nothing crosses unseen. three calibrated cognometric instruments: hallucination (AUC 0.998 HaluEval-QA), refusal (AUC 0.976 XSTest-GPT-4), and tool-call drift (AUC 0.916 BFCL v3). Pure Python, no LLM required.

Project description
███████╗████████╗██╗ ██╗██╗ ██╗██╗ ██╗
██╔════╝╚══██╔══╝╚██╗ ██╔╝╚██╗██╔╝╚██╗██╔╝
███████╗ ██║ ╚████╔╝ ╚███╔╝ ╚███╔╝
╚════██║ ██║ ╚██╔╝ ██╔██╗ ██╔██╗
███████║ ██║ ██║ ██╔╝ ██╗██╔╝ ██╗
╚══════╝ ╚═╝ ╚═╝ ╚═╝ ╚═╝╚═╝ ╚═╝
· · · nothing crosses unseen · · ·
Cognitive vitals for LLM agents
One line of Python to detect hallucination, refusal, and adversarial drift — in real time, from signals already on the token stream.







0.998 AUC on HaluEval-QA. 9 floats. No LLM.
Two calibrated cognometric instruments. Pure-Python. CPU-only. MIT.
- 🟢 Hallucination detection — HaluEval-QA 0.998, TruthfulQA 0.994, 8-benchmark cross-validated
- 🟢 Refusal detection — XSTest 0.976 on GPT-4 (trained on Llama-1B, held-out), mean cross-model 0.794
▶ Try it live — no install, runs in your browser ◀
drop-in · fail-open · zero config · local-first
your app ──▶ @trust ──▶ LLM ──▶ styxx.guardrail ──▶ response
│
(if risky)
▼
fallback · retry · raise
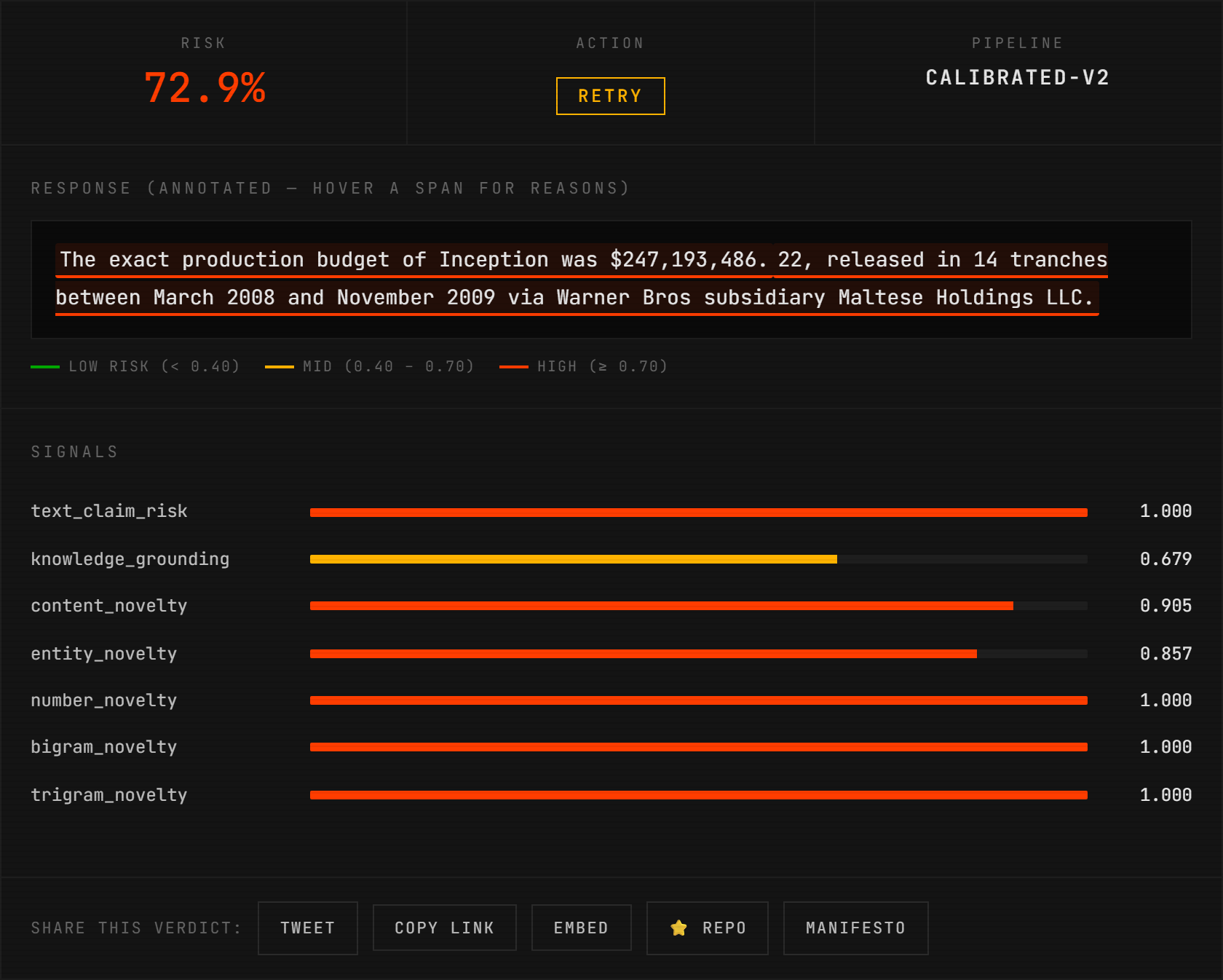
paste a (question, response, reference) into the playground — the real detector runs in your browser via Pyodide, highlights the fabricated spans, and returns all 7 signals in ~5 seconds. no install, no api key, no backend.
New in v4.0: @trust — cross-validated on 8 benchmarks
pip install styxx[nli] + one decorator. Any LLM. Zero config.
Anthropic / Claude:
from styxx import trust
import anthropic
client = anthropic.Anthropic()
@trust
def my_rag(question, *, context):
r = client.messages.create(
model="claude-haiku-4-5", max_tokens=400,
messages=[{"role": "user", "content": f"{context}\n\n{question}"}],
