',
'Warsaw': 'Warszawa'
}
Evaluation
Evaluation on a dataset of 1000 observations (see notebooks/StringPairFinder vs FuzzyWuzzy.ipynb) :
- FuzzyWuzzy algorithm : 85.2 % of success rate
- StringPairFinder algorithm : 94.0 % of success rate
What is the algorithm ?
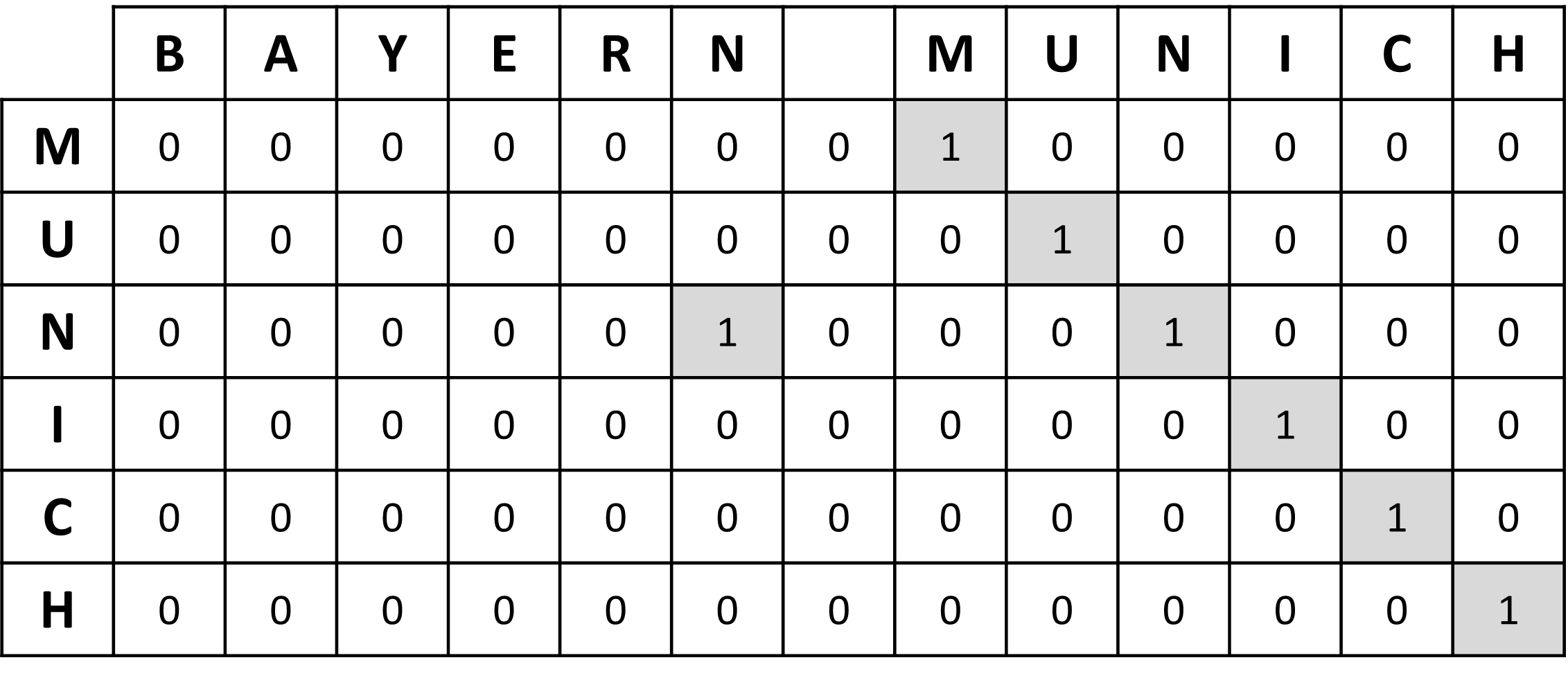
The similarity search between two strings consists of a matrix comparison of each character in those strings. Let"s assume we want to compare the strings "Munich" and "Bayern Munich".
- The first step is to construct a table $T$ containing the first string in the column and the second in the row. The value of a cell is 1 if the character in the row is the same as the one in the column, and 0 otherwise.
- The second step aims at highlighting the fact that several characters correspond consecutively. Thus, for each row $i$ and column $j$, if cell $T[i-1, j-1] > 0$, then $T[i, j]$ is twice the value of $T[i-1, j-1]$.