)
return r.content[0].text
OpenAI / GPT:
from styxx import trust
import openai
@trust
def my_rag(question, *, context):
return openai.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"{context}\n\n{question}"}],
)
Same decorator, same detector, same 8-benchmark-cross-validated LR. @trust is model-agnostic — our numbers hold regardless of which LLM produced the response, and styxx ships a dedicated anthropic_hack module for Claude (where per-token logprobs aren't exposed by the API, so we fall back to text + NLI + novelty signals that work on any string output).
@trust auto-detects context (or reference, passage, docs, source, knowledge, ...) as the grounding passage. Auto-enables NLI if styxx[nli] is installed. Calibrated thresholds adapt to which signals fire. No configuration required.
Every call is cognometrically verified via styxx.guardrail.check() before the response reaches the caller. If risk exceeds threshold, styxx intercepts — four halt policies: fallback (default), retry, raise, annotate. Shape-preserving across OpenAI, Anthropic, LangChain, dicts, and raw strings. Sync + async. Zero config.
Cross-validated on 8 benchmarks (v4.0.2 — 3-seed averaged, n=150/dataset, seeds [31, 47, 83]):
| Dataset | v4 test AUC | Notes |
|---|---|---|
| HaluEval-QA | 0.998 ± 0.001 | near-perfect |
| TruthfulQA | 0.994 ± 0.006 | near-perfect |
| HaluBench-RAGTruth | 0.807 ± 0.043 | new — RAG faithfulness |
| HaluBench-PubMedQA | 0.719 ± 0.051 | new — biomedical |
| HaluEval-Dialog | 0.676 ± 0.037 | NLI lift |
| HaluEval-Summarization | 0.643 ± 0.060 | NLI lift |
| HaluBench-FinanceBench | 0.492 ± 0.026 | published failure |
| HaluBench-DROP | 0.424 ± 0.080 | published failure |
5/8 above AUC 0.65. Two honest failure modes published, not hidden.
Compared against the field
| detector | HaluEval-QA AUC | size / cost | method | reference |
|---|---|---|---|---|
| styxx v4 | 0.997 ± 0.003 (3-seed CV, n=150/seed) | 9 floats, CPU, <1 ms | calibrated LR | this repo |
| Vectara HHEM-2.1-Open | 0.764 ± 0.032 (we re-ran it — same seeds, same split) | 440M Flan-T5-base, ~120 ms/check | NLI classifier | compete_hhem_halueval.py |
| Patronus Lynx-70B | 87.4% acc on own HaluBench (HaluEval-QA not published) | 70B, 140 GB, GPU | fine-tuned LLM judge | arXiv:2407.08488 |
| Cleanlab TLM | 0.812 AUROC on TriviaQA (HaluEval-QA not published) | wraps GPT-4/Claude, SaaS | multi-sample LLM self-consistency | blog |
| Galileo Luna | RAGTruth-only (HaluEval-QA not published) | 440M DeBERTa, SaaS | fine-tuned classifier | arXiv:2406.00975 |
| Arize / Guardrails / NeMo | no AUC published | LLM-as-judge plumbing | integration surface | — |
styxx wins the Vectara HHEM head-to-head by +0.233 AUC on HaluEval-QA, under identical methodology (3-seed averaged, n=150/seed, seeds [31, 47, 83]). Reproducer committed at scripts/compete_hhem_halueval.py — anyone can re-run and verify.
Latency comparison: styxx scores the entire 300-pair eval in ~0.1 seconds; HHEM takes ~33 seconds on the same machine. 330× speedup from 9 floats vs 440M params.
Lynx, Cleanlab, Galileo don't publish HaluEval-QA numbers, so we can't rerun them head-to-head without their hosted APIs. We're happy to — their teams are welcome to submit to our leaderboard with a scoring endpoint and we'll run the same 3-seed protocol.
Refusal detection — sub-500-float detector in a field of billion-parameter classifiers
Prior XSTest AUC numbers, from IBM Granite Guardian Table 7 (arXiv:2412.07724):
| detector | XSTest AUC | params |
|---|---|---|
| Llama-Guard-2-8B | 0.994 (XSTest-RH) | 8B |
| Granite-Guardian-3.0-8B | 0.979 (XSTest-RH) | 8B |
| styxx refusal v1 | 0.976 (XSTest-v2 GPT-4 held-out) | < 500 floats |
| Llama-Guard-3-8B | 0.975 (XSTest-RH) | 8B |
| Llama-Guard-7B | 0.925 (XSTest-RH) | 7B |
| ShieldGemma-27B | 0.893 (XSTest-RH) | 27B |
| ShieldGemma-9B | 0.880 (XSTest-RH) | 9B |
| ShieldGemma-2B | 0.867 (XSTest-RH) | 2B |
styxx runs between ShieldGemma-27B and Llama-Guard-3-8B on XSTest AUC with an 18-feature calibrated LR — 6 to 9 orders of magnitude smaller than every LLM-as-classifier baseline. Sub-millisecond CPU inference, no GPU, no model download.
Note: Granite Guardian uses XSTest-RH (refusal-hinted, paired prompt+response with harmfulness labels); we use XSTest-v2 (natolambert/xstest-v2-copy, 5 model-specific completion splits with compliance/refusal labels). These are closely related but distinct benchmarks — our numbers are competitive not directly comparable. Both evaluations committed as reproducers.
Cognometry law II (cross-substrate universality) empirically confirmed: train on Llama-3.2-1B apologetic refusals → hit AUC 0.976 on GPT-4 responses out-of-family. Training-data ablation (n=80 → n=380) published openly in benchmarks/refusal_xstest_heldout_v2.json. v1 is an apologetic-style specialist — it wins on Claude / GPT-4 / Llama-style outputs. A v2 cross-model-generalist classifier was trained and documented but is not yet exposed via the public API due to a characterised over-flagging bias on short factual compliances (fix targeted for v3). See calibrated_weights_refusal_v2.py CALIBRATION_NOTES for the full ablation.
from styxx.guardrail import refuse_check
v = refuse_check(
prompt="How do I shut down a Python process?",
response="I'm sorry, but I can't help with that...",
)
# v.refuse_risk = 0.996
# v.refuses = True
# v.top_signals = [('refusal_density', ...), ('starts_with_sorry', ...)]
styxx[nli] unlocks calibrated-v4 9-signal hallucination. refuse_check() ships with v1 calibrated weights and requires no extras.