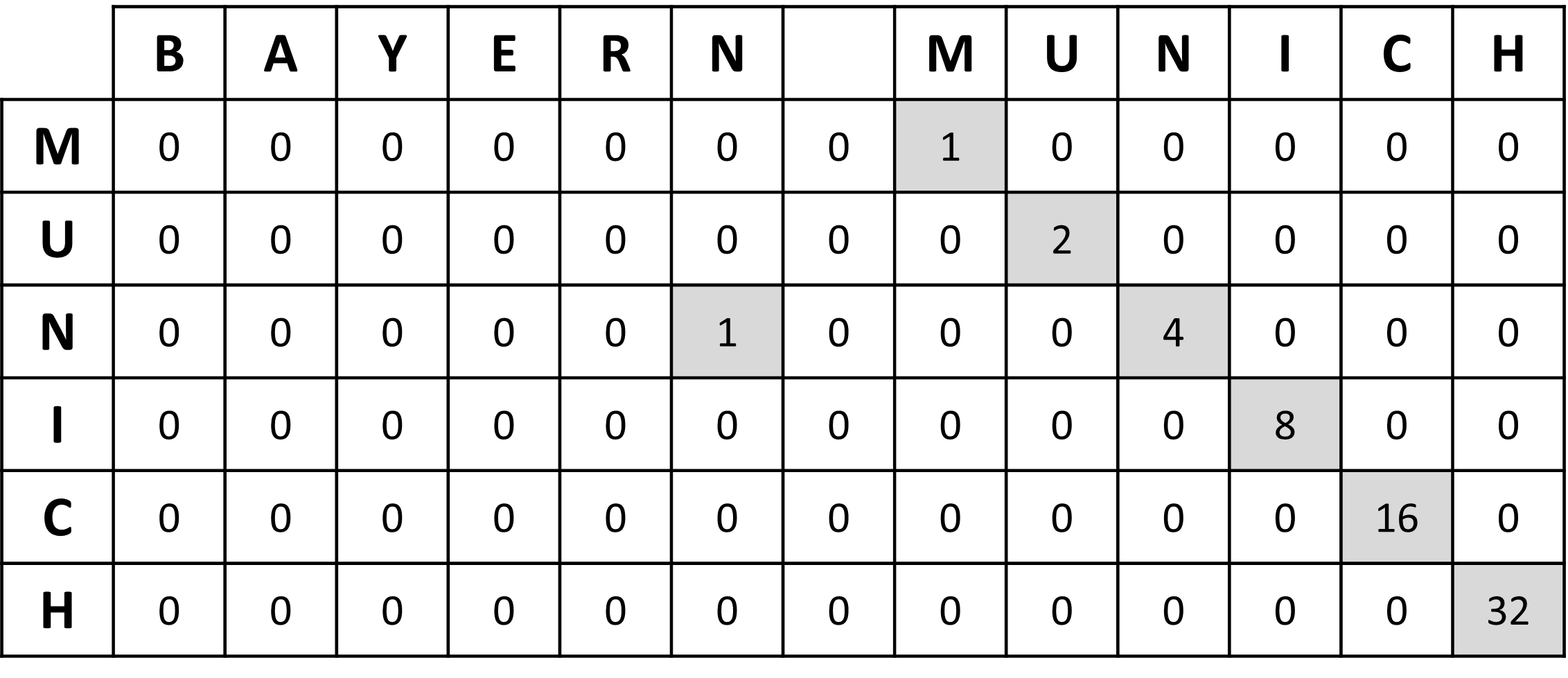
- The third step is simply to calculate the similarity score, equal to the sum of all the cells in the $T$ divided by the size of the table.
$$ Score = \frac{\sum_{i=1}^{n_{row}}\sum_{j=1}^{n_{col}} T_{i,j}}{n_{row} * n_{col}} = \frac{1+1+2+4+8+16+32}{78} \approx 0.82 $$
In this example, we obtain a similarity score of 64.
To connect the peers two by two, StringPairFinder calculates the similarity score of all (list1, list2) combinations and returns the association between each character string in list 1 with the character string in list 2 with the highest similarity score.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file stringpairfinder-2.0.0.tar.gz.
File metadata
- Download URL: stringpairfinder-2.0.0.tar.gz
- Upload date:
- Size: 4.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
22b14d5c774ed7b5b9c92d99aa51d14fec816367913cfba1d97043e07f6a732d
|
|
| MD5 |
44920304c8b8594ae5e453782d5e7bfe
|
|
| BLAKE2b-256 |
089c0f250665a3ebd1ef63ad0fc62220d831183b192c24f84efca3701eff5c25
|
File details
Details for the file stringpairfinder-2.0.0-py3-none-any.whl.
File metadata
- Download URL: stringpairfinder-2.0.0-py3-none-any.whl
- Upload date:
- Size: 5.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cb3a1ae74c27a47fbfc2abafab1fc1e6433131ec7be7fbd04238a239abb596c2
|
|
| MD5 |
adbbb8cd780a43c1d079029cfb5e5e57
|
|
| BLAKE2b-256 |
6f2b791dbe86c1ca22efad5869c35e5998fc32b16a3212edcf04e87b01148c71
|