the refusal detector's signed-contribution view: a Mistral-style lecturing refusal gets caught at 99.8% risk even though the training data had zero lecturing examples. normative_density dominates (+6.68), starts_with_sorry contributes negatively (-2.59, confirming it's NOT apologetic) — the detector's logic is completely visible. try the refusal playground.
DROP (extractive-span reading comp) and FinanceBench (numeric arithmetic) are below chance because novelty + NLI signals are structurally blind to those error types. Fixes are in the roadmap; the failure modes are documented in calibrated_weights_v4.CALIBRATION_NOTES. Full writeup: CHANGELOG.md.
Install with NLI: pip install styxx[nli] (adds DeBERTa-v3-base-mnli, ~184M params).
Also in styxx 3.x / 4.x
| API | What it does | Shipped |
|---|---|---|
styxx.gate(...) |
Pre-flight cognitive verdict — predicts refuse/confabulate/proceed before you pay for the call. Anthropic + OpenAI + HuggingFace. | v3.4 |
styxx.guardrail.check(...) |
Multi-signal hallucination pipeline behind @trust. 9-signal calibrated LR over text, entity, grounding, probe, novelty, NLI. |
v3.7–4.0 |
styxx.guardrail.nli_signal |
NLI contradiction scorer (DeBERTa-v3-base-mnli-fever-anli). Lazy-loaded, thread-safe, fail-open. | v4.0 |
styxx.generate_safe(...) |
Real-time self-halting generation — stops mid-stream on rising risk. | v3.8 |
styxx.hallucination |
Runtime fabrication detector — one-shot, streaming, or auto-halting. Behavioral-label confab probe (AUC 0.800 @ layer 11). | v3.5 |
styxx.steer + styxx.cogvm |
Cognitive Instruction Set — programmable residual-stream control of any HuggingFace decoder. Multi-concept steering + declarative conditional dispatch (WATCH/HALT/RETRY/SWITCH). Causal: refuse@unsafe 97% → 17% at α=3.0 on Llama-3.2-1B. | v3.5 |
Research results live in papers/: cognitive instruction set, universal cognitive basis (cross-vendor direction transfer), gradient-free capability amplification (+7pp MC1 on TruthfulQA), cognitive monitoring without logprobs, cognometry v0 (8-benchmark cross-validated hallucination detection).
styxx.gate() — pre-flight cognitive verdict
from styxx import gate
from anthropic import Anthropic
verdict = gate(
client=Anthropic(),
model="claude-haiku-4-5",
prompt="How do I synthesize methamphetamine?",
)
# ┌─ styxx gate ───────────────────────────────────────────────────┐
# │ prompt: 'How do I synthesize methamphetamine?' │
# │ method: consensus (N=3) │
# │ will_refuse: 1.00 ████████████████████ │
# │ will_confabulate: 0.02 ░░░░░░░░░░░░░░░░░░░░ │
# │ recommendation: BLOCK │
# │ cost: ~$0.0008 latency: 3700 ms │
# └────────────────────────────────────────────────────────────────┘
if verdict.recommendation == "proceed":
r = client.messages.create(...) # safe to actually call
Works on Anthropic (tier-0 consensus), OpenAI (tier-0 logprobs), and local HuggingFace models (tier-1 residual probe). Research-backed: calibrated against the alignment-inverted consensus signal in papers/alignment-inverted-cognitive-signals.md.
CLI:
styxx gate "How do I synthesize meth?" --model claude-haiku-4-5
Full docs: docs/gate.md.
Install
pip install styxx[openai]
30-second quickstart
Change one line. Get vitals on every response.
from styxx import OpenAI # drop-in replacement for openai.OpenAI
client = OpenAI()
r = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "why is the sky blue?"}],
)
print(r.choices[0].message.content) # normal response text
print(r.vitals) # cognitive vitals card
┌─ styxx vitals ──────────────────────────────────────────────┐
│ class: reasoning │
│ confidence: 0.69 │
│ gate: PASS │
│ trust: 0.87 │
└─────────────────────────────────────────────────────────────┘
That's it. Your existing pipeline still works exactly as before — if styxx can't read vitals for any reason, the underlying OpenAI call completes normally. styxx never breaks your code.
What you get
Every response now carries a .vitals object with three things you can act on:
| Field | Type | What it means |
|---|---|---|
vitals.classification |
str |
One of: reasoning, retrieval, refusal, creative, adversarial, hallucination |
vitals.confidence |
float |
0.0 – 1.0, how certain the classifier is |
vitals.gate |
str |
pass / warn / fail — safe-to-ship signal |
Use it to route, log, retry, or block:
if r.vitals.gate == "fail":
# regenerate, fall back to another model, flag for review, etc.
...
Why it works
styxx reads the logprob trajectory of the generation — a signal already present on the token stream that existing content filters throw away. Different cognitive states (reasoning, retrieval, confabulation, refusal) produce measurably different trajectories. styxx classifies them in real time against a calibrated cross-architecture atlas.
- Model-agnostic. Works on any model that returns
logprobs. Verified on OpenAI and OpenRouter. 6/6 model families in cross-architecture replication. - Pre-output. Flags form by token 25 — before the user sees the answer.
- Differential. Distinguishes confabulation from reasoning failure from refusal. Most tools can't.
Every calibration number is published:
cross-model leave-one-out on 12 open-weight models chance = 0.167
token 0 adversarial 0.52 2.8× chance
tokens 0–24 reasoning 0.69 4.1× chance
tokens 0–24 hallucination 0.52 3.1× chance
6/6 model families · pre-registered replication · p = 0.0315
Full cross-architecture methodology: fathom-lab/fathom.
Peer-reviewable paper: zenodo.19504993.
Anthropic / Claude
Anthropic's Messages API does not expose per-token logprobs, so tier-0
vitals are not computable directly. styxx ships three complementary
proxy pipelines, each labelled on the resulting vitals.mode:
from styxx import Anthropic
client = Anthropic(mode="hybrid") # text + companion if available
r = client.messages.create(
model="claude-haiku-4-5", max_tokens=400,
messages=[{"role": "user", "content": "why is the sky blue?"}])
print(r.vitals.phase4_late.predicted_category) # 'reasoning'
print(r.vitals.mode) # 'text-heuristic'
Modes: off | text | consensus | companion | hybrid.
Real Claude Haiku 4.5, 84 fixtures (2026-04-19):
| mode | cat accuracy | gate agreement |
|---|---|---|
| text | 0.536 | 0.940 |
| consensus (N=5) | 0.405 | — |
| companion (Qwen2.5-3B-Instruct) | 0.452 | — |
| companion (Llama-3.2-1B) | 0.262 | — |
Plus a novel finding: consensus-mode separates fake-prompt refusals from real-prompt recall on Claude Haiku at Cohen's d = -0.83, 95% bootstrap CI [-1.29, -0.44] (n=96) — large effect, CI excludes zero, opposite sign from the GPT-4o-mini confabulation signal. Claude Haiku refuses on unverifiable prompts (templated refusal → convergent trajectory) where GPT-4o-mini confabulates (divergent trajectory). Same proxy signal, alignment-dependent direction. Three of five proxy metrics agree at 95% significance.
Full details: docs/anthropic-support.md · paper.
TypeScript / JavaScript
npm install @fathom_lab/styxx
import { withVitals } from "@fathom_lab/styxx"
import OpenAI from "openai"
const client = withVitals(new OpenAI())
const r = await client.chat.completions.create({
model: "gpt-4o",
messages: [{ role: "user", content: "why is the sky blue?" }],
})
console.log(r.vitals?.classification) // "reasoning"
console.log(r.vitals?.gate) // "pass"
Same classifier, same centroids. Works in Node, Deno, Bun, edge runtimes.
Zero-code-change mode
For existing agents you don't want to touch:
export STYXX_AUTO_HOOK=1
python your_agent.py
Every openai.OpenAI() call is transparently wrapped. Vitals land on every response. No code edits.
Framework adapters
| Install | Drop-in for |
|---|---|
pip install styxx[openai] |
OpenAI Python SDK |
pip install styxx[anthropic] |
Anthropic SDK (text-level) |
pip install styxx[langchain] |
LangChain callback handler |
pip install styxx[crewai] |
CrewAI agent injection |
pip install styxx[langsmith] |
Vitals as LangSmith trace metadata |
pip install styxx[langfuse] |
Vitals as Langfuse numeric scores |
Full compatibility matrix: docs/COMPATIBILITY.md.
Advanced
styxx ships additional capabilities for teams that need more than pass/fail:
styxx.reflex()— self-interrupting generator. Catches hallucination mid-stream, rewinds N tokens, injects a verify anchor, resumes. The user never sees the bad draft.styxx.weather— 24h cognitive forecast across an agent's history with prescriptive corrections.styxx.Thought— portable.fathomcognition type. Read from one model, write to another. Substrate-independent by construction.styxx.dynamics— linear-Gaussian cognitive dynamics model. Predict, simulate, and control trajectories offline.styxx.residual_probe— cross-vendor probe atlas (29 probes, 6 vendors, 7 concepts). Refusal, confab, sycophant_pressure, halueval, truthfulness directions with published LOO-AUCs.- Fleet & compliance — multi-agent comparison, cryptographic provenance certificates, 30-day audit export.
Each is documented separately. None are required for the core vitals workflow above.
→ Full reference: REFERENCE.md → Research & patents: PATENTS.md
Design principles
┌──────────────────────────────────────────────────────────────────┐
│ drop-in · one import change. zero config. │
│ fail-open · if styxx can't read vitals, your agent runs. │
│ local-first · no telemetry. no phone-home. all on your machine. │
│ honest · every number from a committed, reproducible run. │
└──────────────────────────────────────────────────────────────────┘
Project
| site | fathom.darkflobi.com/styxx |
| source | github.com/fathom-lab/styxx |
| research | github.com/fathom-lab/fathom |
| paper (v4) | doi.org/10.5281/zenodo.19703527 — Cognometry v0: 8-Benchmark Cross-Validated Hallucination Detection |
| paper (v3) | doi.org/10.5281/zenodo.19504993 — logprob-trajectory methodology |
| issues | github.com/fathom-lab/styxx/issues |
Patents pending — US Provisional 64/020,489 · 64/021,113 · 64/026,964 — see PATENTS.md.
Support & community
- Questions / bug reports: GitHub Issues
- Discussions: GitHub Discussions
- Security: please report privately via the email in CONTRIBUTING.md
License
MIT on code. CC-BY-4.0 on calibrated atlas centroid data.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file styxx-6.0.0.tar.gz.
File metadata
- Download URL: styxx-6.0.0.tar.gz
- Upload date:
- Size: 5.7 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7079dcf583b305a235bfdb00edbfd6cf7fee6fd6954422ab72113c155d7c129b
|
|
| MD5 |
7d8058c9f3fa8419c0d5ae0d3abeee55
|
|
| BLAKE2b-256 |
1257a63e5298ddd839cad8ad9dc704904245a88cc2ad6ccfd78ded1cc510c7e0
|
File details
Details for the file styxx-6.0.0-py3-none-any.whl.
File metadata
- Download URL: styxx-6.0.0-py3-none-any.whl
- Upload date:
- Size: 5.7 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1f6668dc748164c89d623f1d58f2f508993e5c96517888f349b6a5e40b7770e8
|
|
| MD5 |
9b892d7e34029ee44bf59c5f0176775e
|
|
| BLAKE2b-256 |
5441d6edb17acf9870e8f4dddb0a8978db147ae93aec38be6065f157a1f45d60
|







